A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild
Prajwal Renukanand* Rudrabha Mukhopadhyay* Vinay Namboodiri C.V. Jawahar
IIIT Hyderabad Univ. of Bath
[Code] [Interactive Demo] [Demo Video] [ReSyncED]

We propose a novel approach that achieves significantly more accurate lip-synchronization (A) in dynamic, unconstrained talking face videos. In contrast, we can see that the corresponding lip shapes generated by the current best model (B) is out-of-sync with the spoken utterances (shown at the bottom).
Abstract
In this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech segment. Current works excel at producing accurate lip movements on a static image or on videos of specific people seen during the training phase. However, they fail to accurately morph the actual lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the newly chosen audio. We identify key reasons pertaining to this and hence resolve them by learning from a powerful lip-sync discriminator. Next, we propose new, rigorous evaluation benchmarks and metrics to specifically measure the accuracy of lip synchronization in unconstrained videos. Extensive quantitative and human evaluations on our challenging benchmarks show that the lip-sync accuracy of the videos generated using our Wav2Lip model is almost as good as real synced videos. We clearly demonstrate the substantial impact of our Wav2Lip model in our publicly available demo video. We also open-source our code, models, and evaluation benchmarks to promote future research efforts in this space.
Paper
-

A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild
Prajwal Renukanand*, Rudrabha Mukhopadhyay*, Vinay Namboodiri and C.V. Jawahar
A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild, ACM Multimedia, 2020 .
[PDF] | [BibTeX]@misc{prajwal2020lip,
title={A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild},
author={K R Prajwal and Rudrabha Mukhopadhyay and Vinay Namboodiri and C V Jawahar},
year={2020},
eprint={2008.10010},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Live Demo
Please click here for the live demo : https://www.youtube.com/embed/0fXaDCZNOJc
Architecture
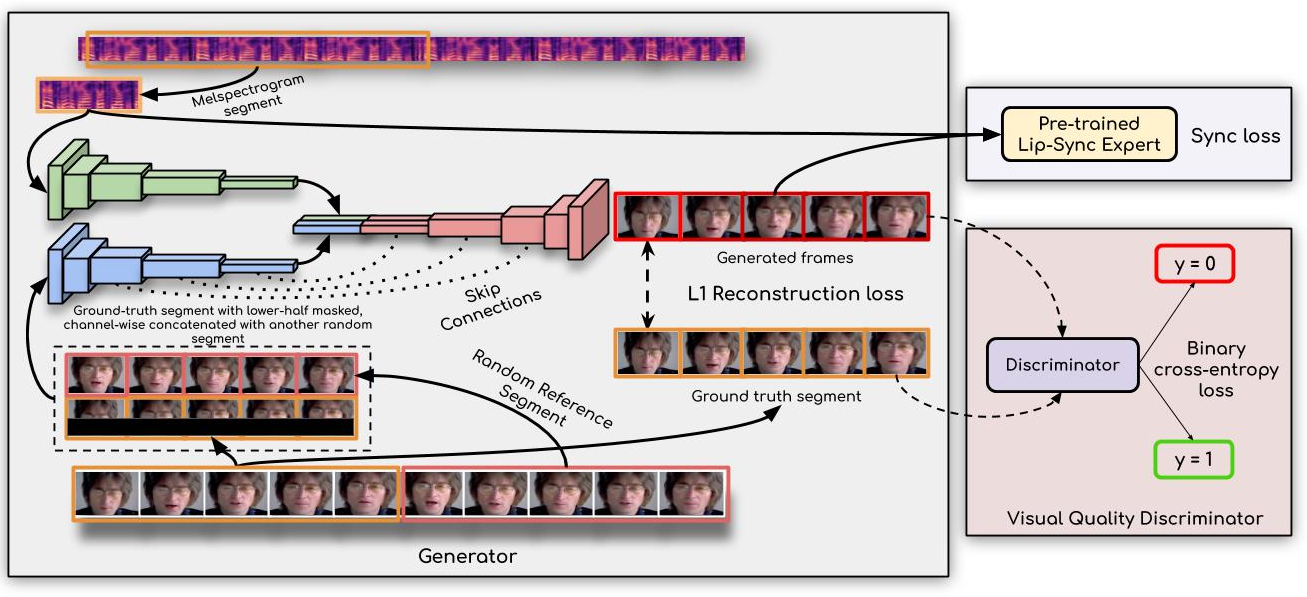
Architecture for generating speech from lip movements
Our approach generates accurate lip-sync by learning from an ``already well-trained lip-sync expert". Unlike previous works that employ only a reconstruction loss or train a discriminator in a GAN setup, we use a pre-trained discriminator that is already quite accurate at detecting lip-sync errors. We show that fine-tuning it further on the noisy generated faces hampers the discriminator's ability to measure lip-sync, thus also affecting the generated lip shapes.
Ethical Use
To ensure fair use, we strongly require that any result created using this our algorithm must unambiguously present itself as synthetic and that it is generated using the Wav2Lip model. In addition, to the strong positive applications of this work, our intention to completely open-source our work is that it can simultaneously also encourage efforts in detecting manipulated video content and their misuse. We believe that Wav2Lip can enable several positive applications and also encourage productive discussions and research efforts regarding fair use of synthetic content.
Contact
- Prajwal K R -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Rudrabha Mukhopadhyay -
This email address is being protected from spambots. You need JavaScript enabled to view it.