Towards Deployable OCR Models for Indic Languages
Title: Towards Deployable OCR Models for Indic Languages
Authors : Minesh Mathew, Ajoy Mondal, and C V Jawahar
Abstract
The difficulty of reliably extracting characters had delayed the character recognition solutions (or OCRs) in Indian languages. Contemporary research in Indian language text recognition has shifted towards recognizing text in word or line images without requiring sub-word segmentation, leveraging Connectionist Temporal Classification (CTC) for modeling unsegmented sequences. The next challenge is the lack of public data for all these languages. And there is an immediate need to lower the entry barrier for startups or solution providers. With this in mind, (i) we introduce Mozhi dataset, a novel public dataset comprising over 1.2 million annotated word images (equivalent to approximately 120 thousand text line images) across 13 languages. (ii) We conduct a comprehensive empirical analysis of various neural network models employing CTC across 13 Indian languages. (iii) We also provide APIs for our OCR models and web-based applications that integrate these APIs to digitize Indic printed documents. We compare our model’s performance with popular publicly available OCR tools for end-to-end document image recognition. Our model out performs these OCR engines in 8 out of 13 languages. The code, trained models, and dataset are available at https://cvit.iiit.ac.in/usodi/tdocrmil.php.
Keywords: Printed text, Indic OCR, Indian languages, CRNN, CTC, text recognition, APIs, web-based application.
Mozhi Dataset
To our knowledge, no extensive public datasets are available for printed text recognition in Indian languages. Early studies often utilized datasets with cropped characters or isolated symbols for character classification. Later research relied on either internal datasets or large-scale synthetically generated samples for word or line level annotations. While recent efforts have introduced public datasets for Hindi and Urdu, they typically contain a limited number of samples intended solely for model evaluation. However, due to variations in training data among these studies, comparing methods can be challenging. To address the scarcity of annotated data for training printed text recognition models in Indian languages, we introduce the Mozhi dataset. This public dataset encompasses both line and word level annotations for all 13 languages examined in this study. It includes cropped line images, corresponding ground truth text annotations for all languages, and word images and ground truths for all languages except Urdu. With 1.2 million word annotations (approximately 100,000 words per language), it is the largest public dataset of real word images for text recognition in Indian languages. For each language, the line level data is divided randomly into training, validation, and test splits in an 80:10:10 ratio, with words cropped from line images forming corresponding splits for training, validation, and testing. Table 1 shows statistics of Mozhi.
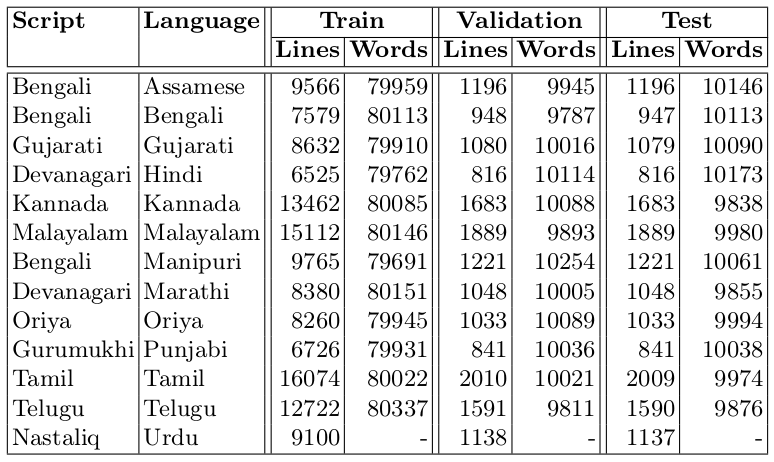
Table 1. Statistics for the new Mozhi dataset, a public resource for recognizing printed text in cropped words and lines, reveal over 1.2 million annotated words in total. Notably, only cropped lines are annotated for Urdu.
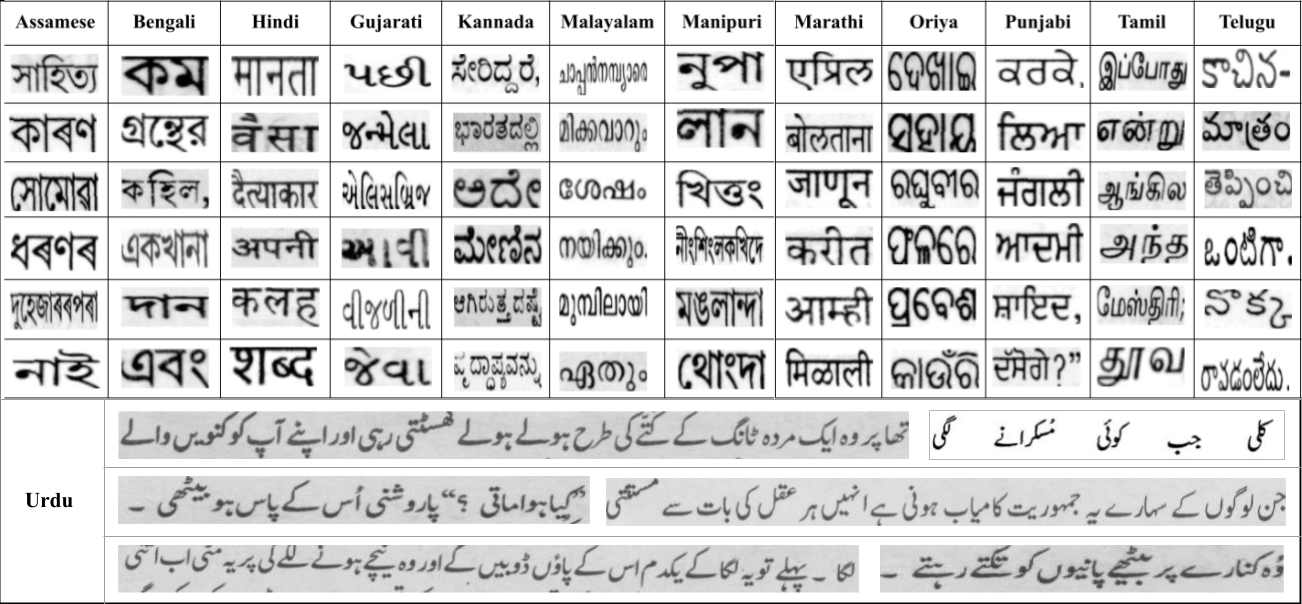
Figure 1. A few sample of word level images from our Mozhi dataset.
Experiments and Results
Evaluating CRNN on Test Set of Mozhi
Table 2 presents obtained results for word and line recognition on test set.
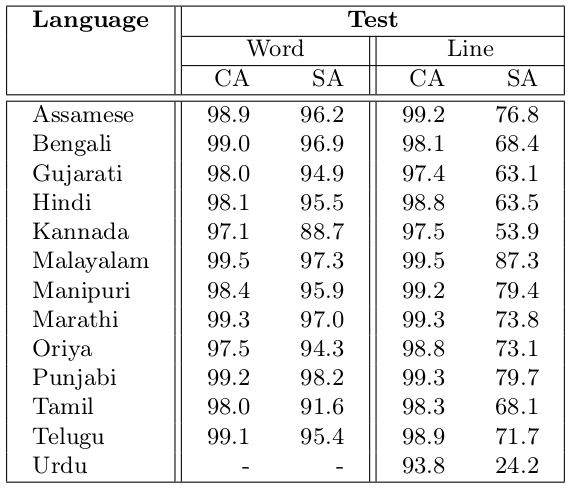
Table 2. CRNN evaluation on test set of Mozhi dataset. For each language, we train both word and line level CRNN models on the respective train split of the Mozhi dataset.
Page Level OCR Evaluation
In page level OCR, the goal is to transcribe the text within a document image by segmenting it into lines or words and then recognizing the text at the word or line level. Our focus lies solely on text recognition, excluding layout analysis and reading order identification. To construct an end-to-end page OCR pipeline, we combine existing text detection methods with our CRNN models for recognition. Transcriptions from individual segments are arranged in the detected reading order. We evaluate the end-to-end pipeline by using gold standard detection to establish an upper bound on our CRNN model’s performance. Additionally, we compare our OCR results with two public OCR tools: Tesseract and Google Cloud Vision OCR. Results from all end-to-end evaluations are summarized in Table 3. In Figure 2, visual results at the page level using Tesseract, Google OCR, and our approach are depicted. Panel (a) presents the original document image, while panels (b) to (e) display the ground truth and the predicted text by Tesseract, Google OCR, and our approach, respectively. Wrongly recognized texts are high lighted in red. This figure emphasizes that our approach outperforms existing OCR tools in producing accurate text outputs.
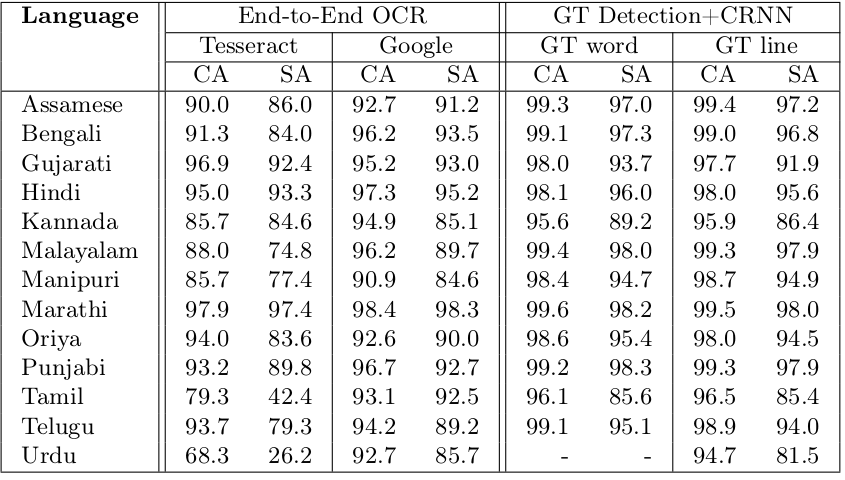
Table 3. Performance of our page OCR pipelines compared to other public OCR tools. In this setting, we evaluate text recognition in an end-to-end manner on the test split of our dataset. Since the focus of this work is on text recognition, for end-to-end settings, for text detection, gold standard word/line bounding boxes are used. Under ‘End-to-End OCR’ we show results of Tesseract and Google Cloud Vision OCR. Given a document image, these tools output a transcription of the page along with the bounding boxes of the lines and words detected. Under ‘GT Detection+CRNN’, we show results of an end-to-end pipeline where gold standard word and line detection are used. For instance, ’GT Word’ means we used ground truth (GT) word bounding boxes and the CRNN model trained for recognizing words, for that particular language. Bold value indicates the best result.

Figure 2. Displays qualitative results at the page level using Tesseract, Google OCR, and our method on a Hindi document image. For optimal viewing, zoom in. (a) original document image, (b) ground truth textual transcription, (c) predicted text by Tesseract, (d) predicted text by Google OCR, and (e) predicted text by our approach.
Use Cases
We leverage our OCR APIs for various significant applications. Notable examples include the pages of the Punjab Vidhan Sabha, Loksabha records, and Telugu Upanishads. These digitization efforts enable easier access, preservation, and analysis of these valuable texts. The output and effectiveness of our OCR technology in these diverse use cases are illustrated in Figure 3. These applications showcase the versatility and reliability of our OCR APIs in handling different scripts and document types, ensuring high accuracy and efficiency.

Figure 3. Illustrates use cases for the digitization of Loksabha records and Telugu Upanishad pages. (a) and (b) display cropped regions from the original images of Loksabha and Upanishad documents, respectively. Panels (c) and (d) present the corresponding text outputs generated using our OCR APIs.
Download Dataset
Train
[Assamese ] , [ Bengali ] , [ Gujarati ] , [ Hindi ] , [Kannada ] , [ Malayalam ] , [ Manipuri ] , [Marathi ] , [ Oriya ] , [Punjabi ] , [ Tamil ] , [ Telugu ], [Urdu ]
Validation
[Assamese ] , [ Bengali ] , [ Gujarati ] , [ Hindi ] , [Kannada ] , [ Malayalam ] , [ Manipuri ] , [Marathi ] , [ Oriya ] , [Punjabi ] , [ Tamil ] , [ Telugu ], [ Urdu ]
Test
[Assamese ] , [ Bengali ] , [ Gujarati ] , [ Hindi ] , [Kannada ] , [ Malayalam ] , [ Manipuri ] , [Marathi ] , [ Oriya ] , [Punjabi ] , [ Tamil ] , [ Telugu ], [ Urdu ]
Publication
- Minesh Mathew, Ajoy Mondal, and C V Jawahar , Towards Deployable OCR Models for Indic Languages , In Proceeding of International Conference on Pattern Recognition (ICPR), 2024.
Bibtex
@inproceedings{mathew2025towards, title={Towards Deployable OCR Models for Indic Languages}, author={Mathew, Minesh and Mondal, Ajoy and Jawahar, CV}, booktitle={International Conference on Pattern Recognition}, pages={167--182}, year={2025}, organization={Springer} }