INR-V: A Continuous Representation Space for Video-based Generative Tasks
and C.V. Jawahar
* indicates equal contribution
TMLR, 2022
[ Paper ] | [ Video ] | [ Inference Code ] | [ OpenReview ]
Abstract

Overview
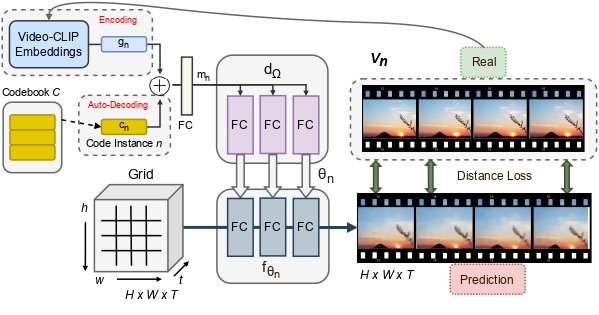
We parameterize videos as a function of space and time using implicit neural representations (INRs). Any point in a video Vhwt can be represented by a function fΘ→ RGBhwt where t denotes the tth frame in the video and h, w denote the spatial location in the frame, and RGB denotes the color at the pixel position {h, w, t}. Subsequently, the dynamic dimension of videos (a few million pixels) is reduced to a constant number of weights Θ (a few thousand) required for the parameterization. A network can then be used to learn a prior over videos in this parameterized space. This can be obtained through a meta-network that learns a function to map from a latent space to a reduced parameter space that maps to a video. A complete video is thus represented as a single latent point. We use a meta-network called hypernetworks that learns a continuous function over the INRs by getting trained on multiple video instances using a distance loss. However, hypernetworks are notoriously unstable to train, especially on the parameterization of highly expressive signals like videos. Thus, we propose key prior regularization and a progressive weight initialization scheme to stabilize the hypernetwork training allowing it to scale quickly to more than 30,000 videos. The learned prior enables several downstream tasks such as novel video generation, video inversion, future segment prediction, video inpainting, and smooth video interpolation directly at the video level.







Additional Interpolation Results







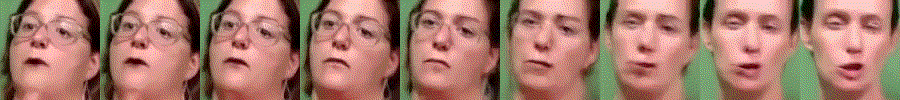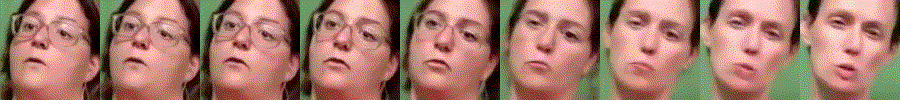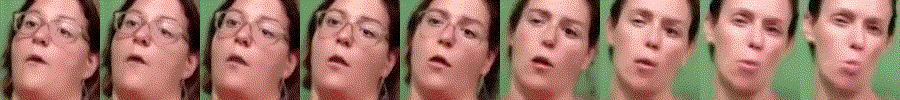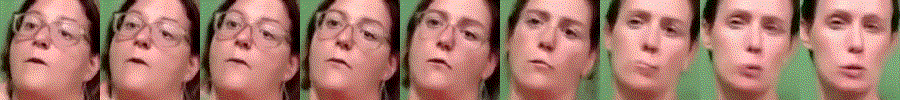

Citation
@article{ sen2022inrv,
title={ {INR}-V: A Continuous Representation Space for Video-based Generative Tasks},
author={Bipasha Sen and Aditya Agarwal and Vinay P Namboodiri and C.V. Jawahar},
journal={Transactions on Machine Learning Research},
year={2022},
url={https://openreview.net/forum?id=aIoEkwc2oB},
note={}
}
This website is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. It is borrowing the source code of this website.