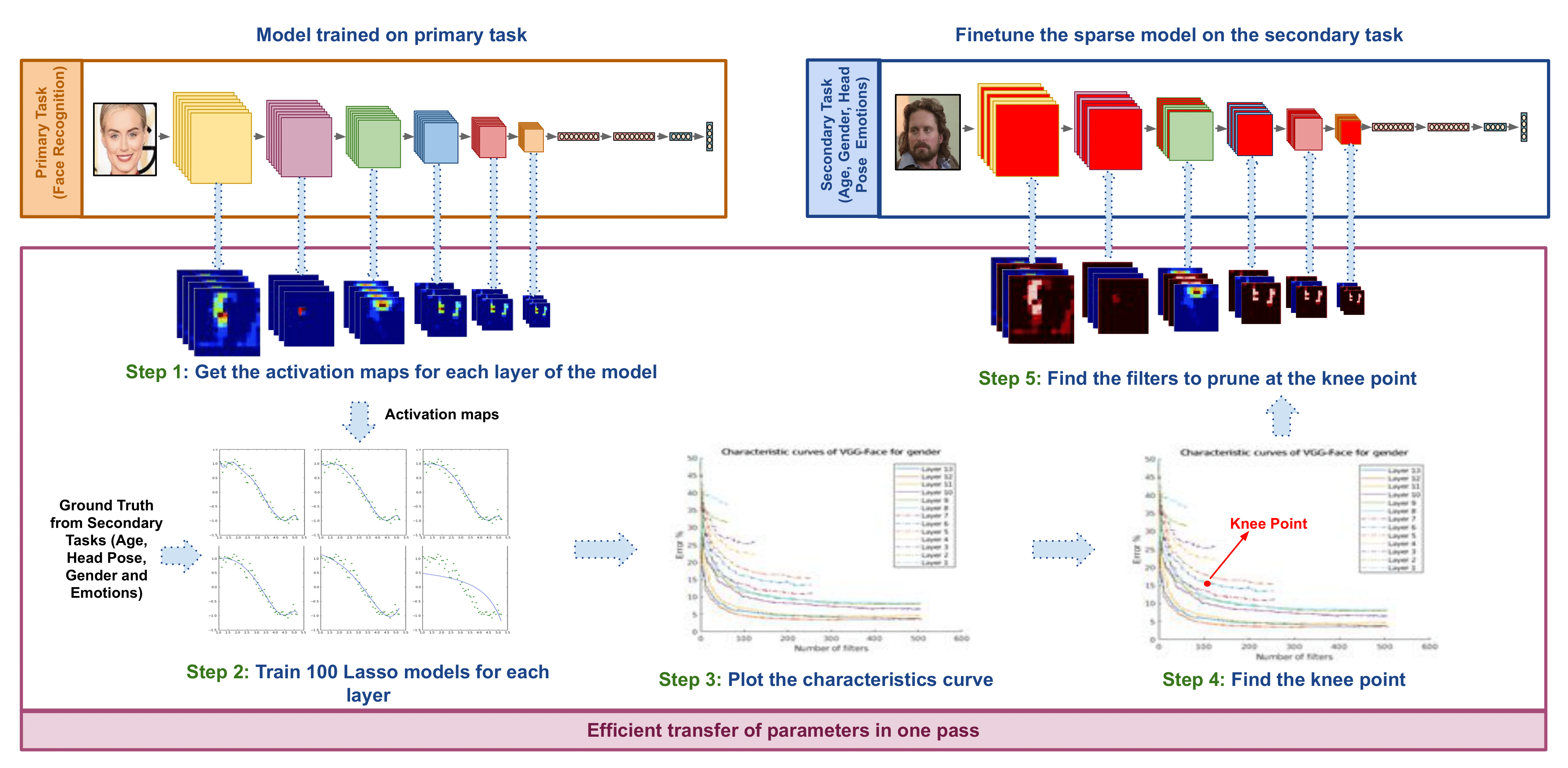
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Sindhu B Hegde* , K R Prajwal* Rudrabha Mukhopadhyay*, Vinay Namboodiri and C.V. Jawahar
IIIT Hyderabad University of Oxford Univ. of Bath
ACM-MM, 2022
[ Code ] | [ Paper ] | [ Demo Video ]
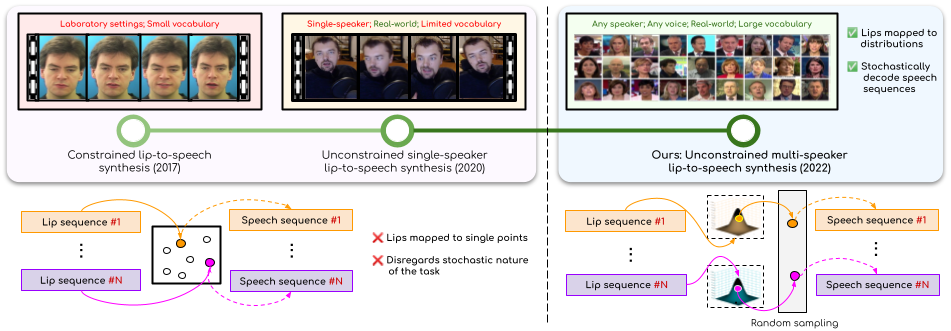
We address the problem of generating speech from silent lip videos for any speaker in the wild. Previous works train either on large amounts of data of isolated speakers or in laboratory settings with a limited vocabulary. Conversely, we can generate speech for the lip movements of arbitrary identities in any voice without any additional speaker-specific fine-tuning. Our new VAE-GAN approach allows us to learn strong audio-visual associations despite the ambiguous nature of the task.
Abstract
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works in lip-to-speech synthesis, our work (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings. The task presents a host of challenges with the key one being that many features of the desired target speech like voice, pitch and linguistic content cannot be entirely inferred from the silent face video. In order to handle these stochastic variations, we propose a new VAE-GAN architecture that learns to associate the lip and speech sequences amidst the variations. With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person. Extensive experiments on multiple datasets show that we outperform all baseline methods by a large margin. Further, our network can be fine-tuned on videos of specific identities to achieve a performance comparable to single-speaker models that are trained on 4x more data. We also conduct numerous ablation studies to analyze the effect of
different modules of our architecture. A demo video in supplementary material demonstrates several qualitative results and comparisons.
Paper

Demo
--- COMING SOON ---
Contact
- Sindhu Hegde -
This email address is being protected from spambots. You need JavaScript enabled to view it. - K R Prajwal -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Rudrabha Mukhopadhyay -
This email address is being protected from spambots. You need JavaScript enabled to view it.