PeeledHuman: Robust Shape Representation for Textured 3D Human Body Reconstruction
Sai Sagar Jinka, Rohan Chacko Avinash Sharma P.J. Narayanan
IIIT Hyderabad
[Demo Video]
International Conference on 3D Vision, 2020
Abstract
We introduce PeeledHuman - a novel shape representation of the human body that is robust to self-occlusions. PeeledHuman encodes the human body as a set of Peeled Depth and RGB maps in 2D, obtained by performing raytracing on the 3D body model and extending each ray beyond its first intersection. This formulation allows us to handle self-occlusions efficiently compared to other representations. Given a monocular RGB image, we learn these Peeled maps in an end-to-end generative adversarial fashion using our novel framework - PeelGAN. We train PeelGAN using a 3D Chamfer loss and other 2D losses to generate multiple depth values per-pixel and a corresponding RGB field per-vertex in a dual-branch setup. In our simple non-parametric solution, the generated Peeled Depth maps are back-projected to 3D space to obtain a complete textured 3D shape. The corresponding RGB maps provide vertex-level texture details. We compare our method with current parametric and non-parametric methods in 3D reconstruction and find that we achieve state-of-theart-results. We demonstrate the effectiveness of our representation on publicly available BUFF and MonoPerfCap datasets as well as loose clothing data collected by our calibrated multi-Kinect setup.
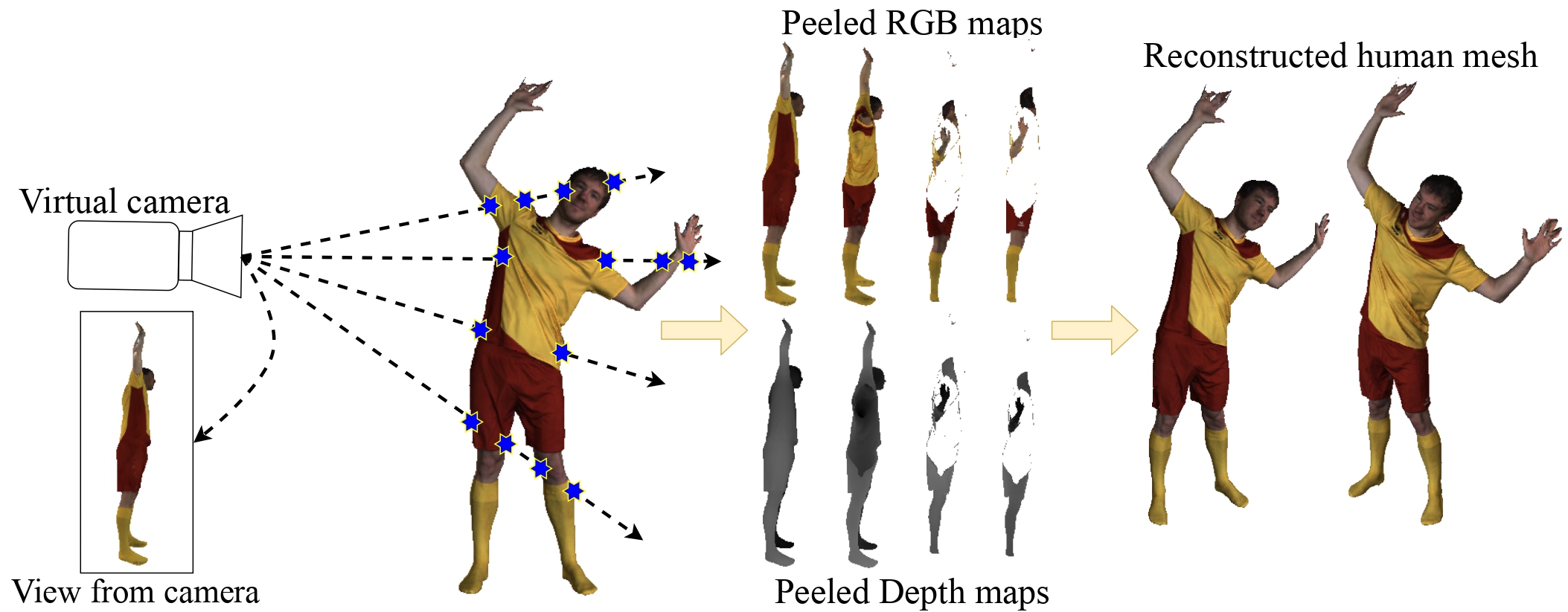
Our proposed representation encodes a human body as a set of Peeled Depth & RGB maps from a given view. These maps are backprojected to 3D space in the camera coordinate frame to recover the 3D human body.
Method
In this paper, we tackle the problem of textured 3D human reconstruction from a single RGB image by introducing a novel shape representation, called PeeledHuman. Our proposed solution derives inspiration from the classical ray tracing approach in computer graphics. We estimate a fixed number of ray intersection points with the human body surface in the canonical view volume for every pixel in an image, yielding a multi-layered shape representation called PeeledHuman. PeeledHuman encodes a 3D shape as a set of depth maps called Peeled Depth maps. We further extend this layered representation to recover texture by capturing a discrete sampling of the continuous surface texture called Peeled RGB maps. Such a layered representation of the body shape addresses severe self-occlusions caused by complex body poses and viewpoint variations. Our representation is similar to depth peeling used in computer graphics for order-independent transparency. The proposed shape representation allows us to recover multiple 3D points that project to the same pixel in the 2D image plane. Thus, we reformulate the solution to the monocular textured 3D body reconstruction task as predicting a set of Peeled Depth & RGB maps. To achieve this dual-prediction task, we propose PeelGAN, a dual-task generative adversarial network that generates a set of depth and RGB maps in two different branches of the network. These predicted peeled maps are then back-projected to 3D space to obtain a point cloud. Our proposed representation enables an end-to-end, non-parametric and differentiable solution for textured 3D body reconstruction. It is important to note that our representation is not restricted only to human body models but can generalize well to any 3D shapes/scenes, given specific training data prior.
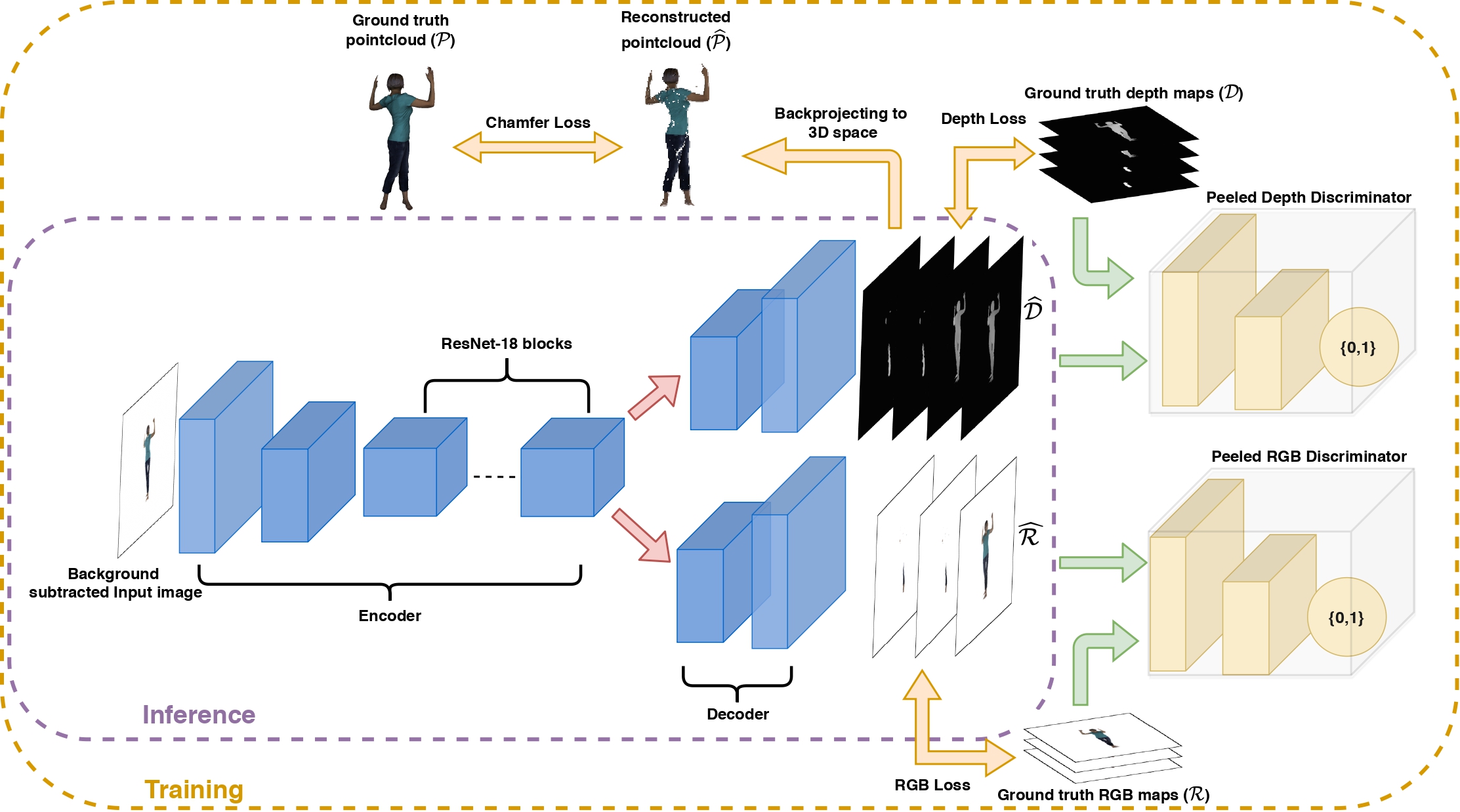
PeelGAN overview: The dual-branch network generates Peeled Depth (D) and RGB (R) maps from an input image. The generated maps are each fed to a discriminator: one for RGB and one for Depth maps. The generated maps are backprojected to obtain the 3D human body represented as a point cloud (p) in the camera coordinate frame. We employ a Chamfer loss between the reconstructed 3D human body represented as a point cloud (p̂) point cloud and the ground-truth point cloud (p) along with several other 2D losses on the Peeled maps.
Contributions
- We introduce PeeledHuman - a novel shape representation of the human body encoded as a set of Peeled Depth and RGB maps, that is robust to severe self-occlusions.
- Our proposed representation is efficient in terms of both encoding 3D shapes as well as feed-forward time yielding superior quality of reconstructions with faster inference rates.
- We propose PeelGAN - a complete end-to-end pipeline to reconstruct a textured 3D human body from a single RGB image using an adversarial approach.
- We introduce a challenging 3D dataset consisting of multiple human action sequences with variations in shape and pose, draped in loose clothing. We intend to release this data along with our code for academic use.
Related Publication
- Rohan Chacko, Sai Sagar Jinka, Avinash Sharma, P.J. Narayanan - PeeledHuman: Robust Shape Representation for Textured 3D Human Body Reconstruction - International Conference on 3D Vision (3DV), 2020