Word Spotting in Silent Lip Videos
Abstract
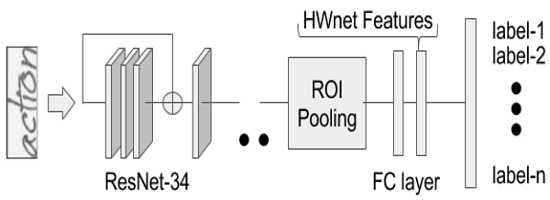
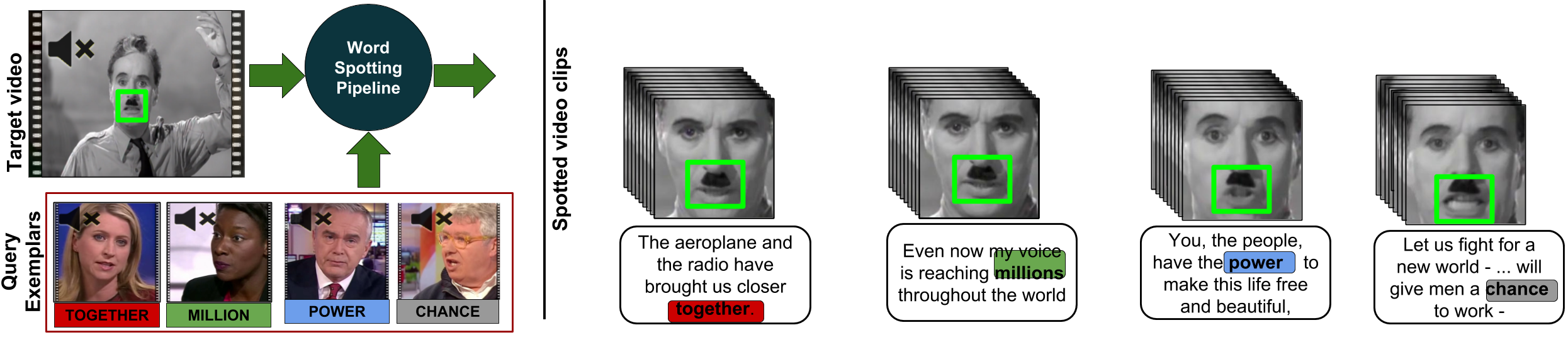
Our goal is to spot words in silent speech videos without explicitly recognizing the spoken words, where the lip motion of the speaker is clearly visible and audio is absent. Existing work in this domain has mainly focused on recognizing a fixed set of words in word-segmented lip videos, which limits the applicability of the learned model due to limited vocabulary and high dependency on the model's recognition performance.
Our contribution is two-fold:
Our contribution is two-fold:
- we develop a pipeline for recognition-free retrieval, and show its performance against recognition-based retrieval on a large-scale dataset and another set of out-of-vocabulary words.
- We introduce a query expansion technique using pseudo-relevant feedback and propose a novel re-ranking method based on maximizing the correlation between spatio-temporal landmarks of the query and the top retrieval candidates. Our word spotting method achieves 35% higher mean average precision over recognition-based method on large-scale LRW dataset. Finally, we demonstrate the application of the method by word spotting in a popular speech video "The great dictator" by Charlie Chaplin) where we show that the word retrieval can be used to understand what was spoken perhaps in the silent movies.
Related Publications
- Abhishek Jha, Vinay Namboodiri and C.V. Jawahar, Word Spotting in Silent Lip Videos, IEEE Winter Conference on Applications of Computer Vision (WACV 2018), Lake Tahoe, CA, USA, 2018. [ PDF ] [Supp] [ Code To be released Soon ] [ Models To be released soon ]
Bibtex
If you use this work or dataset, please cite :
@inproceedings{jha2018word,
title={Word Spotting in Silent Lip Videos},
author={Jha, Abhishek and Namboodiri, Vinay and Jawahar, C.~V.},
booktitle={IEEE Winter Conference on Applications of Computer Vision (WACV 2018), Lake Tahoe, CA, USA},
pages={10},
year={2018}
}
Dataset
Lip Reading in the Wild Dataset: [ External Link ]
Grid Corpus: [ External Link ]
Charlie Chaplin, The Great Dictator speech [ Youtube ]