An OCR for Classical Indic Documents Containing Arbitrarily Long Words
Abstract
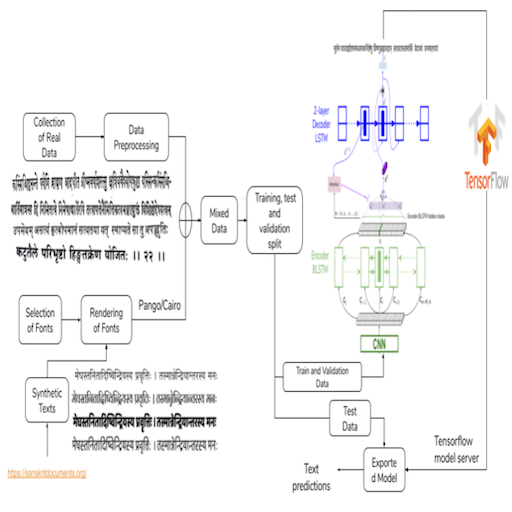
OCR for printed classical Indic documents written inSanskrit is a challenging research problem. It involves com-plexities such as image degradation, lack of datasets andlong-length words. Due to these challenges, the word ac-curacy of available OCR systems, both academic and in-dustrial, is not very high for such documents. To addressthese shortcomings, we develop a Sanskrit specific OCRsystem. We present an attention-based LSTM model forreading Sanskrit characters in line images. We introduce adataset of Sanskrit document images annotated at line level.To augment real data and enable high performance for ourOCR, we also generate synthetic data via curated font se-lection and rendering designed to incorporate crucial glyphsubstitution rules. Consequently, our OCR achieves a worderror rate of 15.97% and a character error rate of 3.71%on challenging Indic document texts and outperforms strongbaselines. Overall, our contributions set the stage for ap-plication of OCRs on large corpora of classic Sanskrit textscontaining arbitrarily long and highly conjoined words.
To access the code and paper click here
Bibtex
If you find our work useful in your research, please consider citing:
@InProceedings{Dwivedi_2020_CVPR_Workshops,
author = {Dwivedi, Agam and Saluja, Rohit and Kiran Sarvadevabhatla, Ravi},
title = {An OCR for Classical Indic Documents Containing Arbitrarily Long Words},
booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2020}
}