Audio-Visual Speech Super-Resolution
Rudrabha Mukhopadhyay*, Sindhu B Hegde* , Vinay Namboodiri and C.V. Jawahar
IIIT Hyderabad Univ. of Bath
BMVC, 2021 (Oral)
[ Code ] | [ Demo Video ]
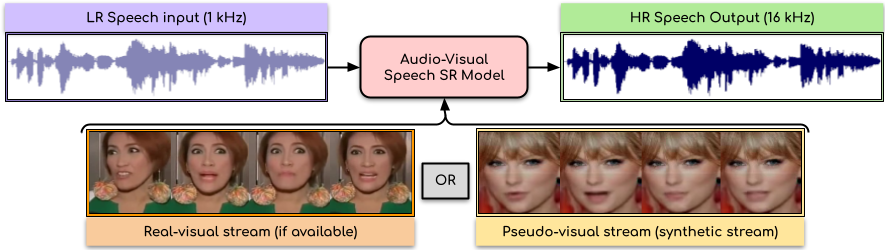
We present an audio-visual model for super-resolving very low-resolution speech inputs (example, 1kHz) at large scale-factors. In contrast to the existing audio-only speech super-resolution approaches, our method benefits from the visual stream, either the real-visual stream (if available), or the generated visual stream from our pseudo-visual network.
Abstract
In this paper, we present an audio-visual model to perform speech super-resolution at large scale-factors (8x and 16x). Previous works attempted to solve this problem using only the audio modality as input and thus were limited to low scale-factors of 2x and 4x. In contrast, we propose to incorporate both visual and auditory signals to super-resolve speech of sampling rates as low as 1kHz. In such challenging situations, the visual features assist in learning the content and improves the quality of the generated speech. Further, we demonstrate the applicability of our approach to arbitrary speech signals where the visual stream is not accessible. Our "pseudo-visual network" precisely synthesizes the visual stream solely from the low-resolution speech input. Extensive experiments and the demo video illustrate our method's remarkable results and benefits over state-of-the-art audio-only speech super-resolution approaches.
Paper

Demo
--- COMING SOON ---
Contact
- Rudrabha Mukhopadhyay -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Sindhu Hegde -
This email address is being protected from spambots. You need JavaScript enabled to view it.