HWNet - An Efficient Word Image Representation for Handwritten Documents
Overview
We propose a deep convolutional neural network named HWNet v2 (successor to our earlier work [1]) for the task of learning efficient word level representation for handwritten documents which can handle multiple writers and is robust to common forms of degradation and noise. We also show the generic nature of our representation and architecture which allows it to be used as off-the-shelf features for printed documents and building state of the art word spotting systems for various languages.
Major Highlights :
- We show an efficient usage of synthetic data which is practically available free of cost to pre-train a deep network. As part of this work, build and released synthetic handwritten dataset of 9 million word images referred as IIIT-HWS dataset.
- We present an adapted version of ResNet-34 architecture with ROI pooling which learns discriminative features with variable sized word images.
- We introduce realistic augmentation of training data which includes multiple scales and elastic distortion which mimics the natural process of handwriting.
- Our representation leads to state of the art word spotting performance on standard handwritten datasets and historical manuscripts in different languages with minimal representation size.
Architecture
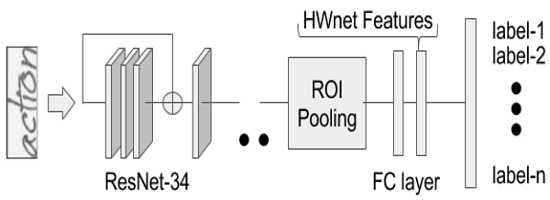
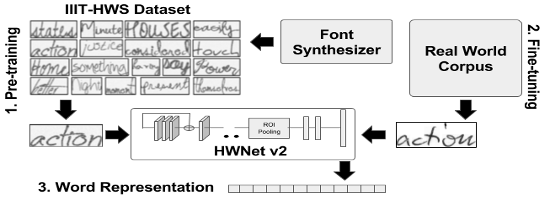
( Right )The HWNet features are taken from the penultimate layer of the network.
Codes and Dataset :
For codes visit GitHub Project: https://github.com/kris314/hwnet
IIIT-HWS Dataset: http://cvit.iiit.ac.in/research/projects/cvit-projects/matchdocimgs#iiit-hws
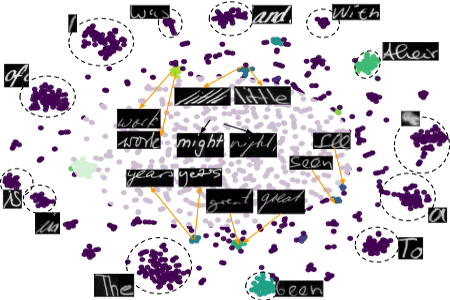
Visualizations


( Right )Four possible reconstructions of sample word images shown in columns. These are re-constructed from the representation of final layer of HWNet.

retrieved word images based on features similarity.
Related Papers
Praveen Krishnan and C.V Jawahar - Matching Handwritten Document Images, The 14th European Conference on Computer Vision (ECCV) – Amsterdam, The Netherlands, 2016. [PDF]
Praveen Krishnan, Kartik Dutta and C.V Jawahar - Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text, 15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China (ICFHR), 2016. [PDF]
Praveen Krishnan and C.V.Jawahar - Generating Synthetic Data for Text Recognition arXiv preprint arXiv:1608.04224 (2016). [PDF]
Contact