Bridging the Gap in Resource for Offline English Handwritten Text Recognition
Title: Bridging the Gap in Resource for Offline English Handwritten Text Recognition
Authors : Ajoy Mondal, Krishna Tulsyan and C V Jawahar
Abstract
The practical applications of Handwritten Text Recognition (HTR) have flour-
ished with many successful commercial APIs, solutions, and diverse use cases. Despite the
availability of numerous industrial solutions, academic research in HTR, particularly for En-
glish, has been hindered by the scarcity of publicly accessible data. To bridge this gap, this
paper introduces IIIT-HW-English-Word, a large and diverse collection of offline handwritten
English documents. This dataset comprises unconstrained camera-captured images featuring
20,800 handwritten documents crafted by 1,215 writers. Within this dataset, covering 757,830
words, we identify 174,701 unique words encompassing a variety of content types, such as al-
phabetic, numeric, and stop-words. We also establish a baseline for the proposed dataset,
facilitating evaluation and benchmarking, explicitly focusing on word recognition tasks. Our
findings suggest that our dataset can effectively serve as a training source to enhance per-
formance on respective datasets. The code, dataset, and benchmark results are available
at https://cvit.iiit.ac.in/usodi/bgroehtr.php
Keywords: Handwritten text recognition, English, offline, unconstrained, camera-captured,
word recognition, and benchmark.
IIIT-HW-English-Word Dataset
From an extensive English text corpus1 , a curated compilation of 20,800 text paragraphs has been meticulously crafted. Each paragraph receives a unique ID and is constrained to a maximum of 50 words. Users worldwide who are proficient in English reading and writing are assigned up to 30 paragraphs to transcribe onto standard A4-sized pages, allowing unrestrained and creatively expressive writing. Following this, writers are invited to scan the written pages using any scanning app or capture images using a mobile camera. With the involvement of over 1,215 writers, we collect a diverse set of 20,800 handwritten document pages, each page being annotated in a bounding box and text transcript at word level on a page. In Fig.2, a sample annotation is showcased. Fig.2(a) illustrates the ground truth bounding boxes along with their corresponding text transcriptions, (b) displays the actual text sequences, and (c) reveals how the ground truth information is stored in JSON format.
After creating a corpus, we need effective and efficient methods to access the dataset. The recognizers may require the data in a specific format. Thus, a large dataset calls for a standard representation independent of the script. With the generation of extensive data, there is a need for an efficient access mechanism. The data should be organized and stored in a structured way for efficient access. A standard is required to ensure the ease of access by a spectrum of communities that may need the data. JSON provides an efficient method of data storage. It is easy to write applications on a standard dataset. Even updation and changes to the data can be done quickly in a JSON storage standard. All communities of the world accept JSON for data representation. For a handwritten page or document, a JSON contains word bounding boxes and their corresponding textual transcriptions. A set of standard application program interfaces (APIs) are required for adequate access to the datasets. The annotation data (the text and word image) is required for the development and performance evaluation of recognizers.

Fig. 2. Showcases a single annotated handwritten document page alongside its standard representation. In (a), a single annotated page from our dataset is depicted. (b) Displays the actual text sequence considered as the ground truth. Finally, (c) represents the content encapsulated within the JSON file.
Dataset Feature and Statistics
Diversity: As the handwritten document pages are contributed by individuals spanning various age groups, educational backgrounds, and professional experiences under unconstrained settings across India, the resulting collection is characterized by its diversity. The process of capturing these handwritten document pages using a mobile camera under unconstrained settings introduces several challenges, encompassing (i) varying illumination, (ii) shadows, (iii) extensive unwanted background, (iv) presence of irrelevant background text, (v) fluctuations in orientation, vi) low resolution, and (vii) skewed page alignment. A few sample handwritten images captured under unconstrained settings are depicted in Fig. 3. Additionally, we provide several sample word level images from our dataset in Fig.4; a diverse range of words is depicted, showcasing variations in style, imaging, quality, and other aspects.
Page Image Resolution Distribution: Writers utilize their smartphone cameras to capture images of handwritten document pages, leading to variations in the resolution of the captured page images. Acknowledging that high-resolution document images offer clear text content, facilitate

Fig. 3. Showcases a single annotated handwritten document page alongside its standard representation. In (a), a single annotated page from our dataset is depicted. (b) Displays the actual text sequence considered as the ground truth. Finally, (c) represents the content encapsulated within the JSON file.
effective model training, and yield superior performance during testing is crucial. Including page images with diverse resolutions introduces variability in content visibility, contributing to the ro- bustness of the model. Fig. 5(a) displays the distribution of resolutions in page images, showcasing a substantial number of images ranging from 2500 × 1500 to 4000 × 3000. This visualization offers insights into the dataset’s inherent variability. This diversity in resolution further enhances the adaptability and generalization capabilities of the model.
Word Level Image Resolution Distribution: The diversity in both the text content and the individual writers contributes to variations in the resolution of handwritten words. This diversity in word image resolution plays a crucial role in enhancing the model’s generalization capabilities. Fig. 5(b) provides a visual representation of the distribution of resolutions in word level images, showcasing the range of variability present in the dataset. Most word images have a height-to-width ratio between 0.1 and 0.25, resulting in word images having various resolution. Including words with varying resolutions enriches the dataset, enabling the model to adapt to a broader spectrum of visual characteristics and improving its performance across different writing styles and conditions.
Text Distribution: Within the compilation of 20,800 document page images, 757,830 instances of words have been identified, covering a spectrum of alphabetic, numeric, stop-words, and text featur- ing combinations of special symbols, alphabets, and numeric characters. Among these occurrences,
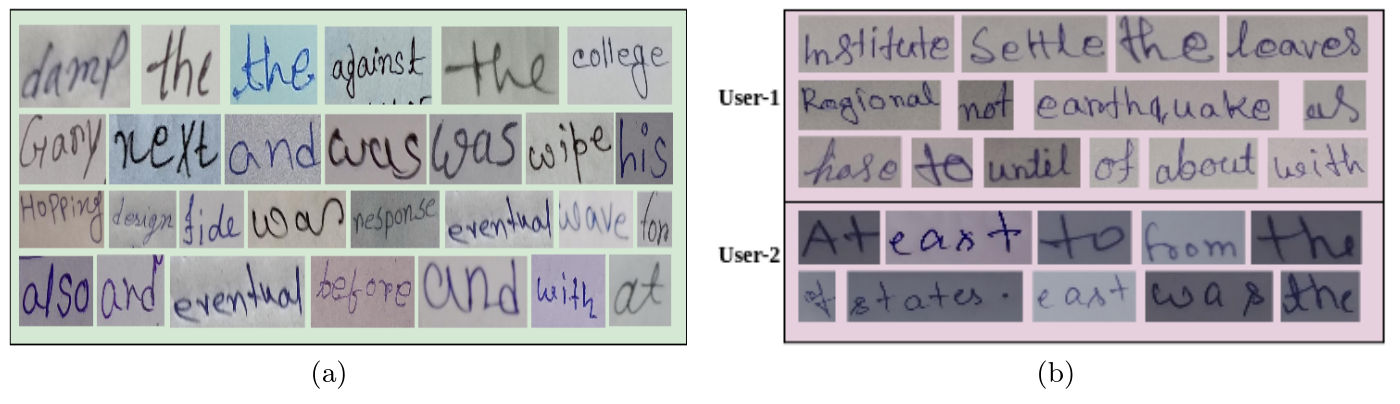
Fig. 4. A few examples of word level images from our dataset: (a) showcases sample word level images from all users, while (b) presents explicitly sample word level images from just two users, namely, user-1 and user-2.
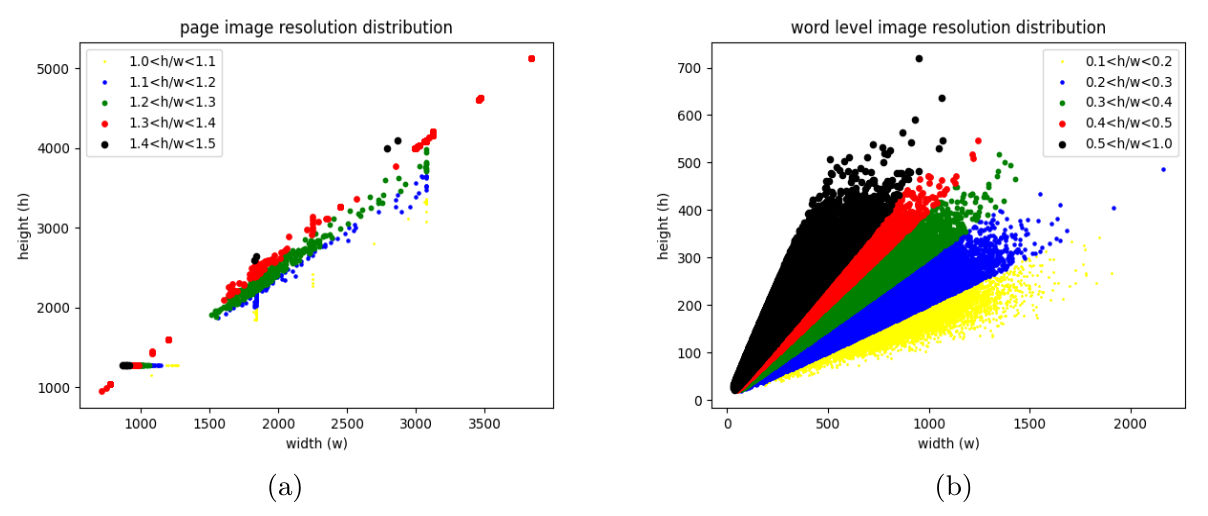
Fig. 5. Left Image: page image resolution distribution and Right Image: word level image resolution distri- bution. For page images, the majority exhibit a height-to-width ratio ranging from 1.29 to 1.33. Conversely, most word images have a height-to-width ratio between 0.1 and 0.25.
174,701 are deemed unique, encompassing alphabetic, numeric, stop-word, and other categories. A more detailed breakdown of these 174,701 unique words reveals that 66,324 are uniquely alphabetic, 97,916 are uniquely numeric, 137 are uniquely stop-words, and the remaining 10,324 fall into other categories. On average, each page image contains approximately 37 instances of words. Fig. 6 visu- ally presents the word cloud distribution of unique alphabetic words in the dataset. The word ‘also’ is most occurring. While ‘one’, ‘first’, ‘people’, ‘however’ are frequently occurring words. Visualize the distribution of the dataset’s top 70 most frequently occurring alphabetic words using Fig. 7. Notably, words such as ‘also’, ‘one’, ‘first’, ‘people’, ‘however’, ‘time’, and ‘many’ appear more than 20,000 times each.2
Writer Characteristics: Globally, 1,215 contributors have actively participated in curating hand- written documents, resulting in a diverse dataset encompassing various handwriting styles, camera

Fig. 6. Visualize the distribution of unique alphabetic words in the dataset through word clouds. It depicts the distribution of all unique alphabetic words in our dataset. The x-axis illustrates each unique word, while the y-axis represents their occurrence on a logarithmic scale.
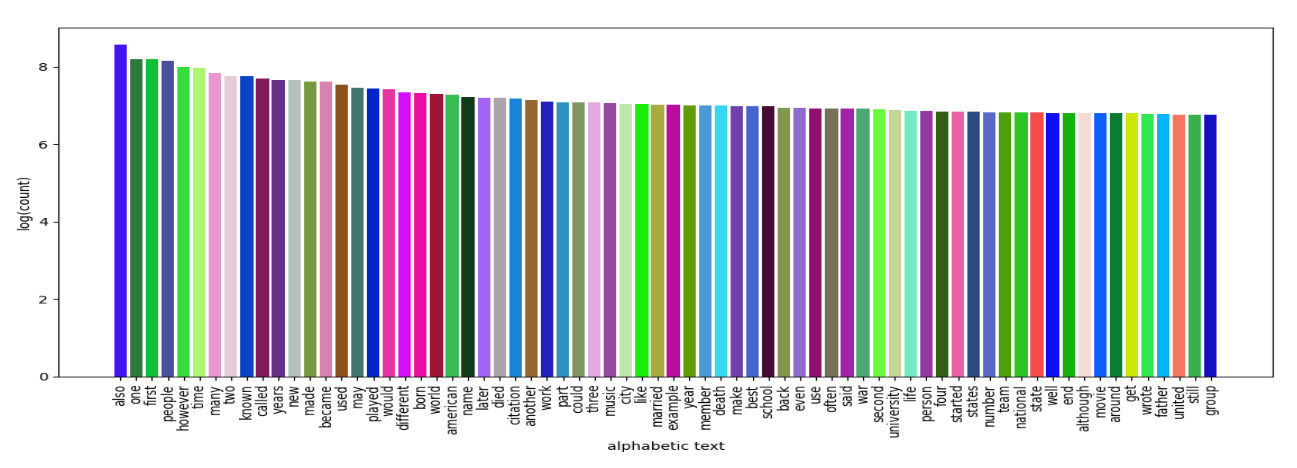
Fig. 7. Presents the frequency distribution of the most common 70 words within the dataset through visualizations. It illustrates the distribution of the top 70 common alphabetic words while plotting.
specifications, scanning methods, and more. The statistical distribution of writers is illustrated in Fig. 8(a), where it is revealed that out of the 1,215 contributors, 972 are female writers, and 243 are male writers. Within the male writers, 7 are identified as left-handed, while 236 are right-handed. Among the female contributors, 25 are left-handed, and the majority, specifically 947, are right- handed. Further demographic details, such as age distribution, are presented in Fig. 8(b). Notably, a significant portion of the contributors falls within the age range of 20 to 40.
Dataset Splits: To furnish an extensive training dataset for deep learning models, our dataset has been partitioned into 521,298 word level images for training, 66,566 word level images for validation, and 169,966 word level images for testing. It will ensure that the models are trained on a large and diverse dataset and will help to improve their accuracy and performance.
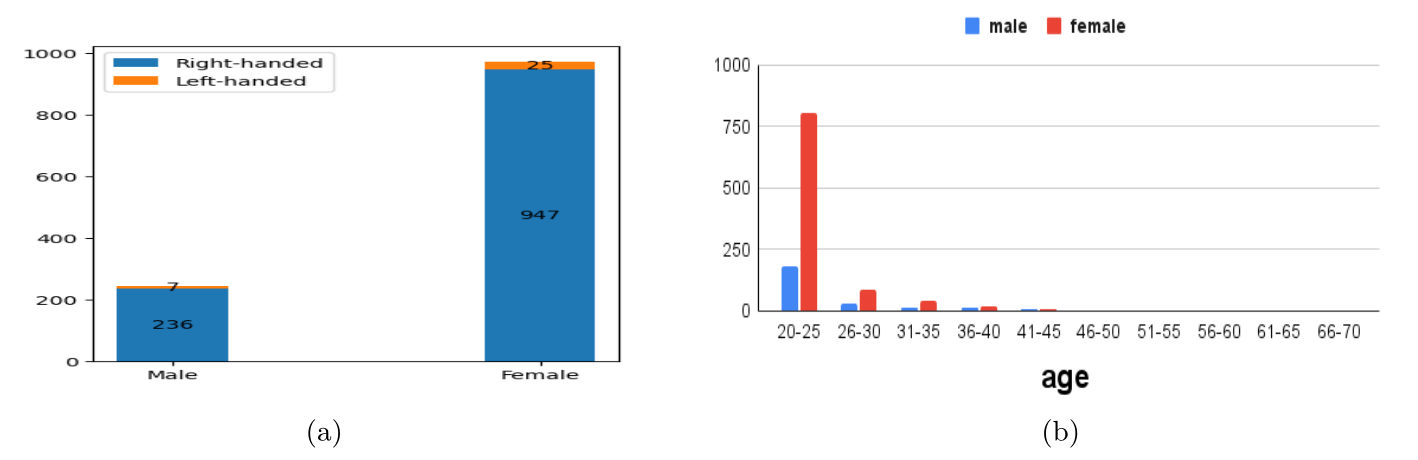
Fig. 8. The statistics provide insights into the demographics of writers collecting handwritten documents. Sub-figure (a) presents data on the distribution of left and right-handed writers among males and females. Sub-figure (b) showcases the demographic distribution of writers categorized by age groups.
Results
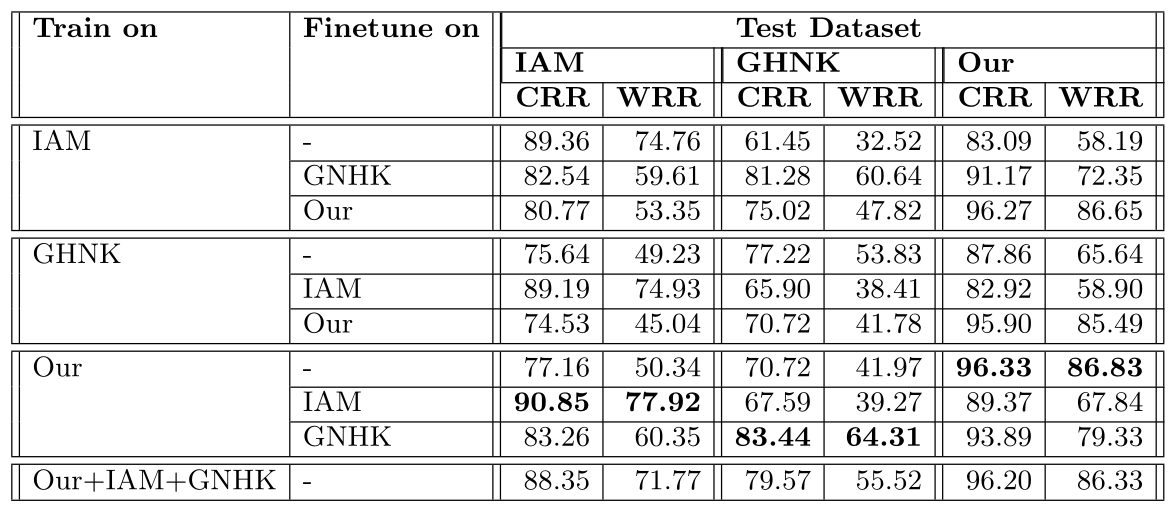
Table 3. Quantitative results on different English handwritten text recognition datasets. While model pre- trained with our dataset and fine-tuned with respective datasets, the model consistently achieves optimal performance on those respective datasets. The best results are highlighted in bold text.
Link to the Download: [ Dataset ] , [ Code ] & [ pdf ]
Publication
- Ajoy Mondal, Krishna Tulsyan and C V Jawahar , Bridging the Gap in Resource for Offline English Handwritten Text Recognition , In Proceeding of International Conference on Document Analysis and Recognition 2024.
Bibtex
@inproceedings{mondal2024bridging,
title={Bridging the Gap in Resource for Offline English Handwritten Text Recognition},
author={Mondal, Ajoy and Tulsyan, Krishna and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={413--428},
year={2024},
organization={Springer}
}