Surface Reconstruction
Recovering a 3D human body shape from a monocular image is an ill-posed problem in computer vision with great practical importance for many applications, including virtual and augmented reality platforms, animation industry, e-commerce domain, etc.
[Video]
HumanMeshNet: Polygonal Mesh Recovery of Humans
Abstract:
3D Human Body Reconstruction from a monocular image is an important problem in computer vision with applications in virtual and augmented reality platforms, animation industry, en-commerce domain, etc. While several of the existing works formulate it as a volumetric or parametric learning with complex and indirect reliance on re-projections of the mesh, we would like to focus on implicitly learning the mesh representation. To that end, we propose a novel model, HumanMeshNet, that regresses a template mesh's vertices, as well as receives a regularization by the 3D skeletal locations in a multi-branch, multi-task setup. The image to mesh vertex regression is further regularized by the neighborhood constraint imposed by mesh topology ensuring smooth surface reconstruction. The proposed paradigm can theoretically learn local surface deformations induced by body shape variations and can therefore learn high-resolution meshes going ahead. We show comparable performance with SoA (in terms of surface and joint error) with far lesser computational complexity, modeling cost and therefore real-time reconstructions on three publicly available datasets. We also show the generalizability of the proposed paradigm for a similar task of predicting hand mesh models. Given these initial results, we would like to exploit the mesh topology in an explicit manner going ahead.
Method
In this paper, we attempt to work in between a generic point cloud and a mesh - i.e., we learn an "implicitly structured" point cloud. Attempting to produce high resolution meshes are a natural extension that is easier in 3D space than in the parametric one. We present an initial solution in that direction - HumanMeshNet that simultaneously performs shape estimation by regressing to template mesh vertices (by minimizing surface loss) as well receives a body pose regularisation from a parallel branch in multi-task setup. Ours is a relatively simpler model as compared to the majority of the existing methods for volumetric and parametric model prediction (e.g.,Bodynet). This makes it efficient in terms of network size as well as feed forward time yielding significantly high frame-rate reconstructions. At the same time, our simpler network achieves comparable accuracy in terms of surface and joint error w.r.t. majority of state-of-the-art techniques on three publicly available datasets. The proposed paradigm can theoretically learn local surface deformations induced by body shape variations which the PCA space of parametric body models can't capture. In addition to predicting the body model, we also show the generalizability of our proposed idea for solving a similar task with different structure - non-rigid hand mesh reconstructions from a monocular image.
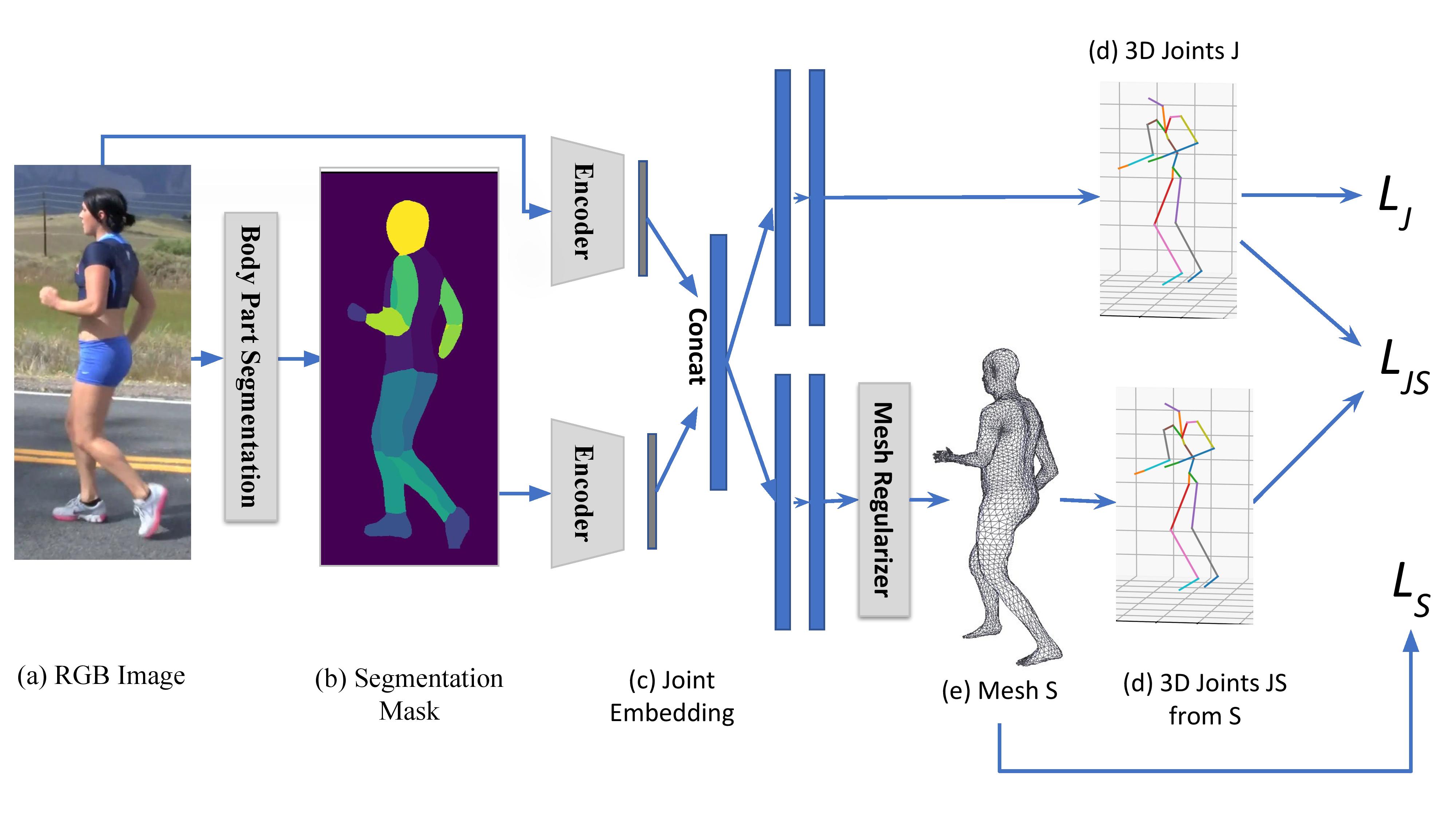
We we propose a novel model, HumanMeshNet which is a Multi-Task 3D Human Mesh Reconstruction Pipeline. Given a monocular RGB image (a), we first extract a body part-wise segmentation mask using Densepose (b). Then, using a joint embedding of both the RGB and segmentation mask (c), we predict the 3D joint locations (d) and the 3D mesh (e), in a multi-task setup. The 3D mesh is predicted by first applying a mesh regularizer on the predicted point cloud. Finally, the loss is minimized on both the branches (d) and (e).
Contributions:
- We propose a simple end-to-end multi-branch, multi-task deep network that exploits a "structured point cloud" to recover a smooth and fixed topology mesh model from a monocular image.
- The proposed paradigm can theoretically learn local surface deformations induced by body shape variations which the PCA space of parametric body models can't capture.
- The simplicity of the model makes it efficient in terms of network size as well as feed forward time yielding significantly high frame-rate reconstructions, while simultaneously achieving comparable accuracy in terms of surface and joint error, as shown on three publicly available datasets.
- We also show the generalizability of our proposed paradigm for a similar task of reconstructing the hand mesh models from a monocular image.