Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Siddhant Bansal Praveen Krishnan C.V.Jawahar
DAS 2020

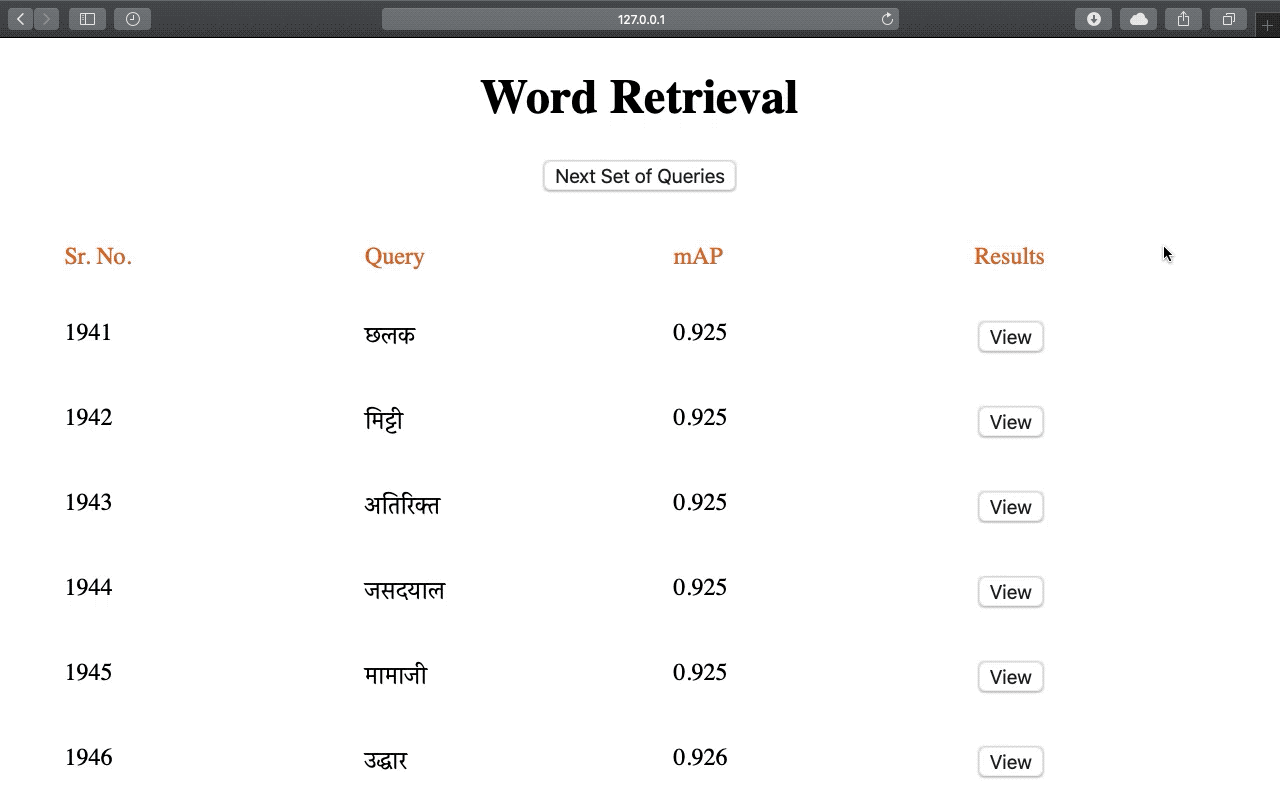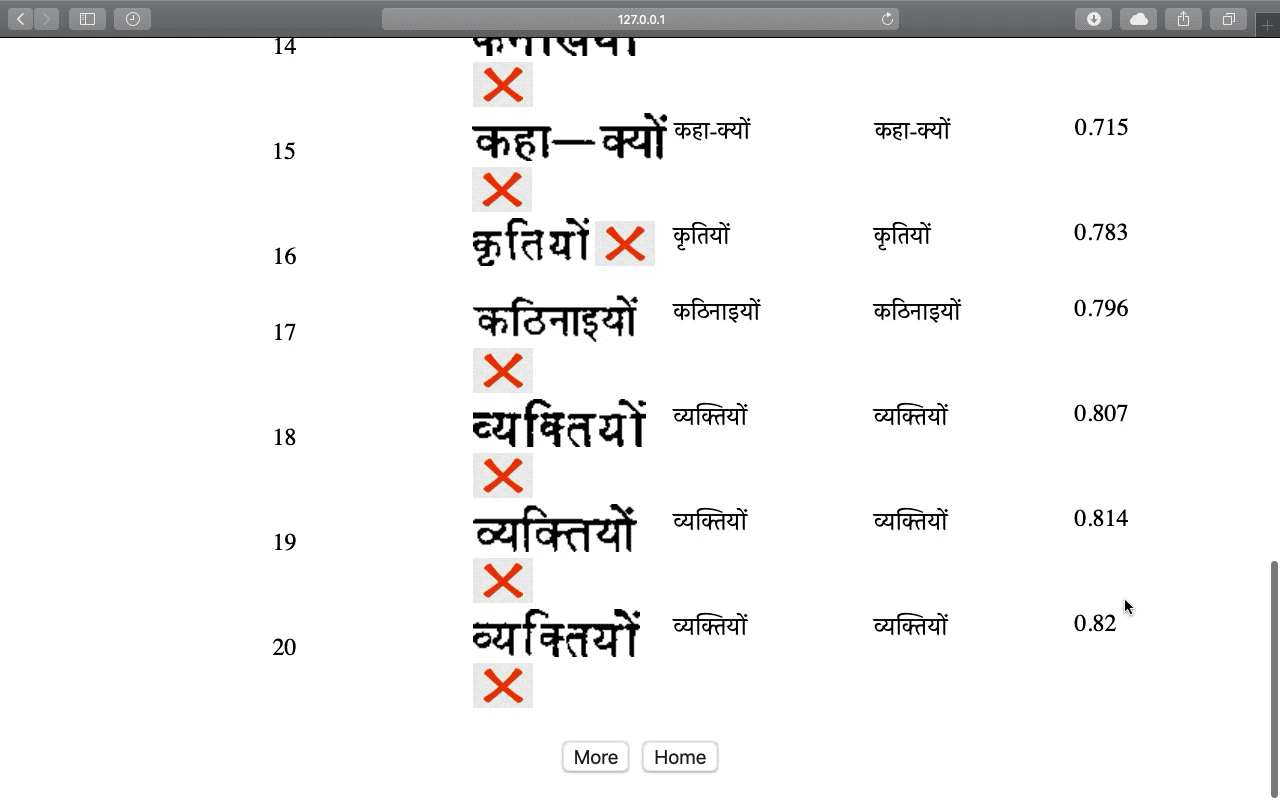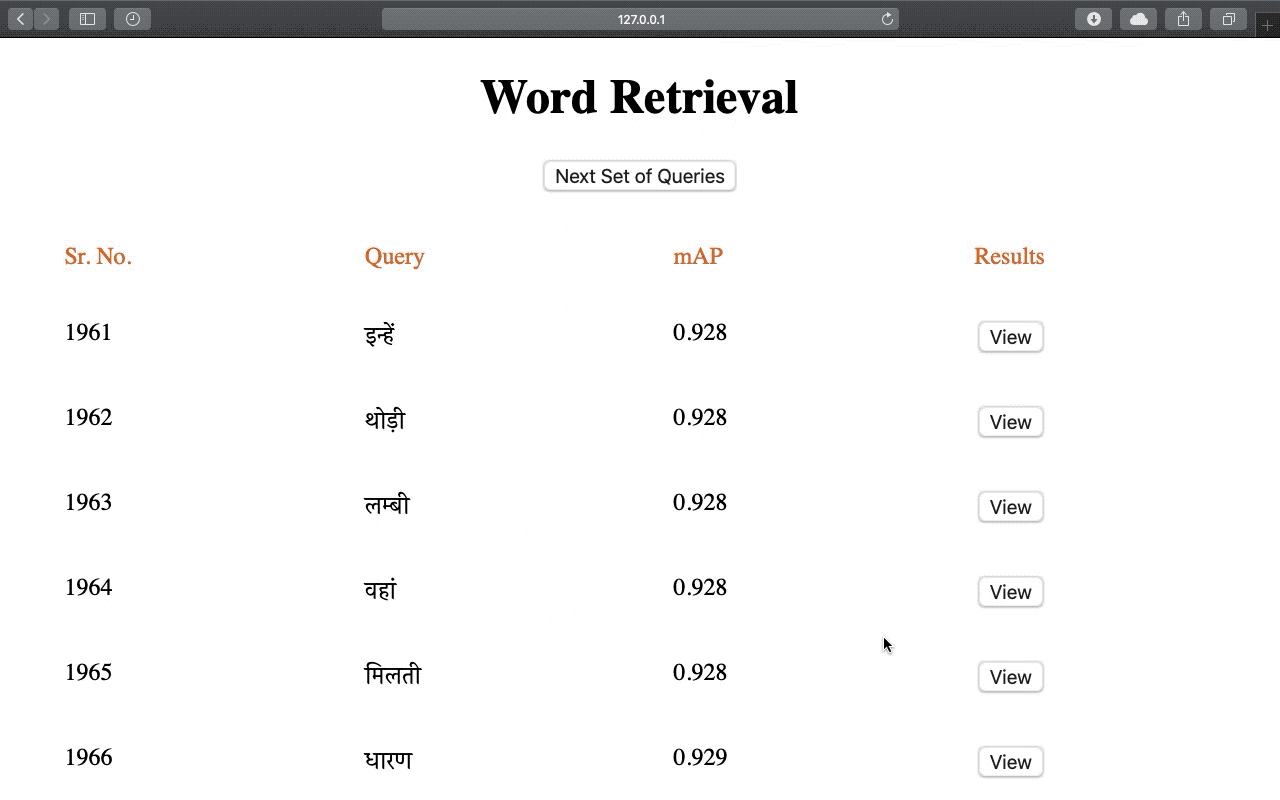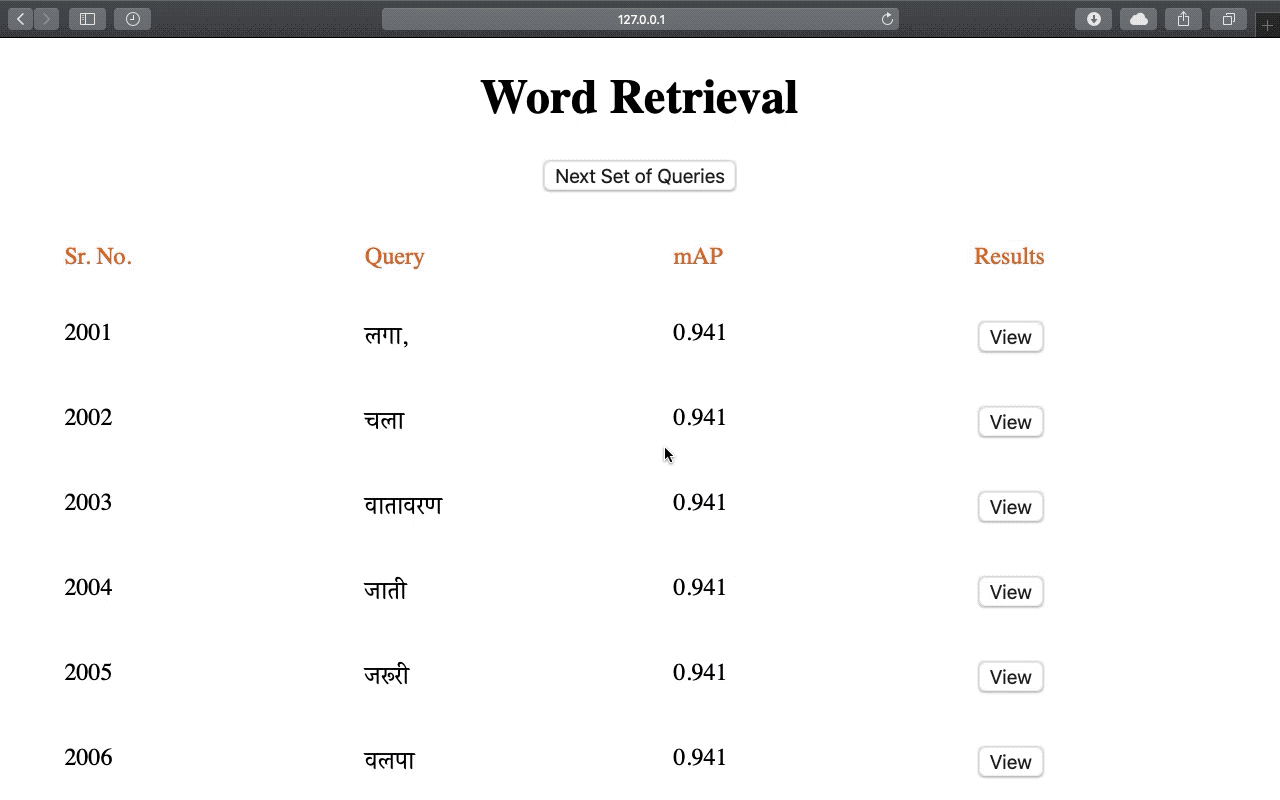
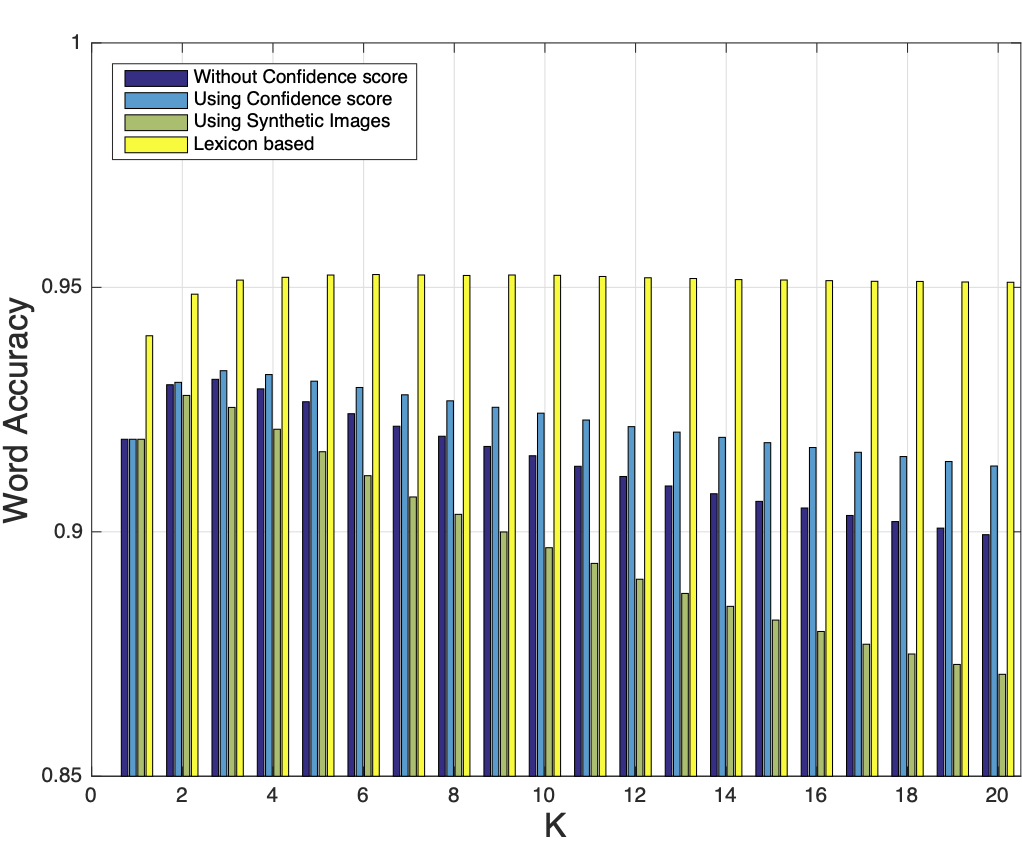
Recognition and retrieval of textual content from the large document collections have been a powerful use case for the document image analysis community. Often the word is the basic unit for recognition as well as retrieval. Systems that rely only on the text recogniser’s (OCR) output are not robust enough in many situations, especially when the word recognition rates are poor, as in the case of historic documents or digital libraries. An alternative has been word spotting based methods that retrieve/match words based on a holistic representation of the word. In this paper, we fuse the noisy output of text recogniser with a deep embeddings representation derived out of the entire word. We use average and max fusion for improving the ranked results in the case of retrieval. We validate our methods on a collection of Hindi documents. We improve word recognition rate by 1.4% and retrieval by 11.13% in the mAP.
Paper
-

Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Siddhant Bansal, Praveen Krishnan and C.V. Jawahar
DAS, 2020
[Paper] [Code] [Demo]
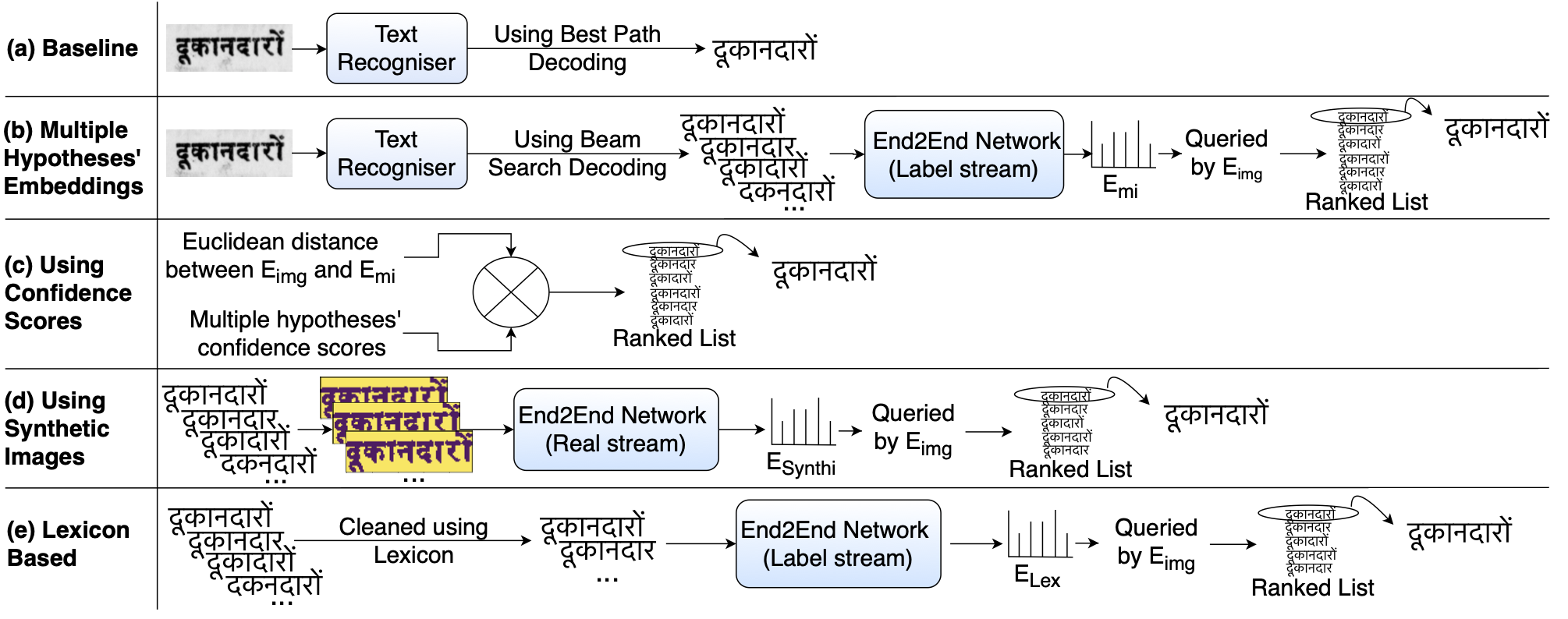
Word Recognition in a nutshell
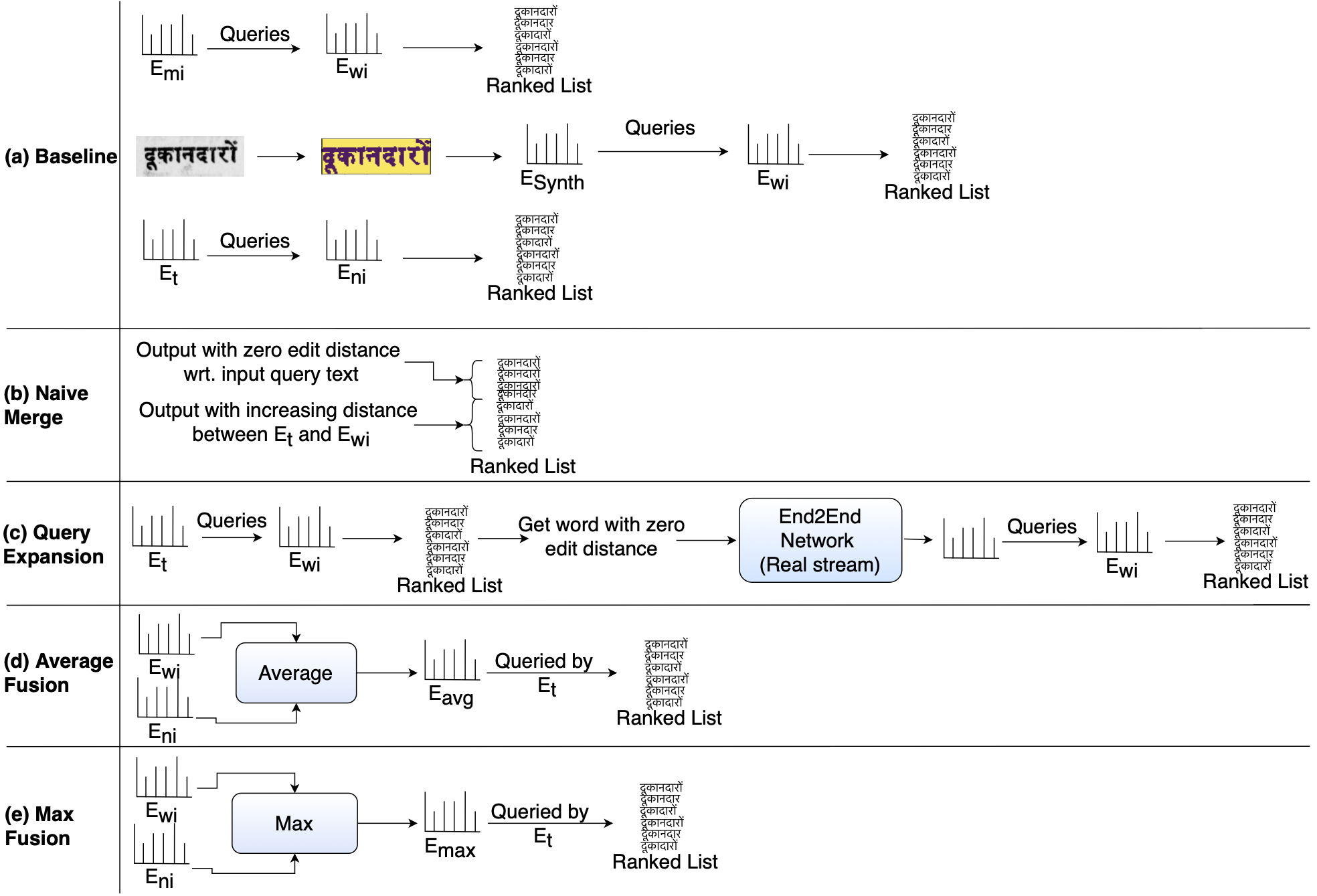
Word Retrieval in a nutshell
Results
Word Recognition
Word Retrieval
