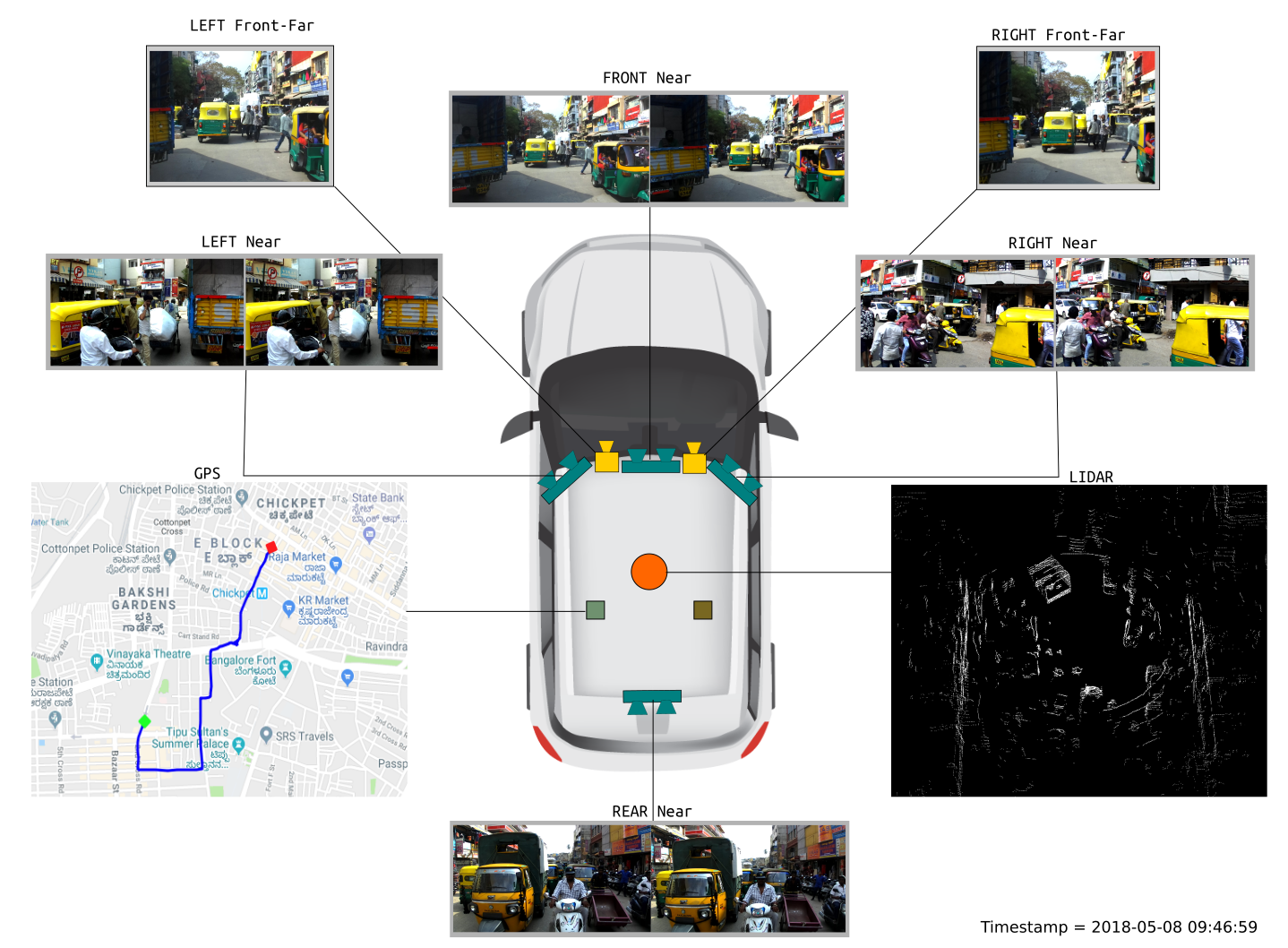
The dataset consists of images obtained from a front facing camera attached to a car. The car is driven around Hyderabad, Bangalore cities and their outskirts. The images are mostly of 1080p resolution, but there is also some images with 720p and other resolutions. The figure below gives an illustration of the data acquisition setup:
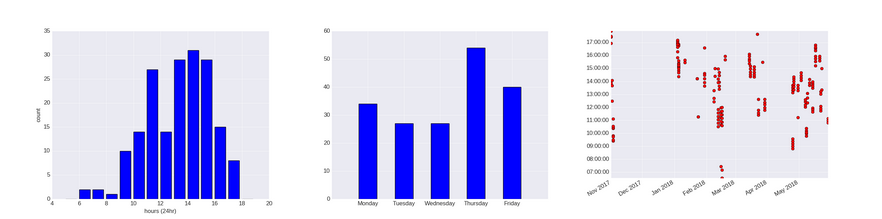
The following graphs gives the temporal diversity of the dataset:
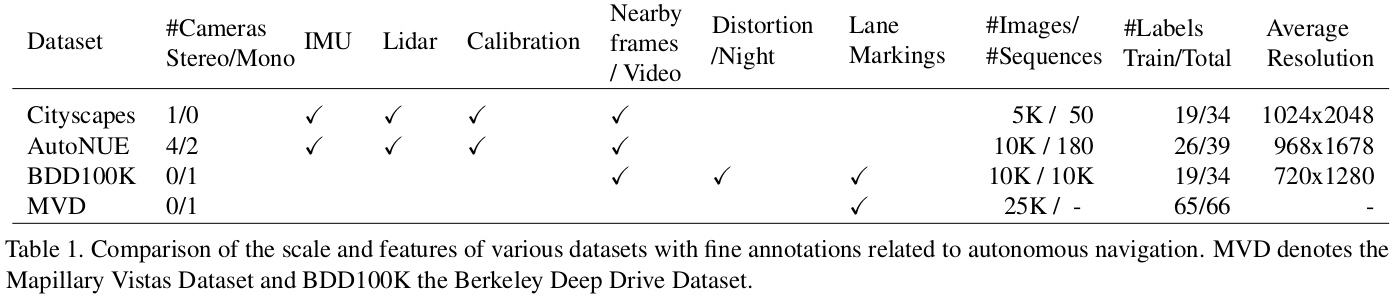
See below for a comparison with other similar datasets.
NOTE: Currently only 10K images and fine annotations are available. An extended dataset with automatic leader boards allowing submissions throughout the year will be released soon.
The dataset is divided into train, val and test splits as follows:
Our dataset annotations have unique labels like billboard, autorickshaw, animal etc. We also focus on identifying probable safe driving areas beside the road.
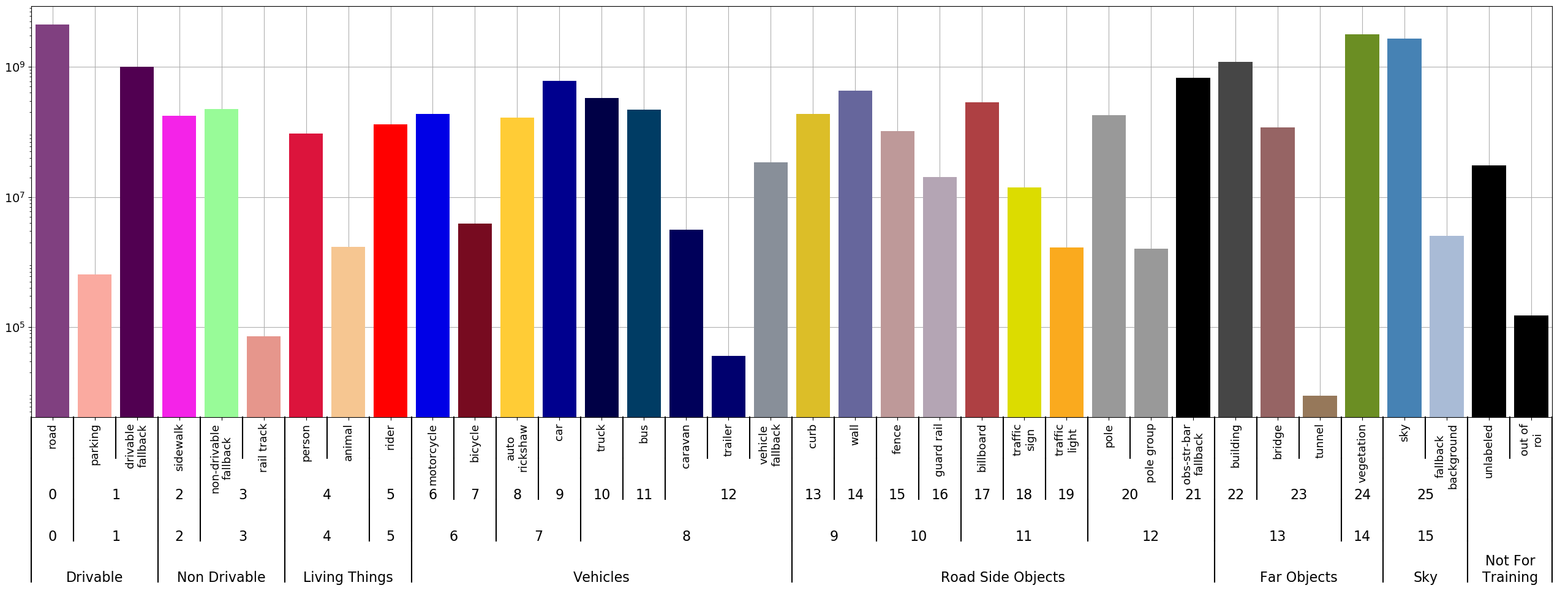
The labels for the dataset are organized as a 4 level hierarchy. Unique integer identifiers are given for each of these levels. The histogram below gives:
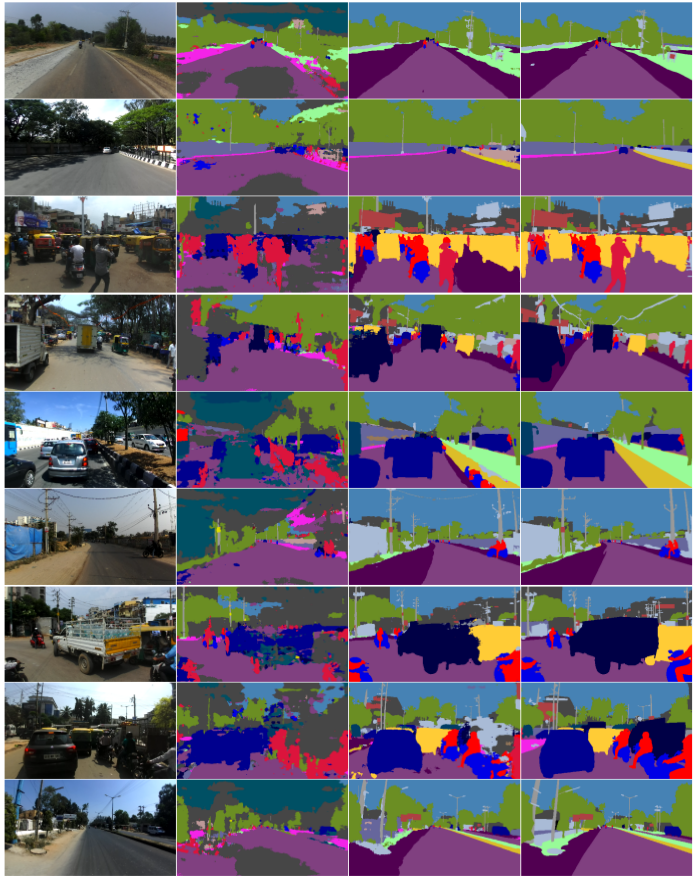
Some examples of the input images, predictions of a baseline Cityscapes pretrained model, predictions of the same baseline trained on this dataset and the ground truths from the validation set (in order of columns) can be seen below.
As can be seen models trained on our dataset clearly distinguishes muddy drivable areas beside the road from the road itself. Our dataset has labels like billboards and curb/median's in the middle of the road. Also our image frames are from unstructured driving settings, where road is muddy, lane disciple is not followed often and there is a large number of vehicles on the road.