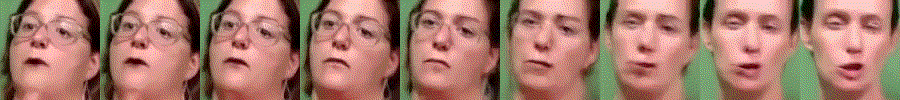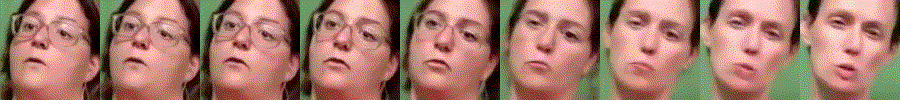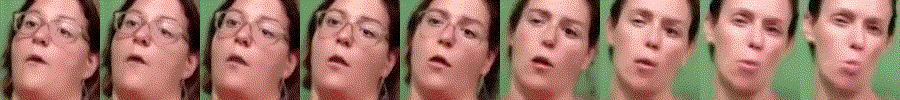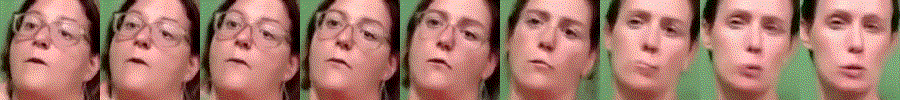Towards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
1IIIT Hyderabad, India
2University of Bath, UK
* indicates equal contribution
Abstract
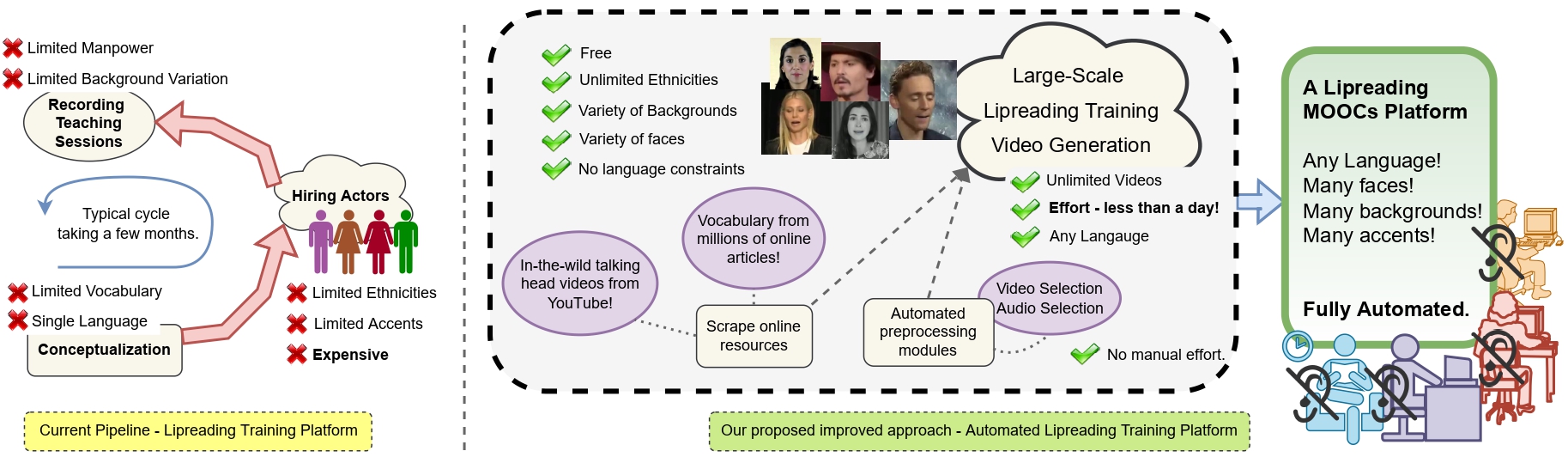
Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging. This is further exacerbated in the COVID19 pandemic due to restrictions on direct interactions with peers and speech therapists. Today, online MOOCs platforms like Coursera and Udemy have become the most effective form of training for many types of skill development. However, online lipreading resources are scarce as creating such resources is an extensive process needing months of manual effort to record hired actors. Because of the manual pipeline, such platforms are also limited in vocabulary, supported languages, accents, and speakers and have a high usage cost. In this work, we investigate the possibility of replacing real human talking videos with synthetically generated videos. Synthetic data can easily incorporate larger vocabularies, variations in accent, and even local languages and many speakers. We propose an end-to-end automated pipeline to develop such a platform using state-of-the-art talking head video generator networks, text-to-speech models, and computer vision techniques. We then perform an extensive human evaluation using carefully thought out lipreading xercises to validate the quality of our designed platform against the existing lipreading platforms. Our studies concretely point toward the potential of our approach in developing a large-scale lipreading MOOC platform that can impact millions of people with hearing loss.
Overview
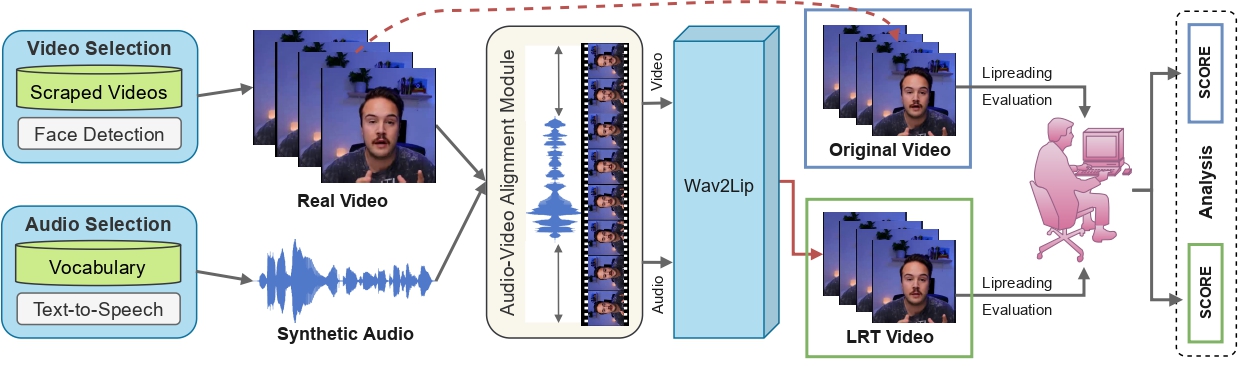
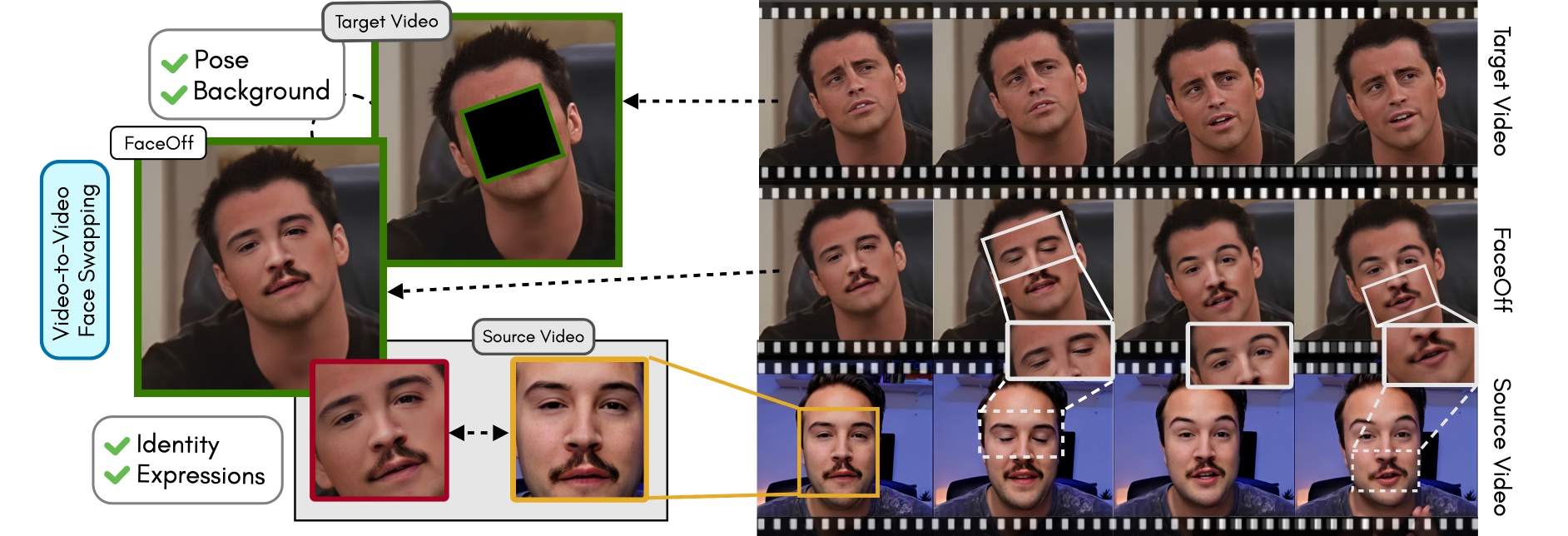
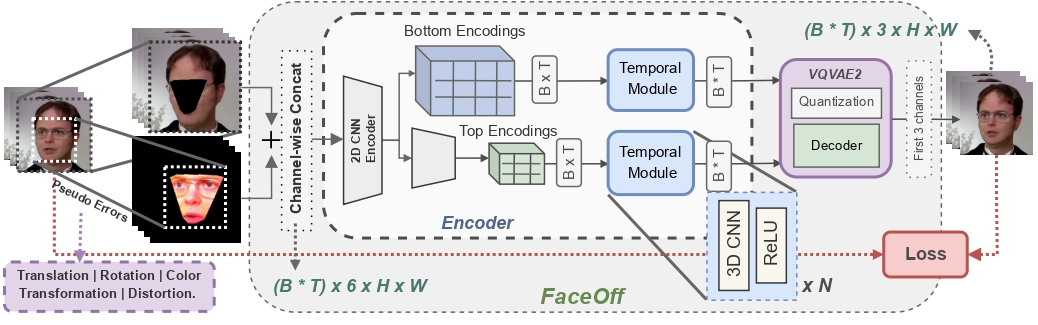
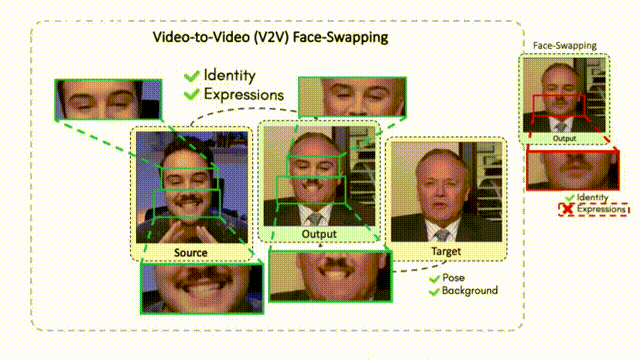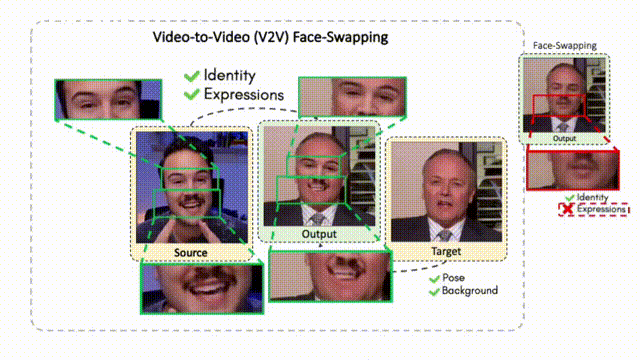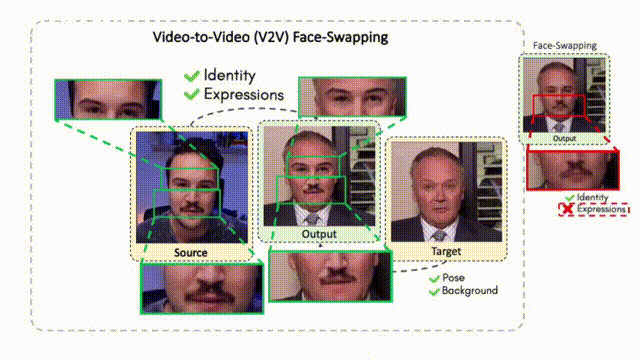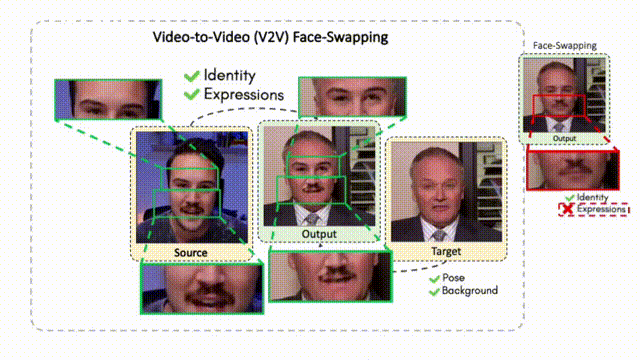
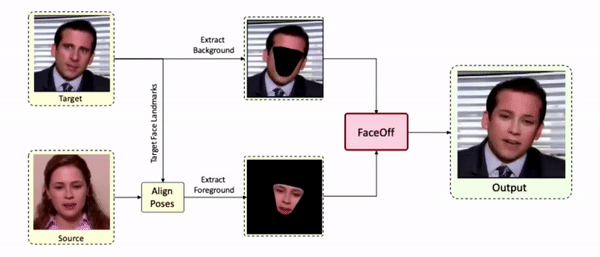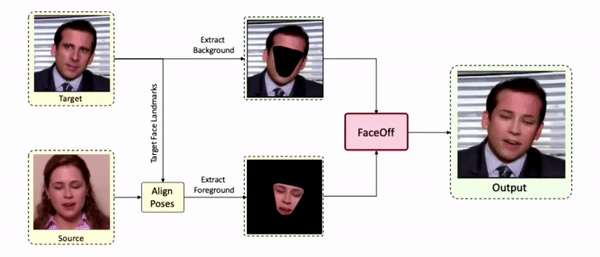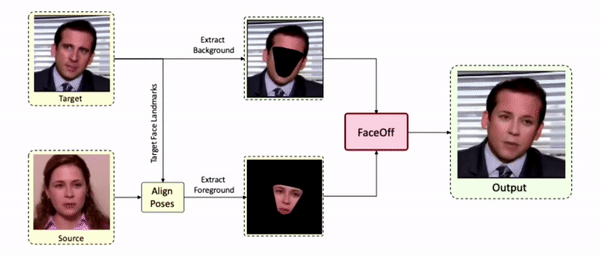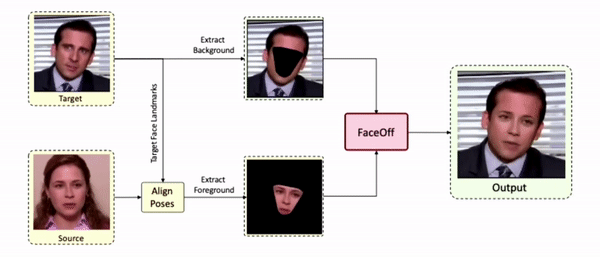
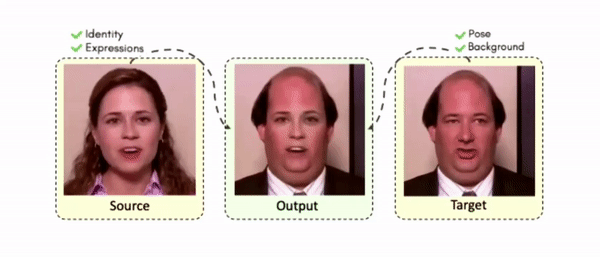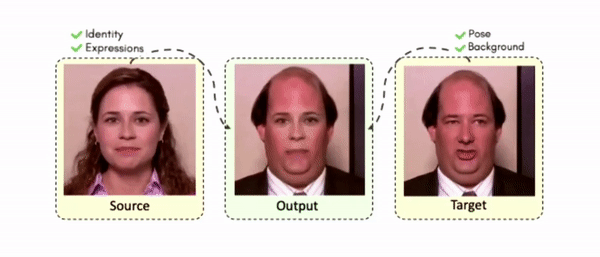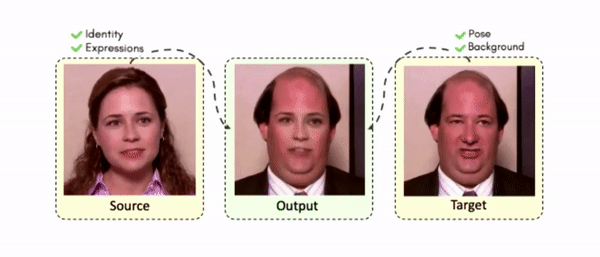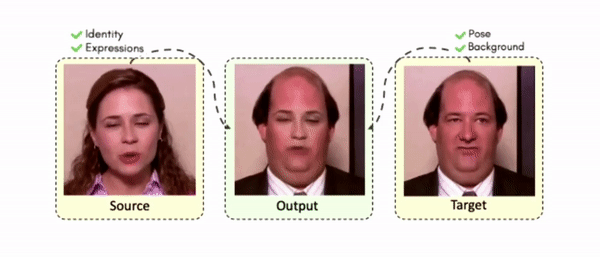
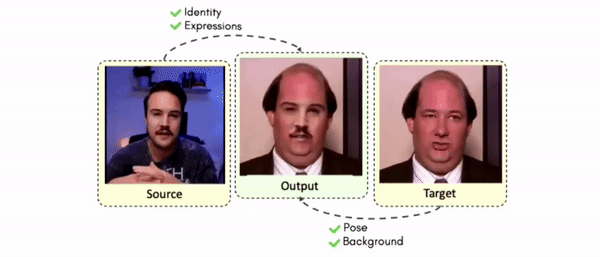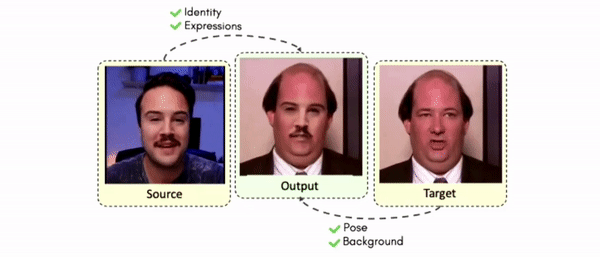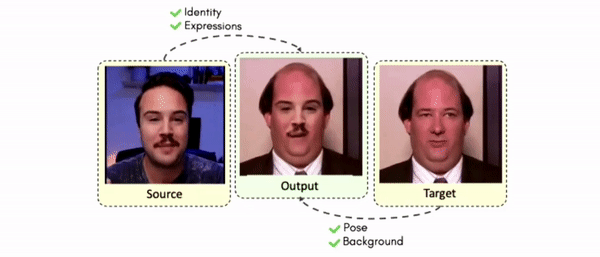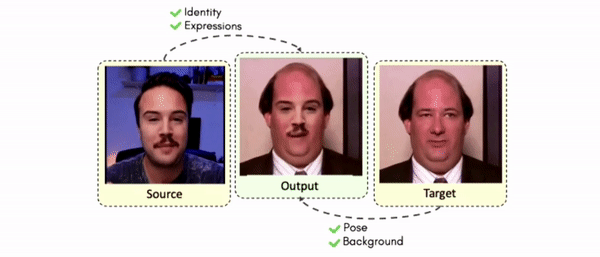
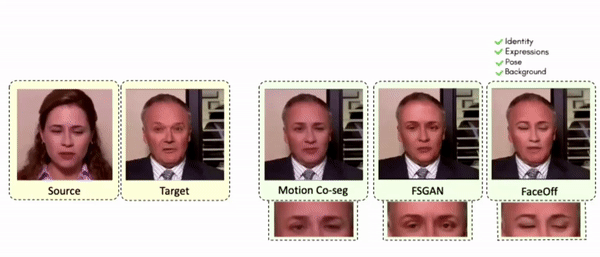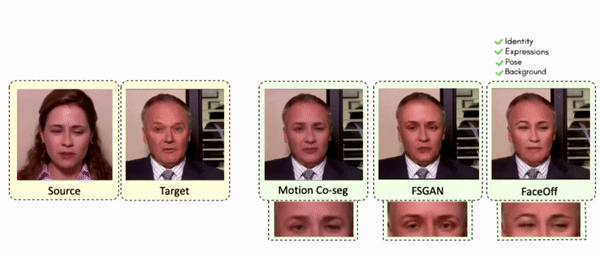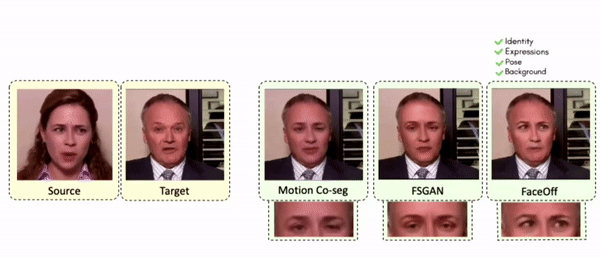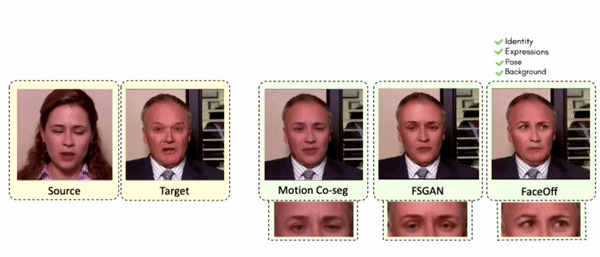
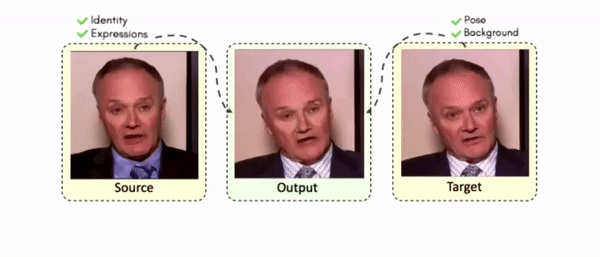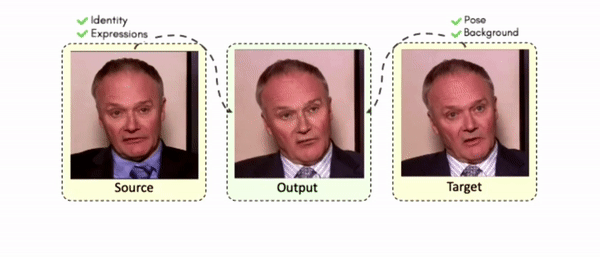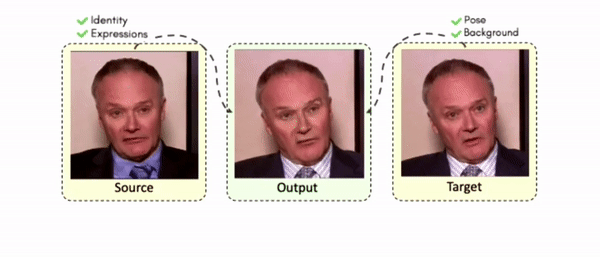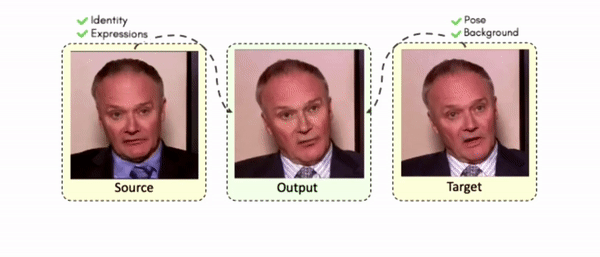
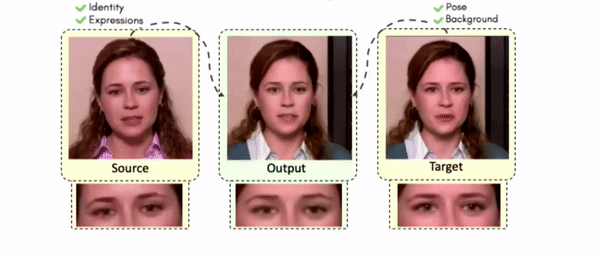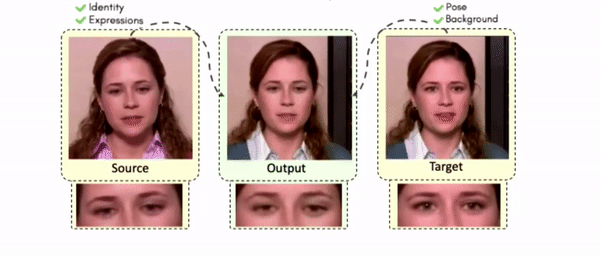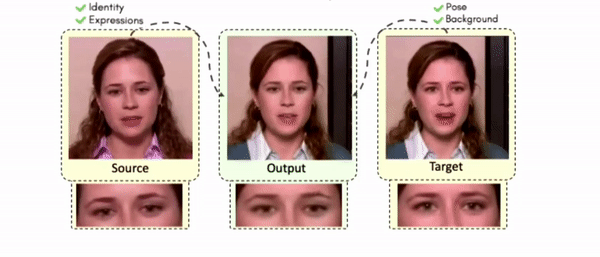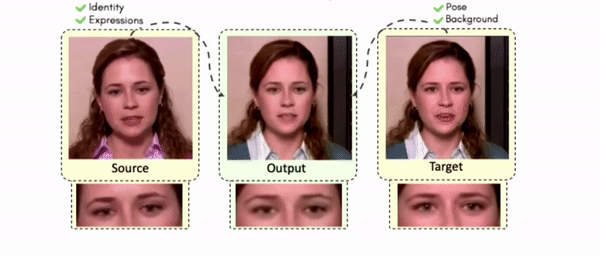
Lipreading is a primary mode of communication for people with hearing loss. However, learning to lipread is not an easy task! Lipreading can be thought of being analogous to "learning a new language" for people without hearing disabilities. People needing this skill undergo formal education in special schools and involve medically trained speech therapists. Other resources like daily interactions also help understand and decipher language solely from lip movements. However, these resources are highly constrained and inadequate for many patients suffering from hearing disabilities. We envision a MOOCs platform for LipReading Training (LRT) for the hearing disabled. We propose a novel approach to automatically generate a large-scale database for developing an LRT MOOCs platform. We use SOTA text-to-speech (TTS) models and talking head generators like Wav2Lip to generate training examples automatically. Wav2Lip requires driving face videos and driving speech segments (generated from TTS in our case) to generate lip-synced talking head videos according to driving speech. It preserves the head pose, background, identity, and distance of the person from the camera while modifying only the lip movements. Our approach can exponentially increase the amount of online content on the LRT platforms in an automated and cost-effective manner. It can also seamlessly increase the vocabulary and the number of speakers in the database.
Test Design
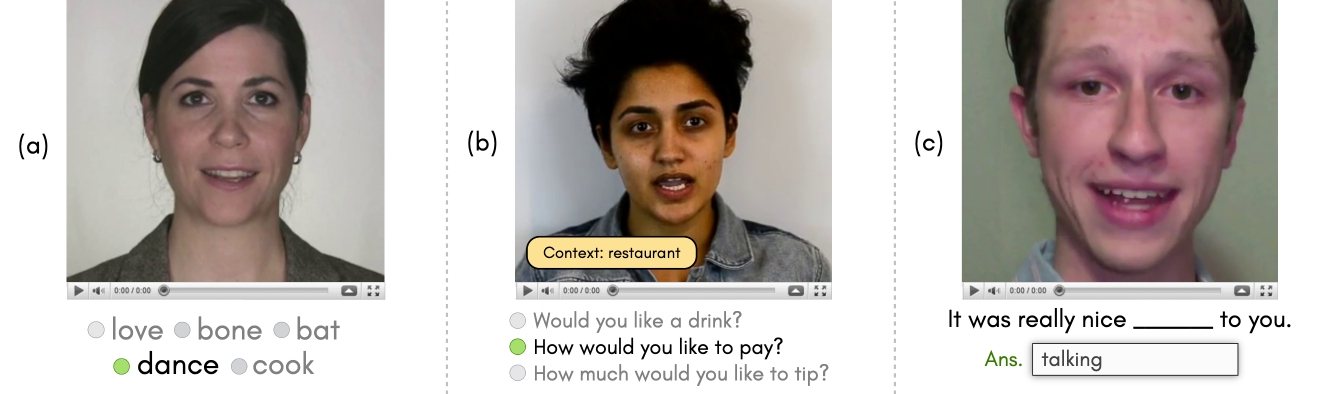
Lipreading is an involved process of recognizing speech from visual cues - the shape formed by the lips, teeth, and tongue. A lipreader may also rely on several other factors, such as the context of the conversation, familiarity with the speaker, vocabulary, and accent. Thus, taking inspiration from lipreading.org and readourlips.ca, we define three lipreading protocols for conducting a user study to evaluate the viability of our platform - (1) lipreading on isolated words (WL), (2) lipreading sentences with context (SL), and (3) lipreading missing words in sentences (MWIS). These protocols rely on a lipreader's vocabulary and the role that semantic context plays in a person's ability to lipread. In word-level (WL) lipreading, the user is presented with a video of an isolated word being spoken by a talking head, along with multiple choices and one correct answer. When a video is played on the screen, the user must respond by selecting a single response from the provided multiple choices. Visually similar words (homophenes) are placed as options in the multiple choices to increase the difficulty of the task. The difficulty can be further increased by testing for difficult words - difficulty associated with the word to lipread. In sentence-level (SL) lipreading, the users are presented with (1) videos of talking heads speaking entire sentences and (2) the context of the sentences. The context acts as an additional cue to the mouthing of sentences and is meant to simulate practical conversations in a given context. In lipreading missing words in sentences (MWIS), the participants watch videos of sentences spoken by a talking head with a word in the sentence masked. Unlike SL, the users are not provided with any additional sentence context. Lip movements are an ambiguous source of information due to the presence of homophenes. This exercise thus aims to use the context of the sentence to disambiguate between multiple possibilities and guess the correct answer.
User Study
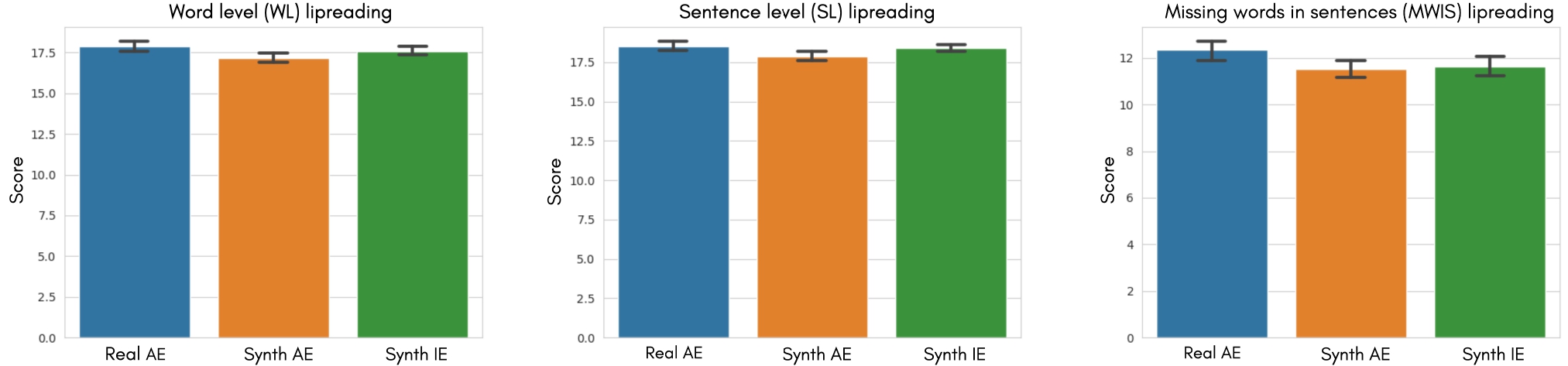
We conduct statistical analysis to verify (T1) If the lipreading performance of the users remains comparable across the real and synthetic videos generated using our pipeline. Through this, we will validate the viability of our proposed pipeline as an alternative to the existing online lipreading training platforms. (T2) If the users are more comfortable lipreading in their native accent/language than in a foreign accent/language. This would validate the need for bootstrapping lipreading training platforms in multiple languages/accents across the globe. The mean user performance on the three lipreading protocols are shown as standard errors of the mean.
Citation
@misc{agarwal2023lrt,
doi = {10.48550/ARXIV.2208.09796},
url = {https://arxiv.org/abs/2208.09796},
author = {Agarwal, Aditya and Sen, Bipasha and Mukhopadhyay, Rudrabha and Namboodiri, Vinay and Jawahar, C. V.},
keywords = {Computer Vision and Pattern Recognition (cs.CV)},
title = {Towards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale},
publisher = {IEEE/CVF Winter Conference on Applications of Computer Vision},
year = {2023},
}