MeronymNet: A Hierarchical Model for Unified and Controllable Multi-Category Object Generation
Rishabh Baghel, Abhishek Trivedi, Tejas Ravichandran, and Ravi Kiran Sarvadevabhatla
[Project Page Link] [Paper] [ GitHub]
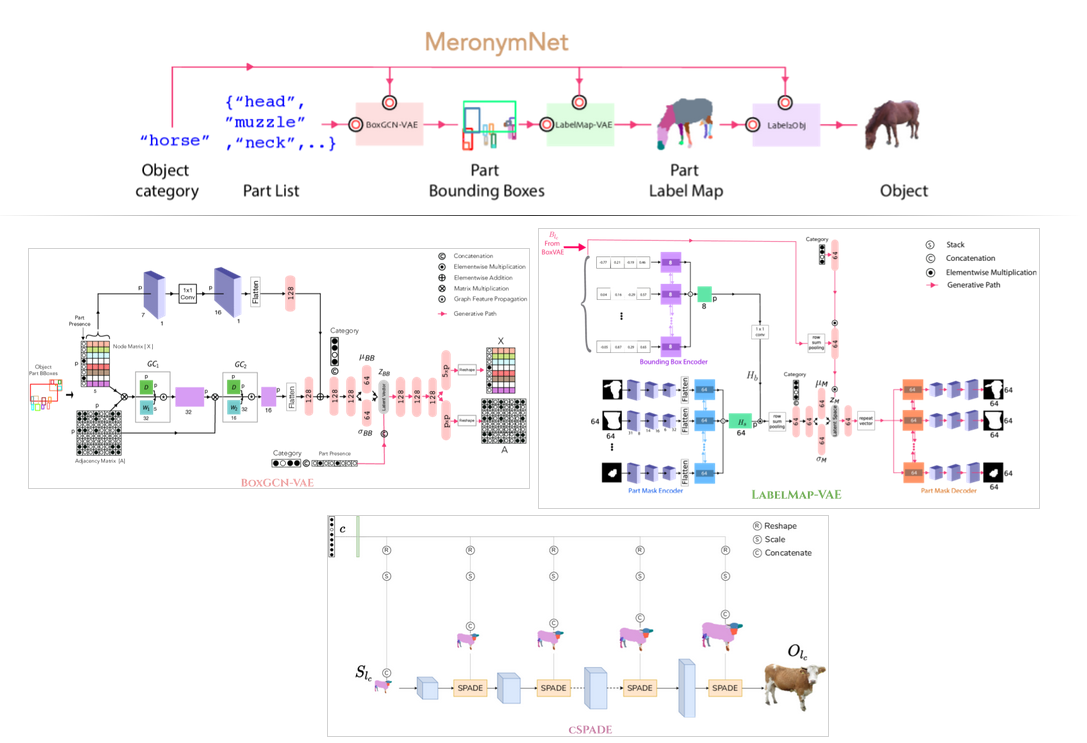
Overview
- We introduce MeronymNet, a novel hierarchical approach for controllable, part-based generation of multi-category objects using a single unified model.
- We adopt a guided coarse-to-fine strategy involving semantically conditioned generation of bounding box layouts, pixel-level part layouts and ultimately, the object depictions themselves.
- We use Graph Convolutional Networks, Deep Recurrent Networks along with custom-designed Conditional Variational Autoencoders to enable flexible, diverse and category-aware generation of 2-D objects in a controlled manner.
- The performance scores for generated objects reflect MeronymNet's superior performance compared to multiple strong baselines and ablative variants.
- We also showcase MeronymNet's suitability for controllable object generation and interactive object editing at various levels of structural and semantic granularity.
Results
 Look at sample generations by MeronymNet. For each sample, the generated bounding box, corresponding label mask and the RGB object can be seen. Notice the diversity in number of parts, appearance and viewpoint among the generated objects.
Look at sample generations by MeronymNet. For each sample, the generated bounding box, corresponding label mask and the RGB object can be seen. Notice the diversity in number of parts, appearance and viewpoint among the generated objects.
Application Scenario: Interactive Modification
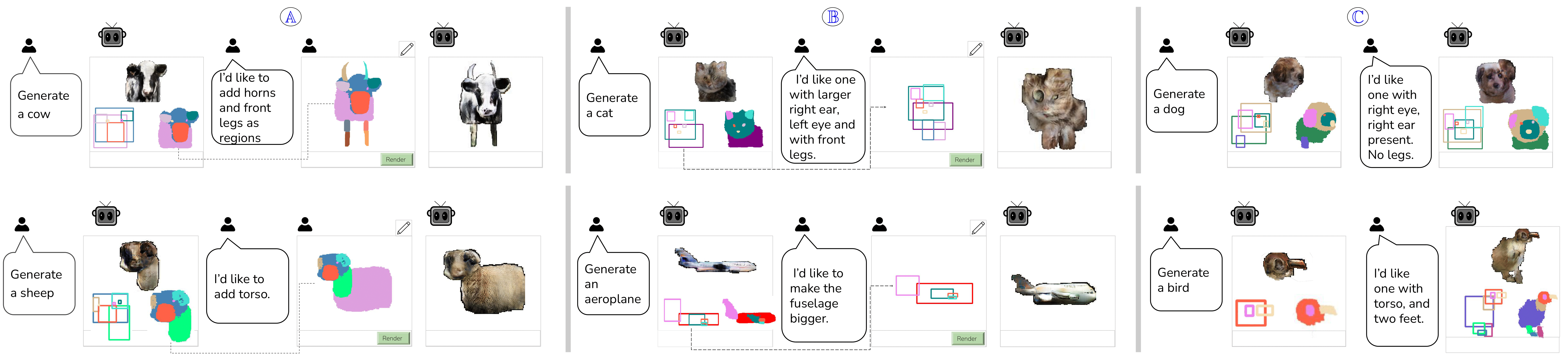 Our model allows users to have control on part level, which they can interact with either using boxes or masks. Notice that the viewpoint for rendering the object has changed from the initial generation to accommodate the updated part list. This scenario especially demonstrates MeronymNet’s holistic, part-based awareness of rendering viewpoints best suited for various part sets.
Our model allows users to have control on part level, which they can interact with either using boxes or masks. Notice that the viewpoint for rendering the object has changed from the initial generation to accommodate the updated part list. This scenario especially demonstrates MeronymNet’s holistic, part-based awareness of rendering viewpoints best suited for various part sets.
Dataset
 We use the large-scale part-segmented object dataset, PASCAL Parts. The plot shows the density distribution of part counts in object instances for each category. The varying range and frequency of part occurrences across categories, combined with the requirement of object generation from a single unified model, poses lots of challenges.
We use the large-scale part-segmented object dataset, PASCAL Parts. The plot shows the density distribution of part counts in object instances for each category. The varying range and frequency of part occurrences across categories, combined with the requirement of object generation from a single unified model, poses lots of challenges.
Contact
- If you have any question, please contact Dr. Ravi Kiran Sarvadevabhatla at -
This email address is being protected from spambots. You need JavaScript enabled to view it. .