FaceOff: A Video-to-Video Face Swapping System
* indicates equal contribution
[Paper] [Video] [Code]
Abstract
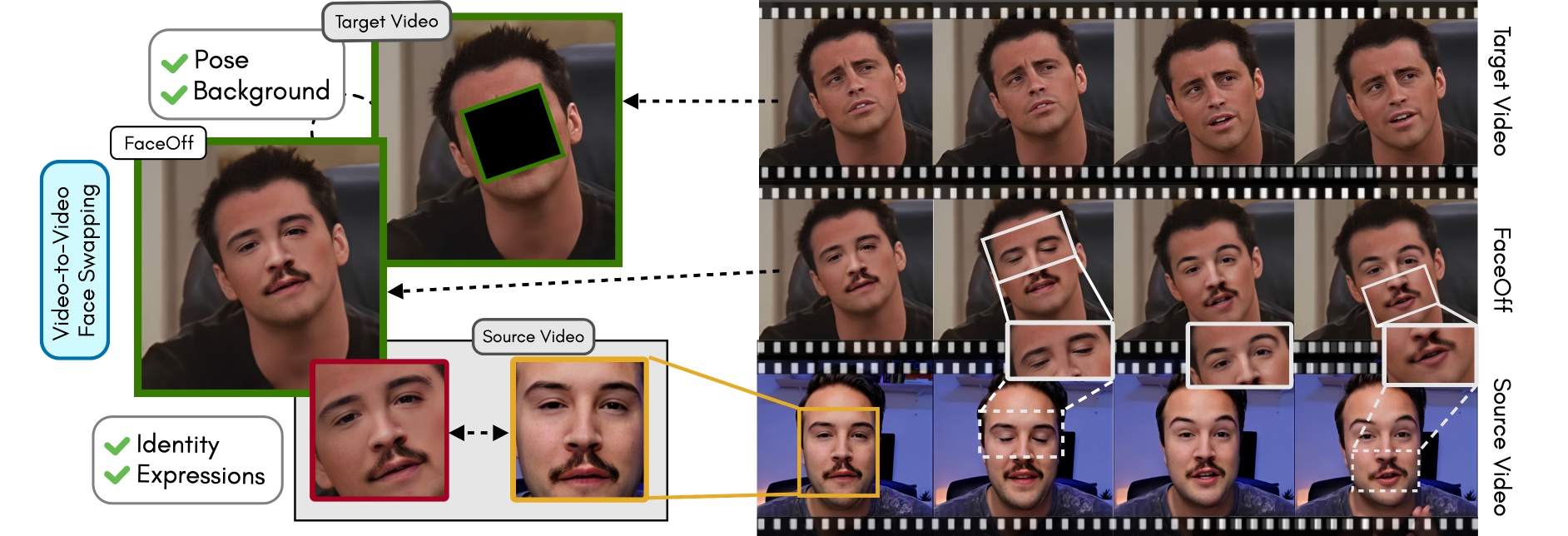
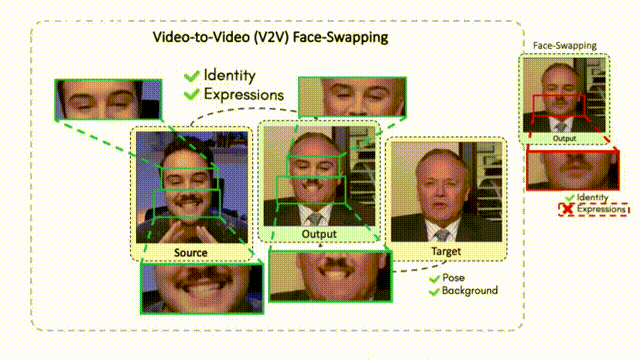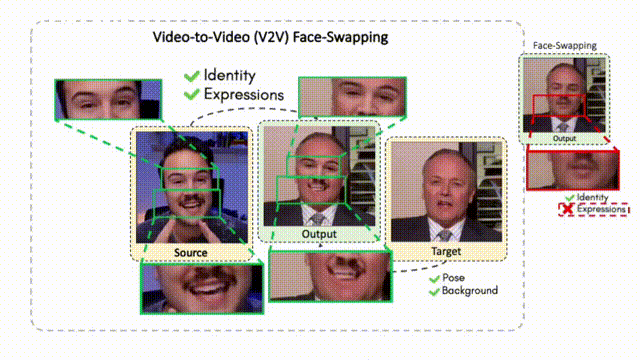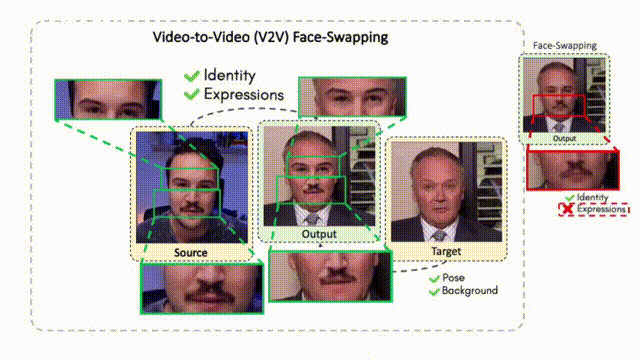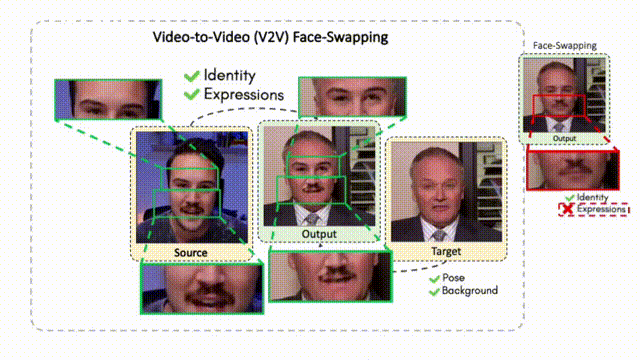
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology, costing millions of dollars and taking months to complete. An automated, inexpensive, and fast way can be to use face-swapping techniques that aim to swap an identity from a source face video (or an image) to a target face video. However, such methods cannot preserve the source expressions of the actor important for the scene's context. To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video. We propose FaceOff, a V2V face-swapping system that operates by learning a robust blending operation to merge two face videos following the constraints above. It reduces the videos to a quantized latent space and then blends them in the reduced space. FaceOff is trained in a self-supervised manner and robustly tackles the non-trivial challenges of V2V face-swapping. As shown in the experimental section, FaceOff significantly outperforms alternate approaches qualitatively and quantitatively.
Overview
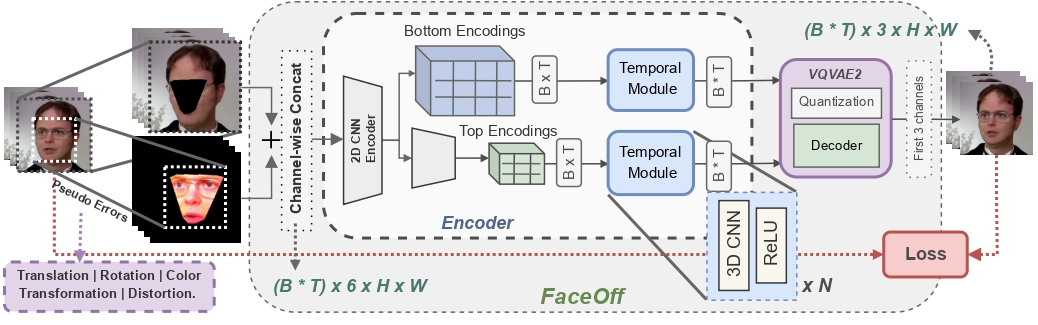
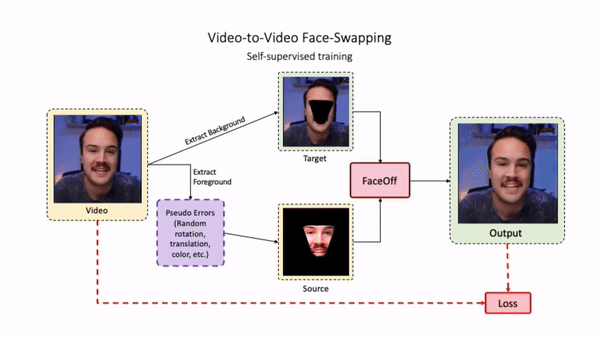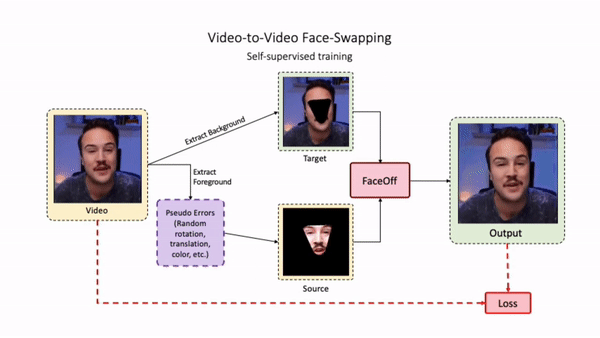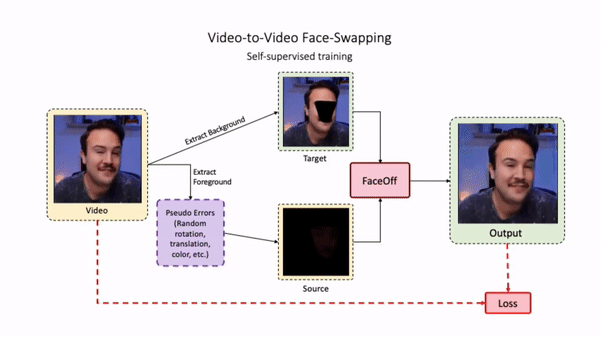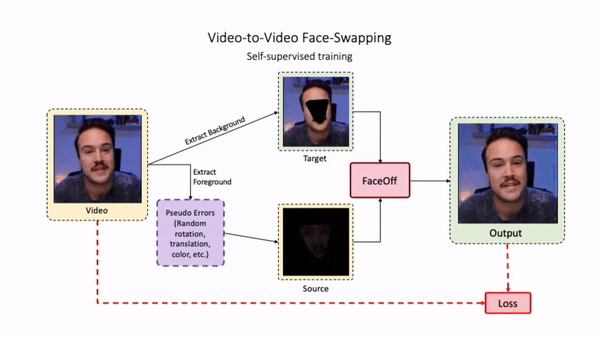
Swapping faces across videos is non-trivial as it involves merging two different motions - the actor's face motion and the double's head motion. This needs a network that can take two different motions as input and produce a third coherent motion. FaceOff is a video-to-video face swapping system that reduces the face videos to a quantized latent space and blends them in the reduced space. A fundamental challenge in training such a network is the absence of ground truth. FaceOff uses a self-supervised training strategy for training: A single video is used as the source and target. We then introduce pseudo motion errors on the source video. Finally, we train a network to fix these pseudo errors to regenerate the source video. To do this, we learn to blend the foreground of the source video with the background and pose of the target face video such that the blended output is coherent and meaningful. We use a temporal autoencoding module that merges the motion of the source and the target video using a quantized latent space. We propose a modified vector quantized encoder with temporal modules made of non-linear 3D convolution operations to encode the video to the quantized latent space. The input to the encoder is a single video made by concatenating the source foreground and target background frames channel-wise. The encoder first encodes the concatenated video input framewise into 32x32 and 64x64 dimensional top and bottom hierarchies, respectively. Before the quantization step at each of the hierarchies, the temporal modules process the reduced video frames. This step allows the network to backpropagate with temporal connections between the frames. The decoder then decodes the reduced frames using a distance loss with the ground truth video as supervision. The output is a temporally and spatially coherent blended video of the source foreground and the target background.
FaceOff Video-to-Video Face Swapping

Training Pipeline
Inference Pipeline
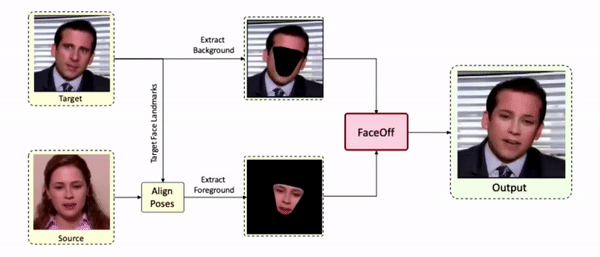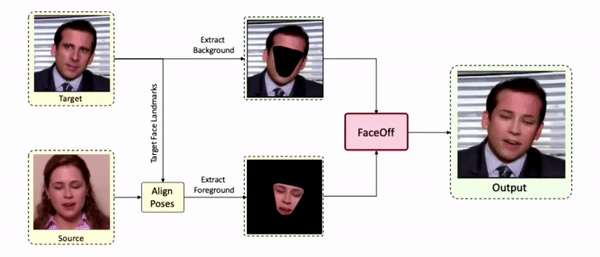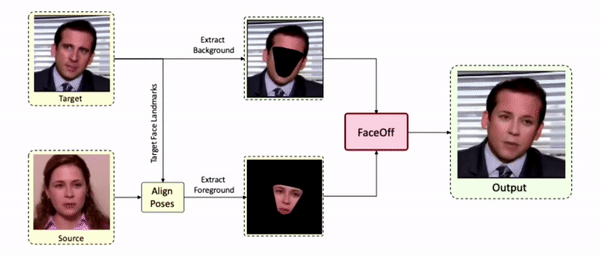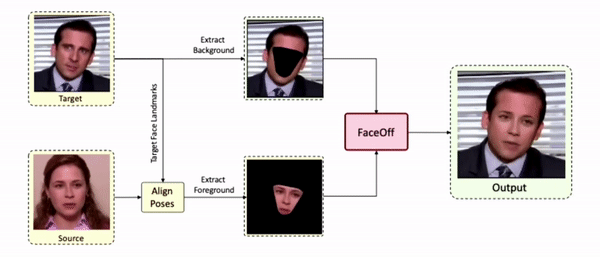
Results on Unseen Identities


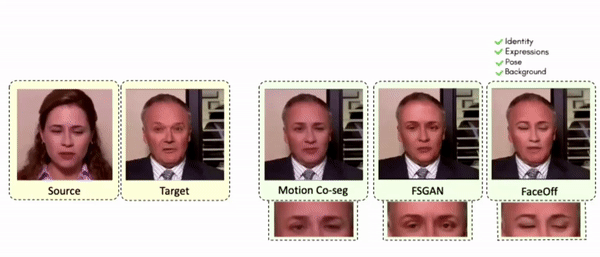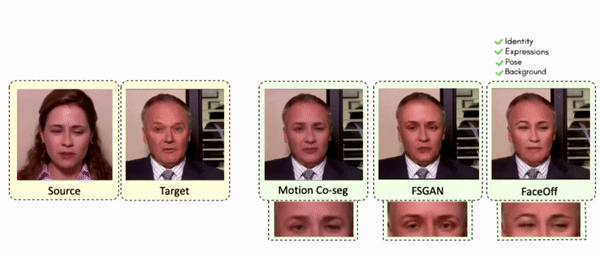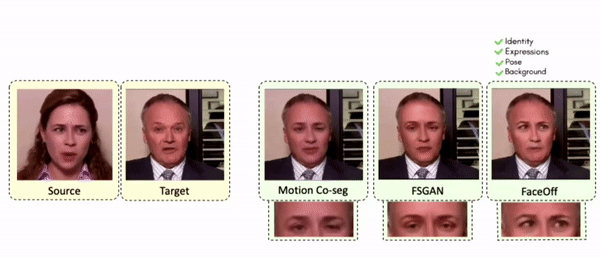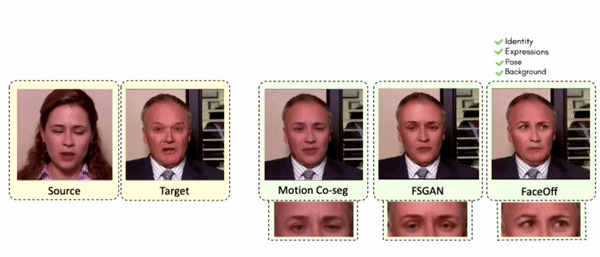
Comparisons


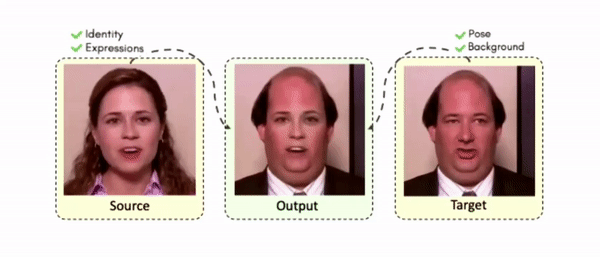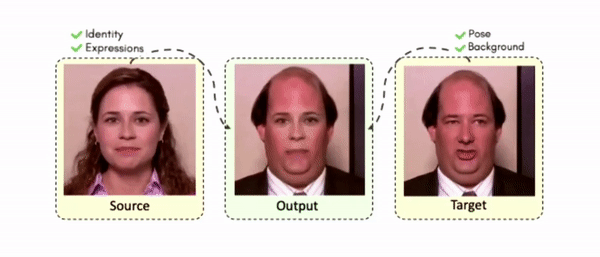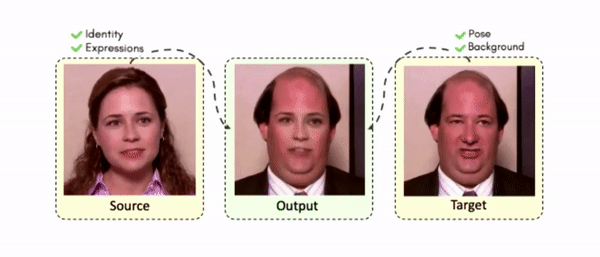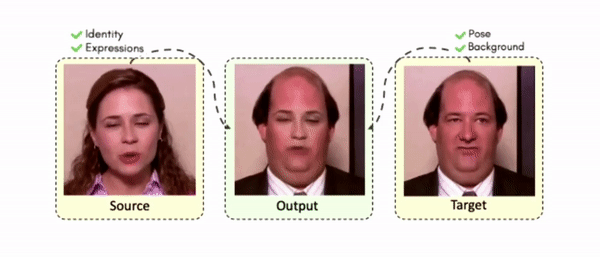
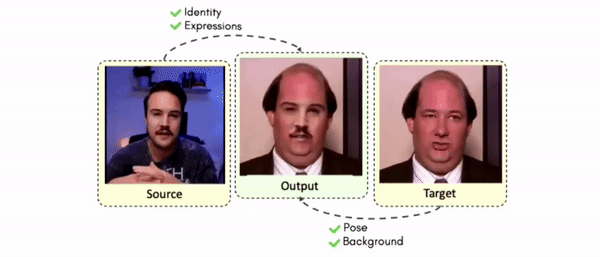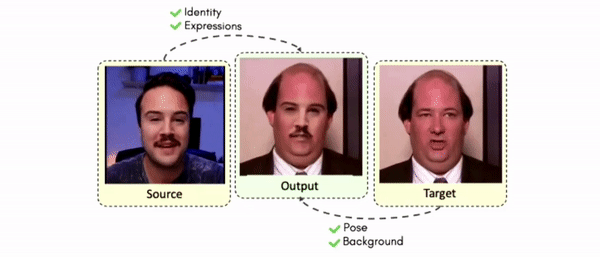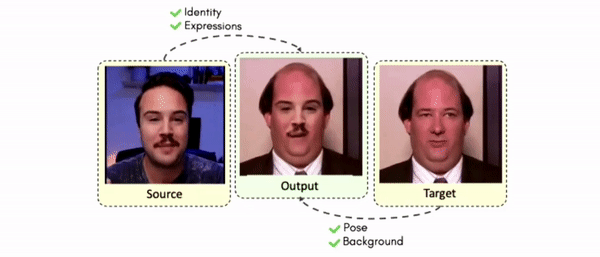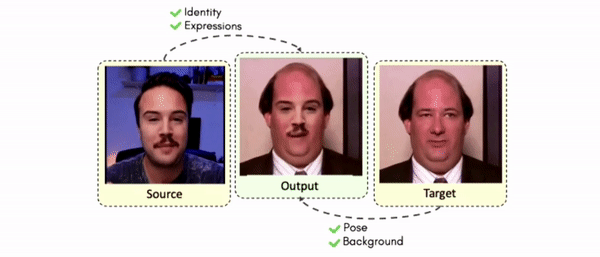
Results on Same Identity
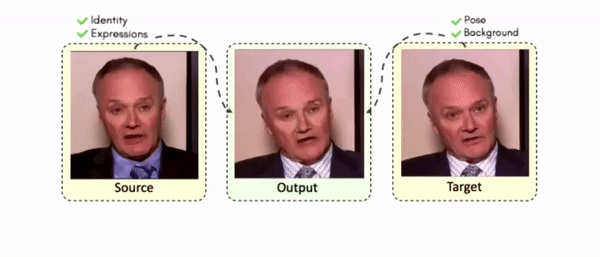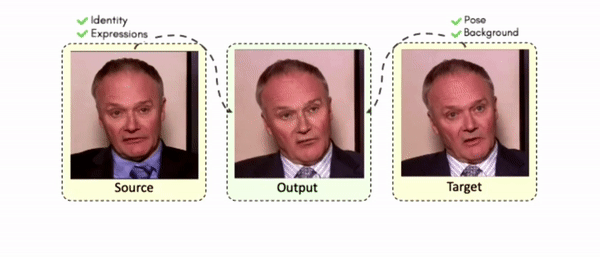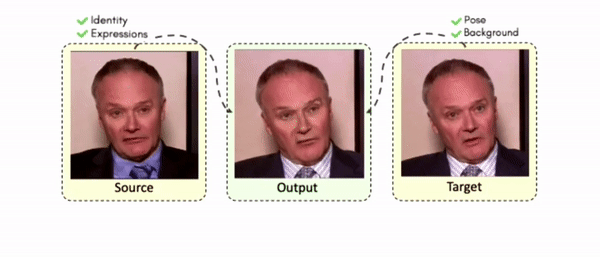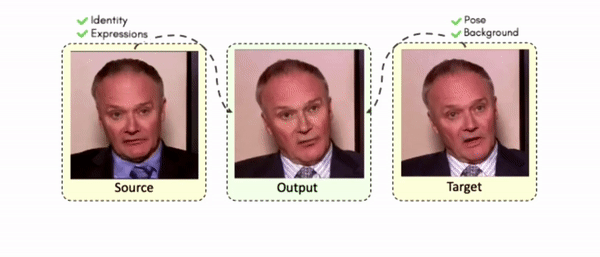
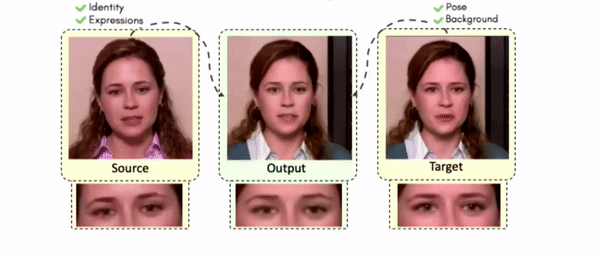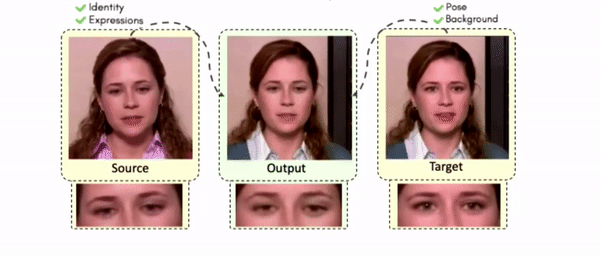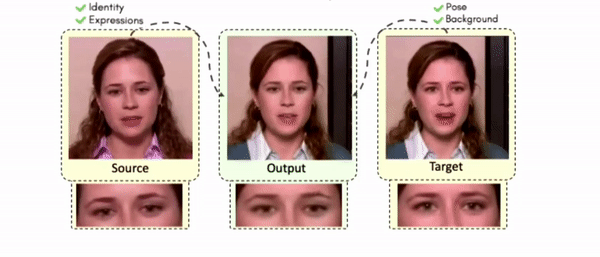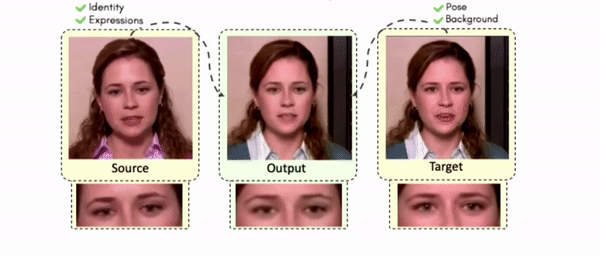

Some More Results

Citation
@misc{agarwal2023faceoff,
doi = {10.48550/ARXIV.2208.09788},
url = {https://arxiv.org/abs/2208.09788},
author = {Agarwal, Aditya and Sen, Bipasha and Mukhopadhyay, Rudrabha and Namboodiri, Vinay and Jawahar, C. V.},
keywords = {Computer Vision and Pattern Recognition (cs.CV)},
title = {FaceOff: A Video-to-Video Face Swapping System},
publisher = {IEEE/CVF Winter Conference on Applications of Computer Vision},
year = {2023},
}