Abstract
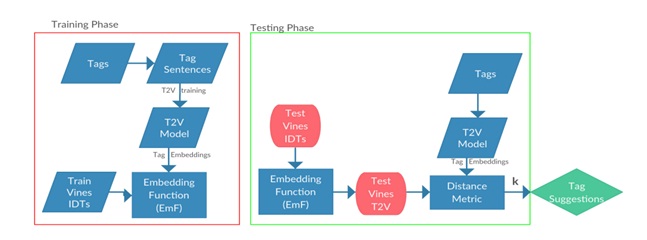
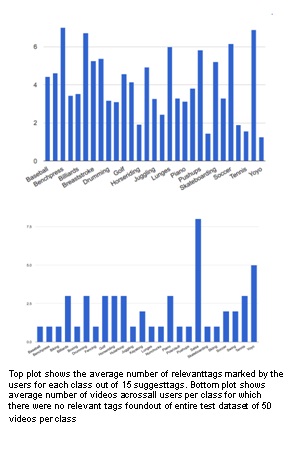
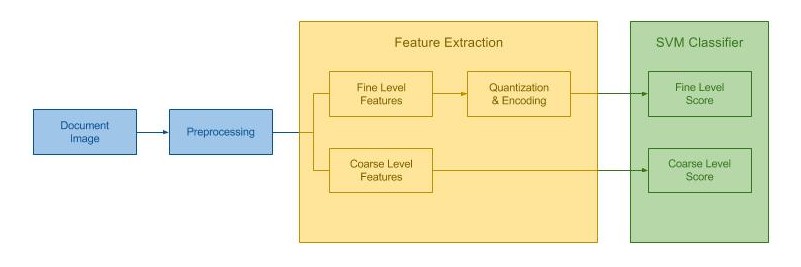
Person recognition methods that use multiple body regions have shown significant improvements over traditional face-based recognition. One of the primary challenges in full-body person recognition is the extreme variation in pose and view point. In this work, (i) we present an approach that tackles pose variations utilizing multiple models that are trained on specific poses, and combined using pose-aware weights during testing. (ii) For learning a person representation, we propose a network that jointly optimizes a single loss over multiple body regions. (iii) Finally, we introduce new benchmarks to evaluate person recognition in diverse scenarios and show significant improvements over previously proposed approaches on all the benchmarks including the photo album setting of PIPA.
Links
Citation
@InProceedings{vijaycvpr15,
author = "Vijay Kumar and Anoop Namboodiri and and Manohar Paluri and Jawahar, C.~V.",
title = "Pose-Aware Person Recognition",
booktitle = "Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition",
year = "2017"
}
References
1. N. Zhang et al., Beyond Fronta Faces: Improving Person Recognition using Multiple Cues, CVPR 2014.
2. Oh et al., Person Recognition in Personal Photo Collections, ICCV 2015.
3. Li et al., A Multi-lvel Contextual Model for Person Recognition in Photo Albums, CVPR 2016.
4. Ozerov et al., On Evaluating Face Tracks in Movies, ICIP 2013.
Acknowledgements
Vijay Kumar is partly supported by TCS PhD Fellowship 2012.
Contact
For any comments and suggestions, please email Vijay atCopyright Notice
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.