Canonical Saliency Maps: Decoding Deep Face Models
Thrupthi Ann John[1], Vineeth N Balasubramanian[2] and C.V. Jawahar[1]
IIIT Hyderabad[1] IIT Hyderabad[2]
[ Code ] | [ Demo Video ]
Abstract
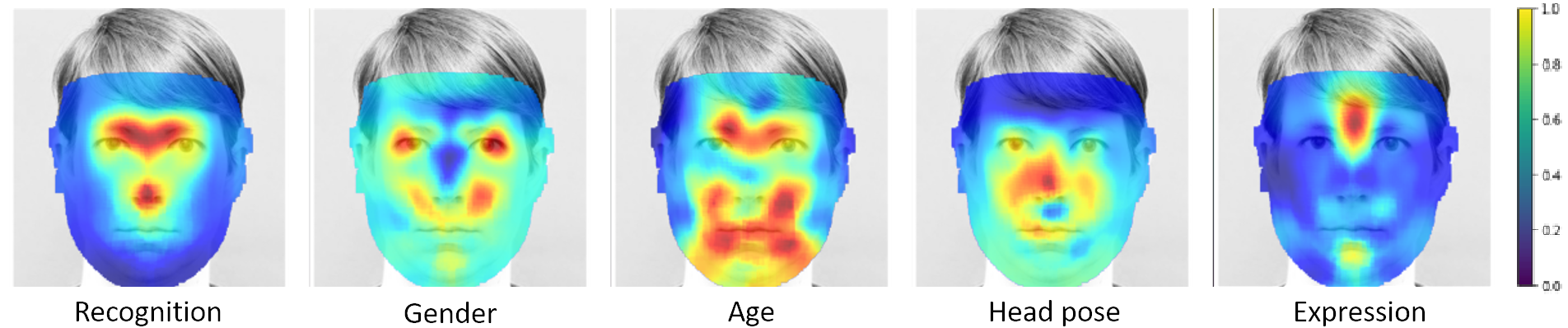
As Deep Neural Network models for face processing tasks approach human-like performance, their deployment in critical applications such as law enforcement and access control has seen an upswing, where any failure may have far-reaching consequences. We need methods to build trust in deployed systems by making their working as transparent as possible. Existing visualization algorithms are designed for object recognition and do not give insightful results when applied` to the face domain. In this work, we present `Canonical Saliency Maps', a new method which highlights relevant facial areas by projecting saliency maps onto a canonical face model. We present two kinds of Canonical Saliency Maps: image-level maps and model-level maps. Image-level maps highlight facial features responsible for the decision made by a deep face model on a given image, thus helping to understand how a DNN made a prediction on the image. Model-level maps provide an understanding of what the entire DNN model focuses on in each task, and thus can be used to detect biases in the model. Our qualitative and quantitative results show the usefulness of the proposed canonical saliency maps, which can be used on any deep face model regardless of the architecture.
Demo
Related Publications
Canonical Saliency Maps: Decoding Deep Face Models
Thrupthi Ann John, Vineeth N Balasubramanian and C. V. Jawahar
Canonical Saliency Maps: Decoding Deep Face Models , IEEE Transactions in Biometrics, Behavior and Identity Science 2021 Volume 3, Issue 4. [ PDF ] , [ BibTeX ]
Contact
For any queries about the work, please contact the authors below
- Thrupthi Ann John - thrupthi [dot] ann [at] research [dot] iiit [dot] ac [dot] in