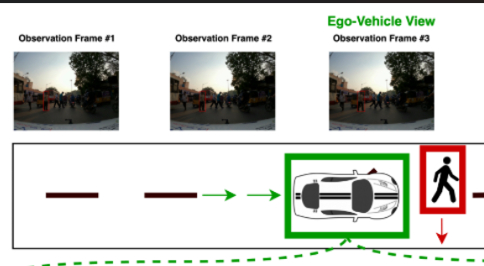
 PedestrianQA : A Benchmark for Vision-Language Models on Pedestrian Intention and Trajectory Prediction
PedestrianQA : A Benchmark for Vision-Language Models on Pedestrian Intention and Trajectory Prediction People Involved : Naman Mishra, Shankar Gangisetty, and C V Jawahar
Pedestrian intention and trajectory prediction are critical for the safe deployment of autonomous
 MOTOR: A Multimodal Dataset for Two-Wheeler Rider Behavior Understanding
MOTOR: A Multimodal Dataset for Two-Wheeler Rider Behavior Understanding
People Involved : Varun Paturkar, Shankar Gangisetty, and C V Jawahar
Two-wheelers account for a disproportionately high share of road fatalities
 Enhancing Driving Visibility via Semantic-Guided Knowledge Distillation Framework for Adverse Weather Removal
Enhancing Driving Visibility via Semantic-Guided Knowledge Distillation Framework for Adverse Weather RemovalPeople Involved : Hanvitha Saraswathi Mukkamala, Shankar Gangisetty, Ananya Kulkarni, Veera Ganesh Yalla, and C V Jawahar
Adverse weather such as rain, haze, and low light severely degrades visual perception
 DriveSafe: A Framework for Risk Detection and Safety Suggestions in Driving Scenarios
DriveSafe: A Framework for Risk Detection and Safety Suggestions in Driving Scenarios
People Involved : Sainithin Artham, Shankar Gangisetty, Avijit Dasgupta, and C V Jawahar
Comprehensive situational awareness is essential for autonomous vehicles operating
 TexTAR – Textual Attribute Recognition in Multi-domain and Multi-lingual Document Images
TexTAR – Textual Attribute Recognition in Multi-domain and Multi-lingual Document Images
People Involved : Rohan Kumar, Jyothi Swaroopa Jinka, and Ravi Kiran Sarvadevabhatla
A deep network for detecting text attributes (bold, italic, underlined, etc.) in document images
 Distilling What and Why: Enhancing Driver Intention Prediction with MLLMs
Distilling What and Why: Enhancing Driver Intention Prediction with MLLMs
People Involved : Sainithin Artham, Avijit Dasgupta, Shankar Gangisetty, and C. V. Jawahar
Illustration of a driving scenario where the ADAS vehicle predicts a left lane change (what) to avoid slower traffic ahead (why).
 IndicDLP : A Foundational Dataset for Multi-Lingual and Multi-Domain Document Layout Parsing
IndicDLP : A Foundational Dataset for Multi-Lingual and Multi-Domain Document Layout Parsing
People Involved : Oikantik Nath, Sahithi Kukkala, Mitesh Khapra, and Ravi Kiran Sarvadevabhatla
Document layout analysis is essential for downstream tasks such as information retrieval, extraction, OCR, and digitization.
 Sketchtopia: A Dataset and Foundational Agents for Benchmarking Asynchronous Multimodal Communication with Iconic Feedback
Sketchtopia: A Dataset and Foundational Agents for Benchmarking Asynchronous Multimodal Communication with Iconic Feedback People Involved : Mohd Hozaifa khan and Ravi Kiran Sarvadevabhatla
A new multimodal dataset and foundational agents for exploring goal-driven asynchronous collaboration through Pictionary.
 RoadSocial : A Diverse VideoQA Dataset and Benchmark for Road Event Understanding from Social Video Narratives
RoadSocial : A Diverse VideoQA Dataset and Benchmark for Road Event Understanding from Social Video NarrativesPeople Involved : Sainithin Artham, Shankar Gangisetty, Avijit Dasgupta, and Ravi Kiran Sarvadevabhatla
RoadSocial is a large-scale, diverse VideoQA dataset tailored for generic road event understanding from social media narratives.
 Towards Safer and Understandable Driver Intention Predictions
Towards Safer and Understandable Driver Intention Predictions
People Involved : Mukilan Karuppasamy , Shankar Gangisetty, Shyam Nanadan and C V Jawahar
llustration of an AD scenario for the DIP task. An AD system may intend to take a left turn while encountering a parked or slow-moving vehicle at the turn. Existing DIP models, lacking HCI understanding, might fail to anticipate the obstacle, leading to a potential collision.
 Pedestrian Intention and Trajectory Prediction in Unstructured Traffic Using IDD-PeD
Pedestrian Intention and Trajectory Prediction in Unstructured Traffic Using IDD-PeD
People Involved : Ruthvik Bokkasam, Shankar Gangisetty, A. H. Abdul Hafez and C V Jawahar
With the rapid advancements in autonomous driving, accurately predicting pedestrian behavior has become essential for ensuring safety in complex and unpredictable traffic conditions. The growing interest in this challenge highlights the need for comprehensive datasets that capture unstructured environments, enabling the development of more robust prediction models to enhance pedestrian safety and vehicle navigation. In this paper,
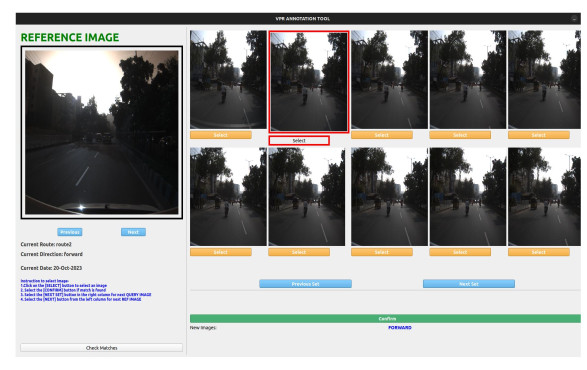 Visual Place Recognition in Unstructured Driving Environments
Visual Place Recognition in Unstructured Driving Environments
People Involved : Utkarsh Rai, Shankar Gangisetty, A. H. Abdul Hafez, Anbumani Subramanian and C V Jawahar
The problem of determining geolocation through visual inputs, known as Visual Place Recognition (VPR), has attracted significant attention in recent years owing to its potential applications in autonomous self-driving systems.
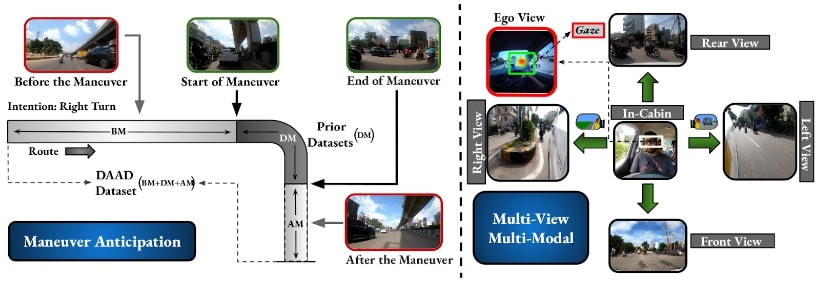 Early Anticipation of Driving Maneuvers
Early Anticipation of Driving Maneuvers
People Involved : Abdul Wasi, Shankar Gangisetty, Shyam Nanadan and C V Jawahar
Prior works have addressed the problem of driver intention prediction (DIP) to identify maneuvers post their onset. On the other hand, early anticipation is equally important in scenarios that demand a preemptive response before a maneuver begins.
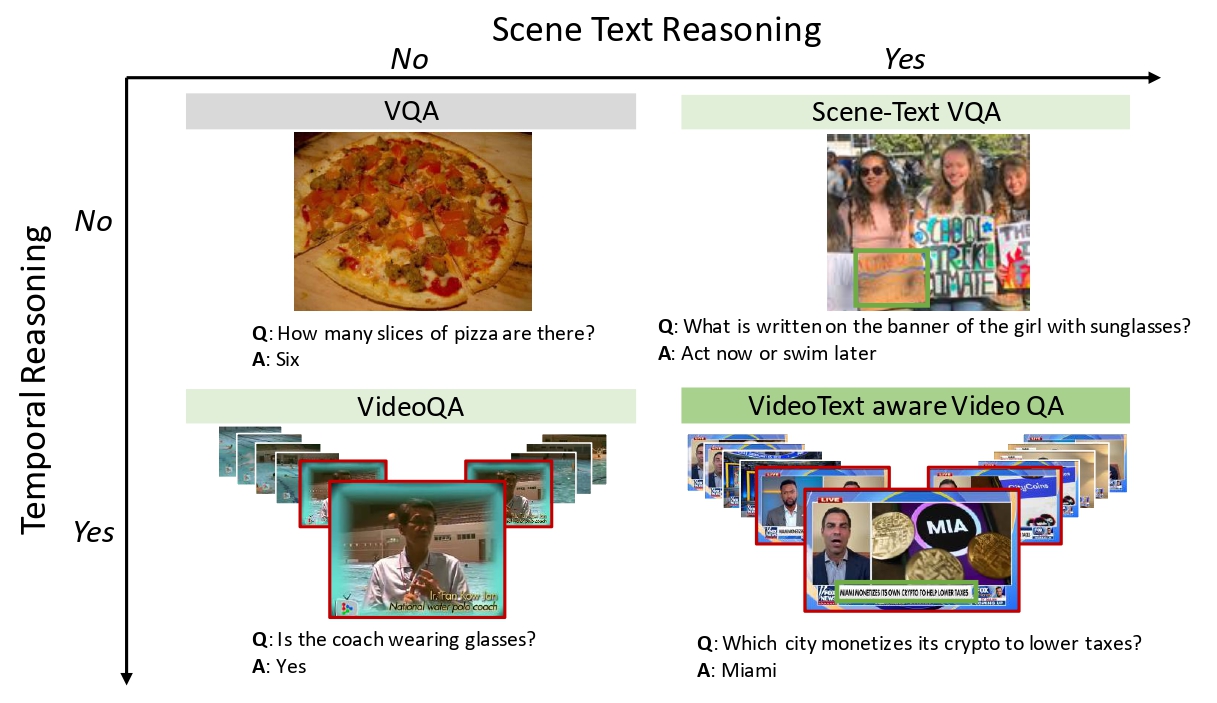 Watching the News: Towards VideoQA Models that can Read
Watching the News: Towards VideoQA Models that can Read
People Involved : Soumya Jahagirdar, Minesh Mathew, Dimosthenis Karatzas, C. V. Jawahar
Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisationcues to the reasoning process.
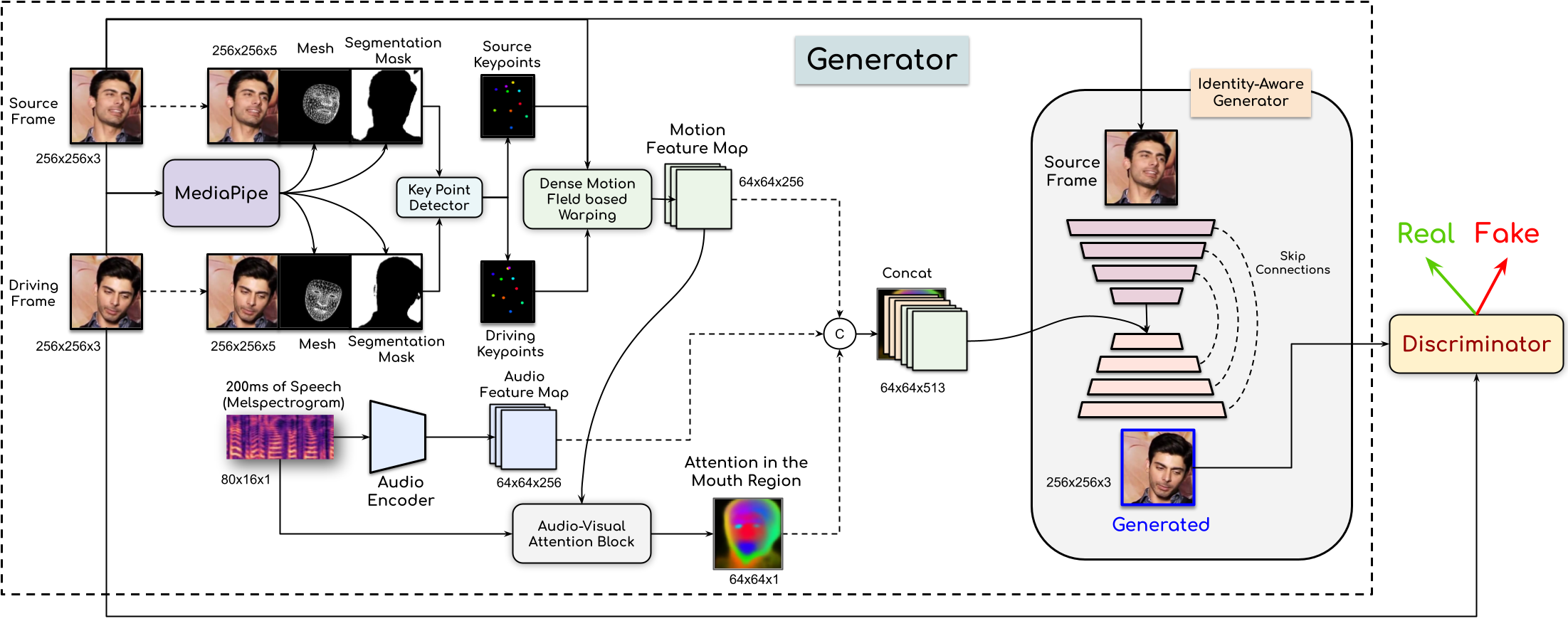
People Involved : Madhav Agarwal, Rudrabha Mukhopadhyay, Vinay Namboodiri and C.V. Jawahar
In this paper, This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region.
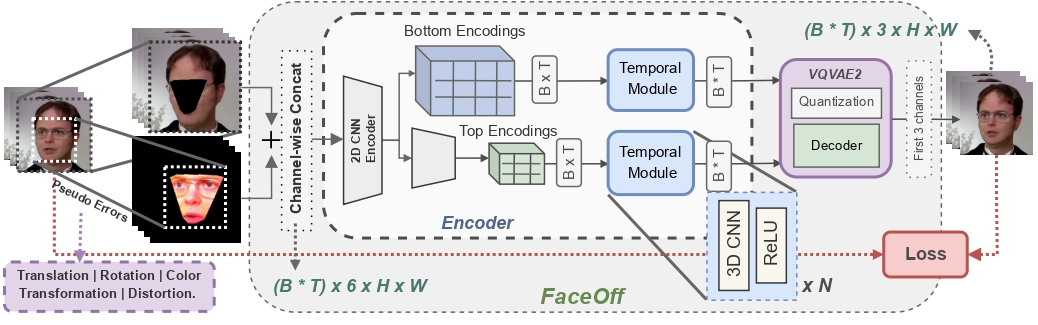 FaceOff: A Video-to-Video Face Swapping System
FaceOff: A Video-to-Video Face Swapping System
People Involved : Aditya Agarwal*, Bipasha Sen*, Rudrabha Mukhopadhyay, Vinay P Namboodiri, C. V. Jawahar
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology,
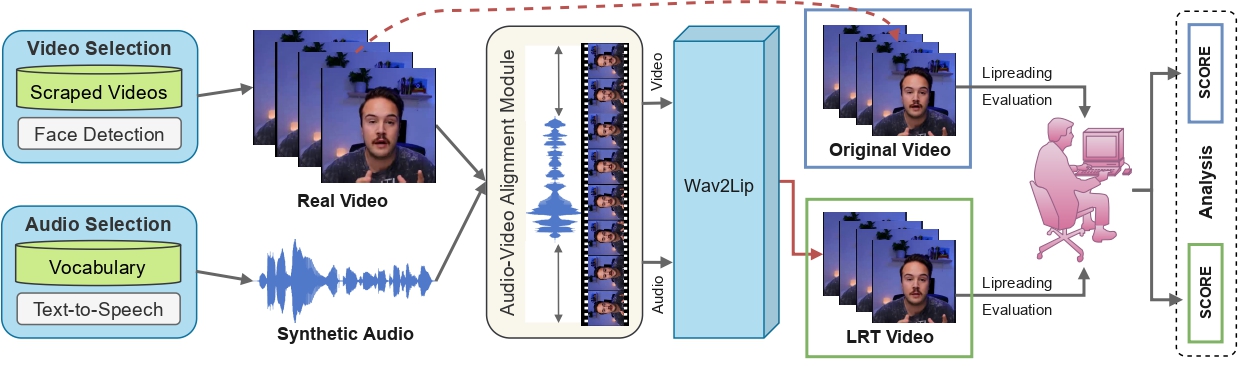 Towards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
Towards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
People Involved : Aditya Agarwal*, Bipasha Sen*, Rudrabha Mukhopadhyay, Vinay P Namboodiri, C. V. Jawahar
Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging.
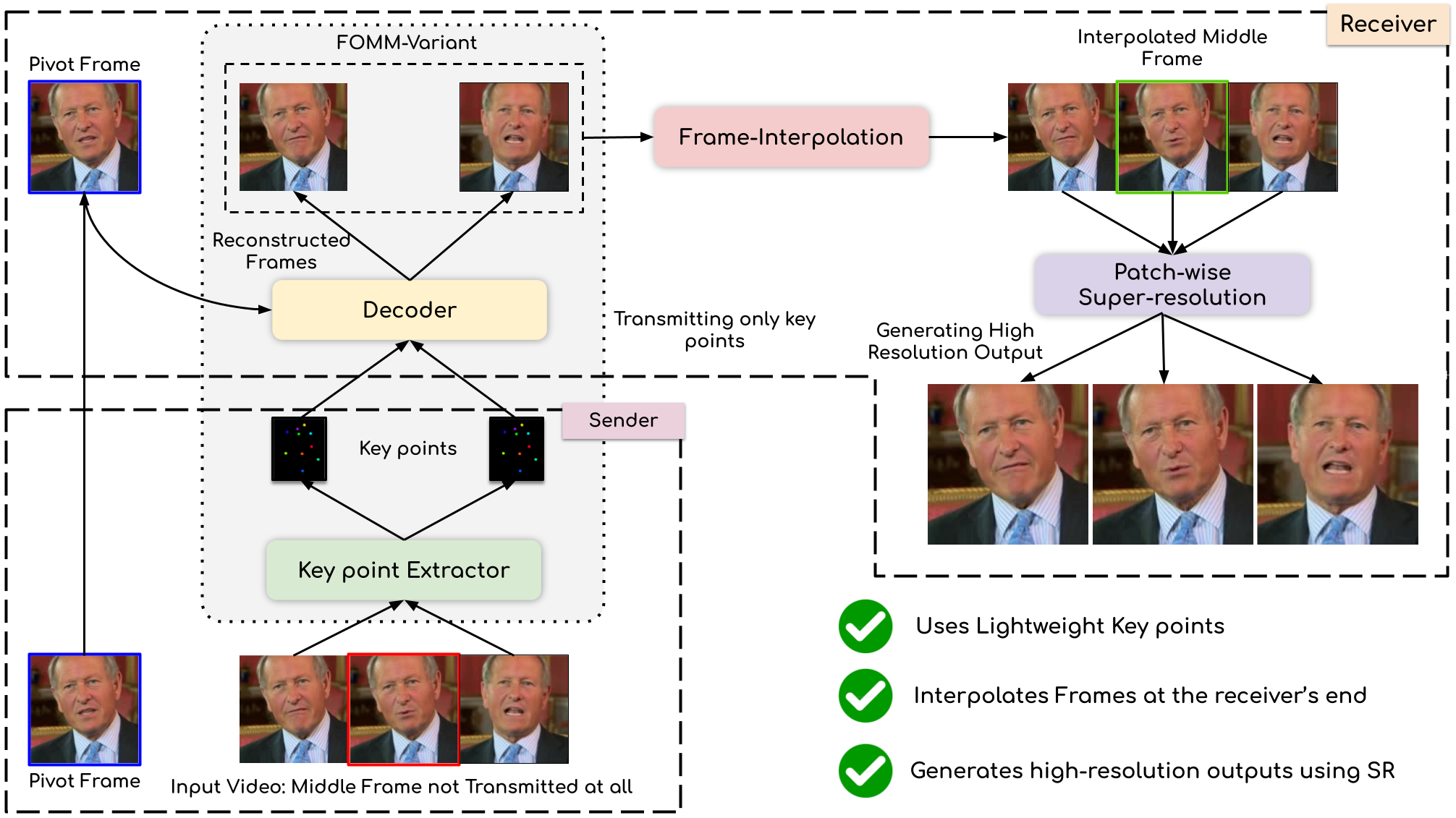 Compressing Video Calls using Synthetic Talking Heads
Compressing Video Calls using Synthetic Talking Heads
People Involved : Madhav Agarwal, Anchit Gupta, Rudrabha Mukhopadhyay, Vinay Namboodiri and C.V. Jawahar
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver.
People Involved : Nikhil Bansal , Kartik Gupta , Kiruthika Kannan , Sivani Pentapati, and Ravi Kiran Sarvadevabhatla
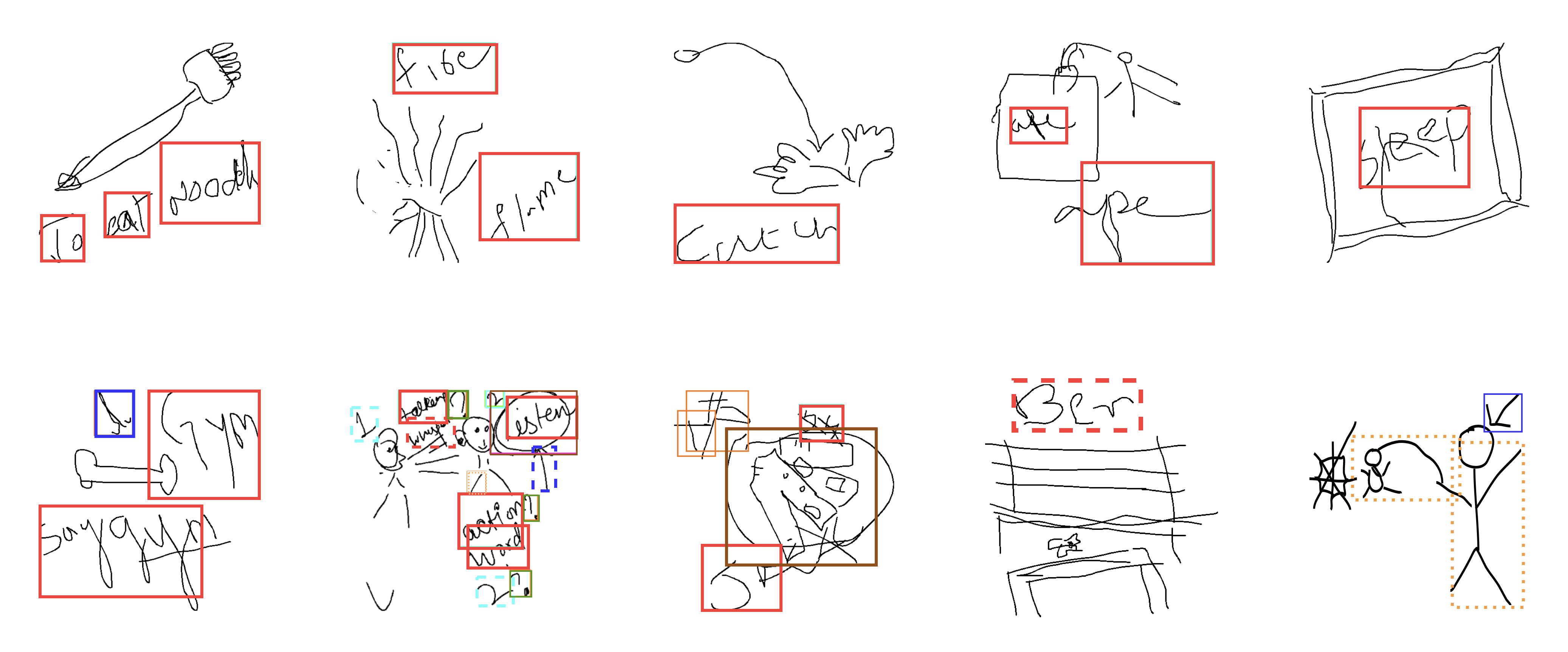
Pictionary, the popular sketch-based game forbids drawer from writing text(atypical content) on canvas. Intervention of such rule violations is impractical and not scalable in web-based online setting of this game involving large number of multiple concurrent sessions. Apart from malicious game play, atypical sketch content can also exist in non-malicious, benign scenarios. For instance, the Drawer may choose to draw arrows and other such icons to attract the Guesser’s attention and provide indirect hints regarding the target word. Accurately localizing such activities can aid statistical learning approaches which associate sketch-based representations with corresponding target words.
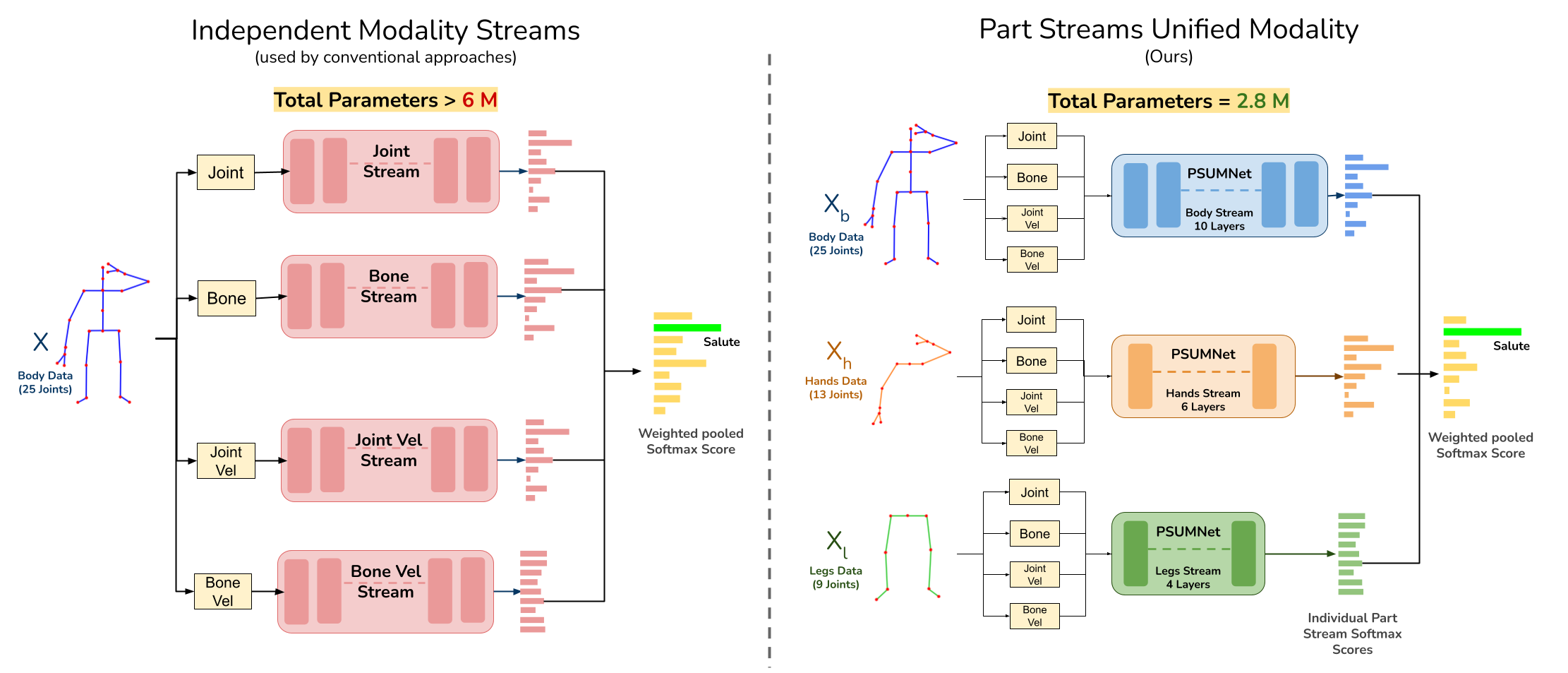 PSUMNet: Unified Modality Part Streams are All You Need for Efficient Pose-based Action Recognition
PSUMNet: Unified Modality Part Streams are All You Need for Efficient Pose-based Action Recognition
People Involved : Neel Trived, Ravi Kiran Sarvadevabhatla
Pose-based action recognition is predominantly tackled by approaches which treat the input skeleton in a monolithic fashion, i.e. joints in the pose tree are processed as a whole. However, such approaches ignore the fact that action categories are often characterized by localized action dynamics involving only small subsets of part joint groups involving hands ...
 Unsupervised Audio-Visual Lecture Segmentation
Unsupervised Audio-Visual Lecture Segmentation
People Involved : Darshan Singh S*, Anchit Gupta*, C.V. Jawahar and Makarand Tapaswi
This Over the last decade, online lecture videos have become increasingly popular and have experienced a meteoric rise during the pandemic. However, video-language research has primarily focused on instructional videos or movies, and tools to help students navigate the growing online lectures are lacking....
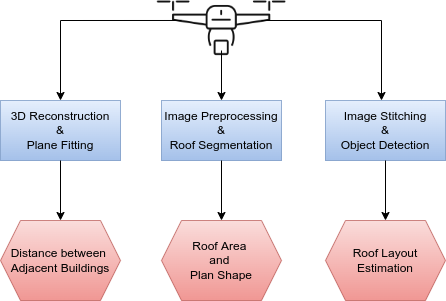 UAV-based Visual Remote Sensing for Automated Building Inspection (UVRSABI)
UAV-based Visual Remote Sensing for Automated Building Inspection (UVRSABI)
People Involved : Kushagra Srivastava , Dhruv Patel , Aditya Kumar Jha , Mohit Kumar Jha, Jaskirat Singh, Ravi Kiran Sarvadevabhatla, Harikumar Kandath, Pradeep Kumar Ramancharla, K. Madhava Krishna,
We automate the inspection of buildings through UAV-based image data collection and a post-processing module to infer and quantify the details which helps in avoiding manual inspection, reducing the time and cost.
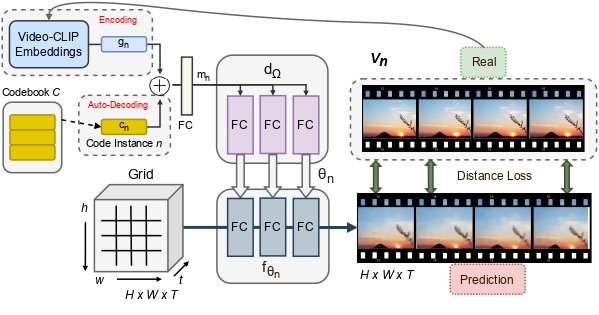 INR-V: A Continuous Representation Space for Video-based Generative Tasks
INR-V: A Continuous Representation Space for Video-based Generative Tasks
People Involved : Bipasha Sen, Aditya Agarwal, Vinay P Namboodiri and C.V. Jawahar
Generating videos is a complex task that is accomplished by generating a set of temporally coherent images frame-by-frame. This limits the expressivity of videos to only image-based operations on the individual video frames needing network designs to obtain temporally coherent trajectories in the underlying image space. We propose INR-V, a video representation network that learns a continuous space for video-based generative tasks.
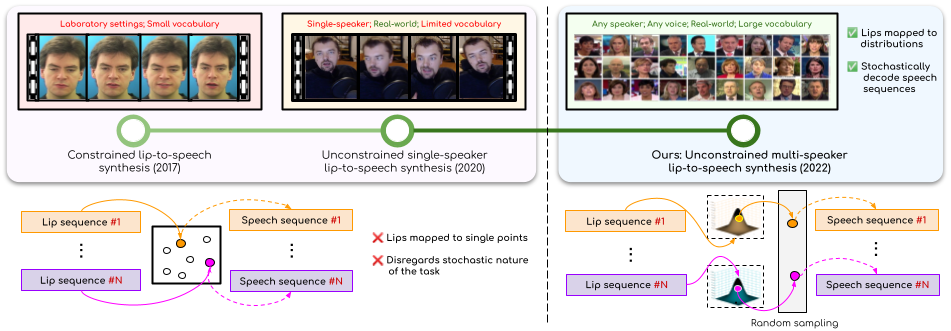 Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
People Involved : Sindhu B Hegde, K R Prajwal, Rudrabha Mukhopadhyay, Vinay Namboodiri and C.V. Jawahar
In this work, we address the problem of generating speech from silent lip videos for any speaker in the wild. In stark contrast to previous works in lip-to-speech synthesis, our work (i) is not restricted to a fixed number of speakers, (ii) does not explicitly impose constraints on the domain or the vocabulary and (iii) deals with videos that are recorded in the wild as opposed to within laboratory settings.
 Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
People Involved : Sindhu B Hegde, Rudrabha Mukhopadhyay, Vinay Namboodiri and C.V. Jawahar
In this paper, we explore an interesting question of what can be obtained from an 8×8 pixel video sequence. Surprisingly, it turns out to be quite a lot. We show that when we process this 8x8 video with the right set of audio and image priors, we can obtain a full-length, 256x256 video. We achieve this 32x scaling of an extremely low-resolution input using our novel audio-visual upsampling network
 My View is the Best View: Procedure Learning from Egocentric Videos
My View is the Best View: Procedure Learning from Egocentric Videos
People Involved : Siddhant Bansal , Chetan Arora and C.V. Jawahar
Using third-person videos for procedure learning makes the manipulated object small in appearance and often occluded by the actor, leading to significant errors. In contrast, we observe that videos obtained from first-person (egocentric) wearable cameras provide an unobstructed and clear view of the action.
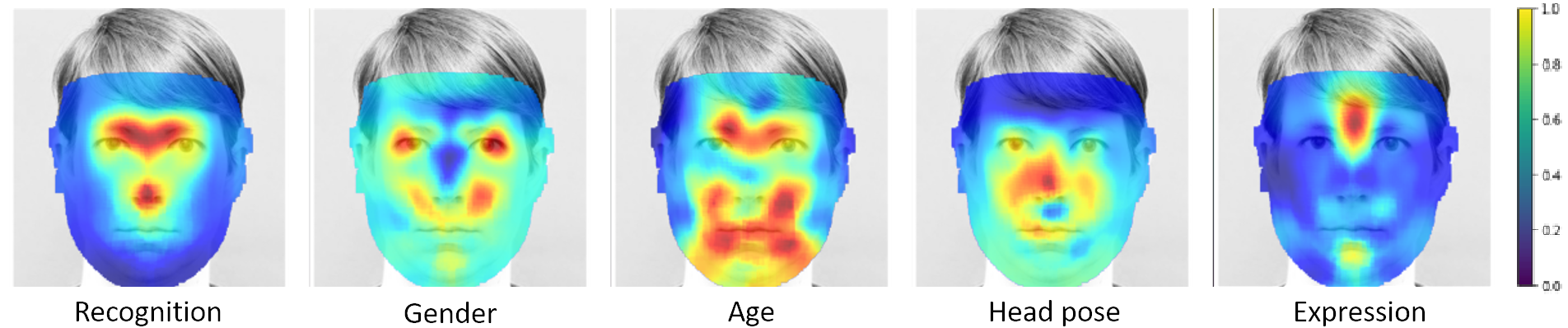 Canonical Saliency Maps: Decoding Deep Face Models
Canonical Saliency Maps: Decoding Deep Face Models
People Involved : Thrupthi Ann John, Vineeth N Balasubramanian and C. V. Jawahar
As Deep Neural Network models for face processing tasks approach human-like performance, their deployment in critical applications such as law enforcement and access control has seen an upswing, where any failure may have far-reaching consequences.
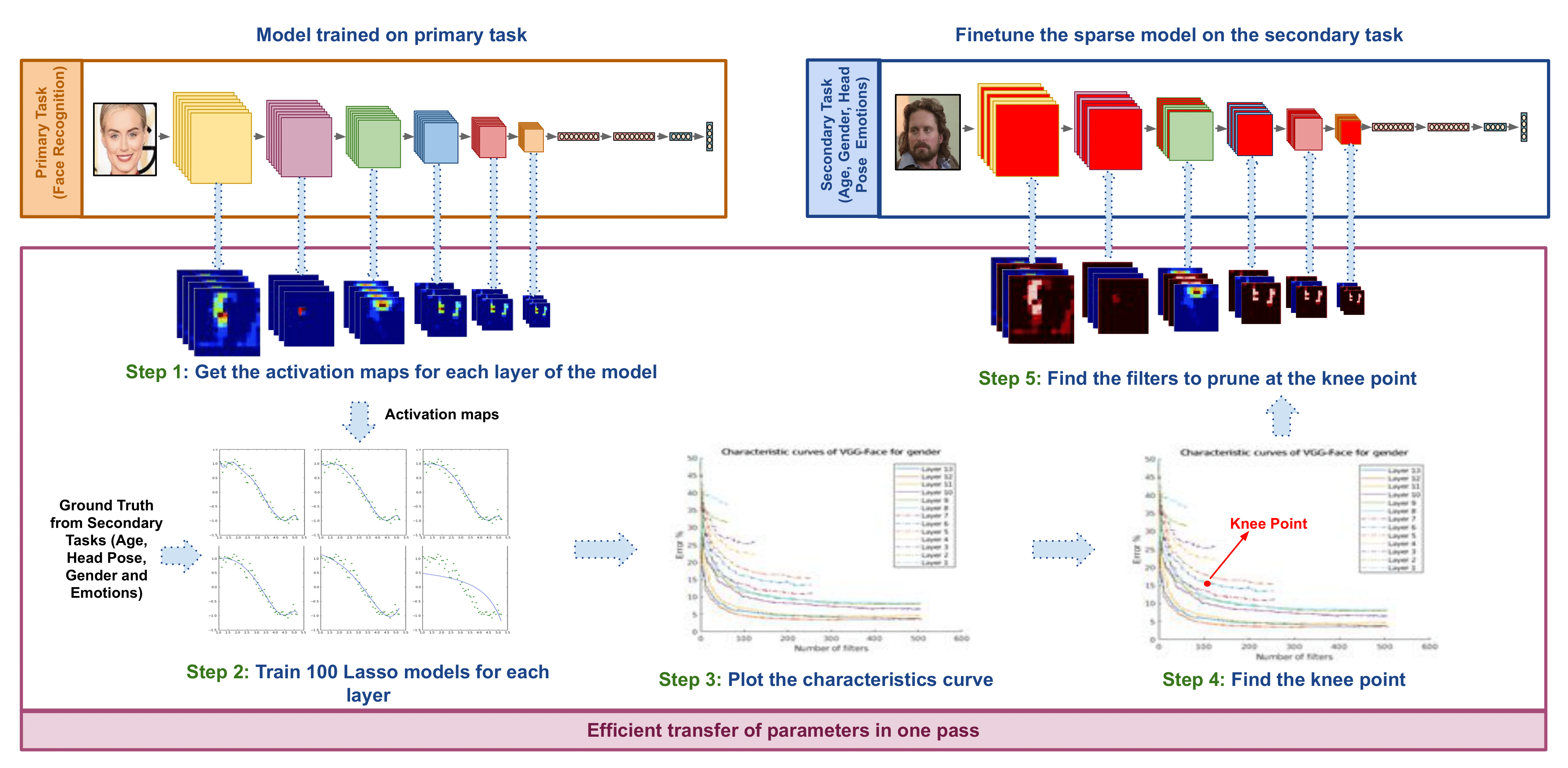 ETL: Efficient Transfer Learning for Face Tasks
ETL: Efficient Transfer Learning for Face Tasks
People Involved : Thrupthi Ann John,Isha Dua, Vineeth N Balasubramanian and C. V. Jawahar
ransfer learning is a popular method for obtaining deep trained models for data-scarce face tasks such as head pose and emotion. However, current transfer learning methods are inefficient and time-consuming as they do not fully account for the relationships between related tasks..
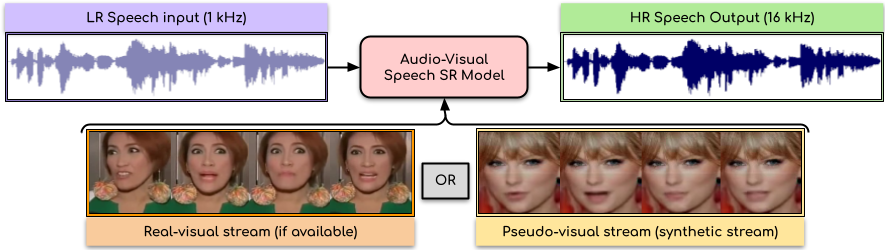 Audio-Visual Speech Super-Resolution
Audio-Visual Speech Super-Resolution
People Involved : Rudrabha Mukhopadhyay, Sindhu Hegde Vinay Namboodiri and C.V. Jawahar
In this paper, we present an audio-visual model to perform speech super-resolution at large scale-factors (8x and 16x). Previous works attempted to solve this problem using only the audio modality as input and thus were limited to low scale-factors of $2\times$ and $4\times$. In contrast, we propose to incorporate both visual and auditory signals to super-resolve speech of sampling rates as low as $1$kHz.
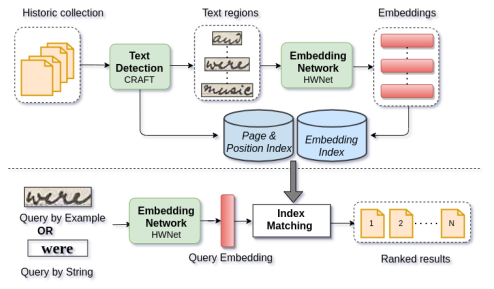 Handwritten Text Retrieval from Unlabeled Collections
Handwritten Text Retrieval from Unlabeled Collections
People Involved : Santhoshini Gongid and C.V. Jawahar
Handwritten documents from communities like cultural heritage, judiciary, and modern journals remain largely unexplored even today. To a great extent, this is due to the lack of retrieval tools for such unlabeled document collections. In this work, we consider such collections and present a simple, robust retrieval framework for easy information access. We achieve retrieval on unlabeled novel collections through invariant features learnt for handwritten text. These feature representations enable zero-shot retrieval for novel queries on unexplored collections.

People Involved : Jobin K.V., Ajoy Mondal, and Jawahar C.V.
Slide presentations are an effective and efficient tool used by the teaching community for classroom communication. However, this teaching model can be challenging for the blind and visually impaired (VI) students. The VI student required a personal human assistance for understand the presented slide. This shortcoming motivates us to design a Classroom Slide Narration System (CSNS) that generates audio descriptions corresponding to the slide content. This problem poses as an image-to-markup language generation task. The initial step is to extract logical regions such as title, text, equation, figure, and table from the slide image.
 3DHumans : High-Fidelity 3D Scans of People in Diverse Clothing Styles
3DHumans : High-Fidelity 3D Scans of People in Diverse Clothing Styles
People Involved :Sai Sagar Jinka , Astitva Srivastava , Chandradeep Pokhariya , Avinash Sharma and P. J. Narayanan
3DHumans dataset provides around 180 meshes of people in diverse body shapes in various garments styles and sizes. We cover a wide variety of clothing styles, ranging from loose robed clothing, like saree (a typical South-Asian dress) to relatively tight fit clothing, like shirts and trousers. Along with the high quality geometry (mesh) and texture map, we also provide registered SMPL's parameters.
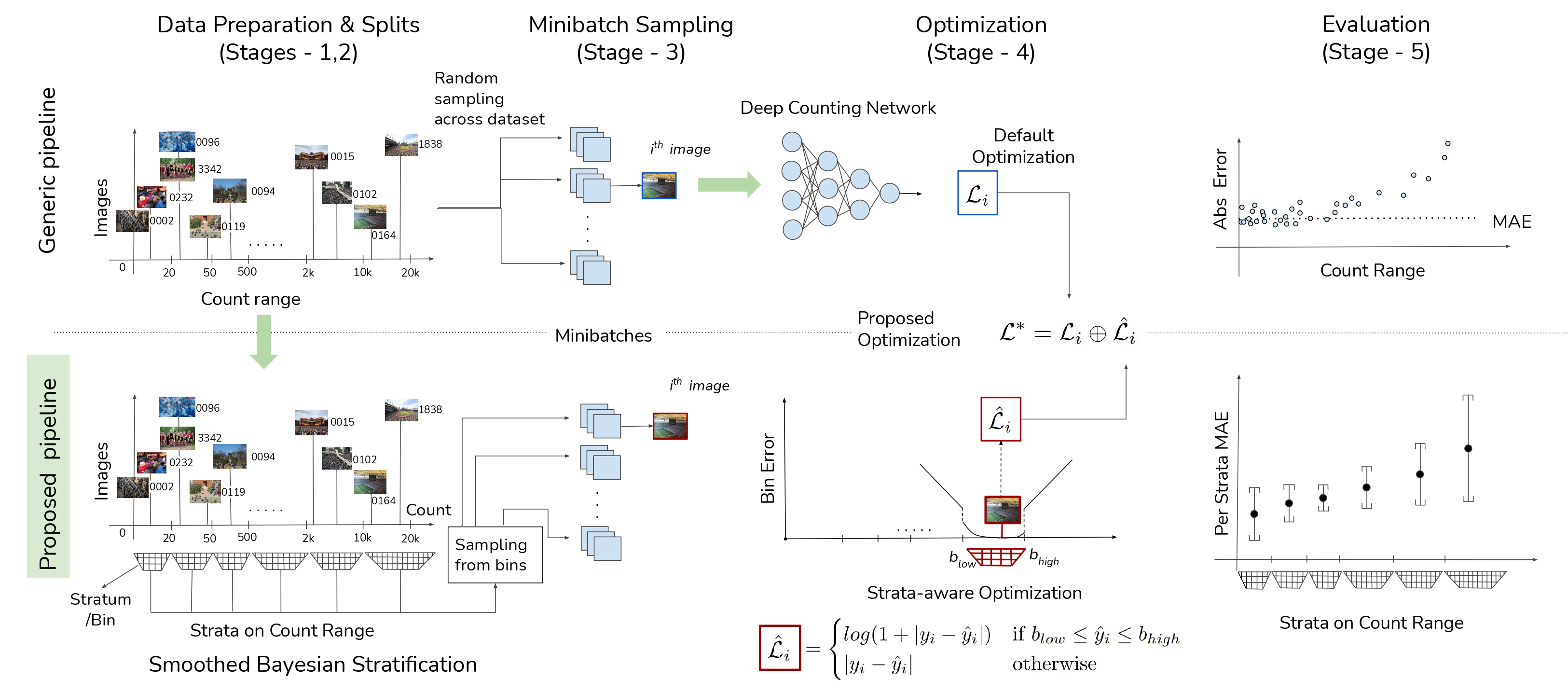 Wisdom of (Binned) Crowds: A Bayesian Stratification Paradigm for Crowd Counting
Wisdom of (Binned) Crowds: A Bayesian Stratification Paradigm for Crowd Counting
People Involved : Sravya Vardhani Shivapuja, Mansi Pradeep Khamkar, Divij Bajaj, Ganesh Ramakrishnan, Ravi Kiran Sarvadevabhatla
Not the paper crowd counting community seems to want, but one it needs right now ! To address serious issues with training and evaluation of deep...
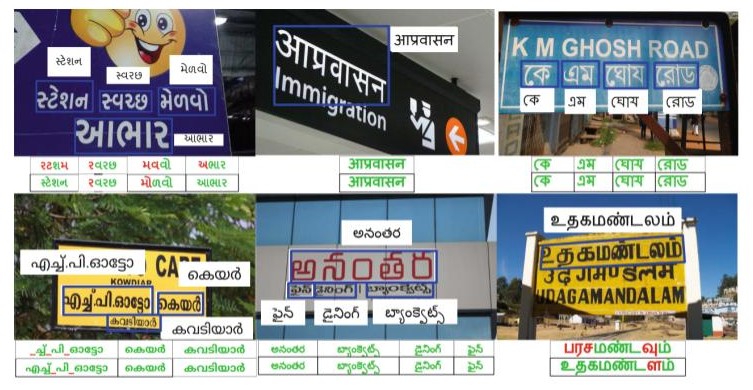 Transfer Learning for Scene Text Recognition in Indian Languages
Transfer Learning for Scene Text Recognition in Indian Languages
People Involved : Sanjana Gunna, Rohit Saluja, and C.V. Jawahar
Scene text recognition in low-resource Indian languages is challenging because of complexities like multiple scripts, fonts, text size, and orientations. In this work, we investigate the power of transfer learning for all the layers of deep scene text recognition networks from English to two common Indian languages.
 Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
People Involved : Sanjana Gunna, Rohit Saluja, and C.V. Jawahar
Scene-text recognition is remarkably better in Latin languages than the non-Latin languages due to several factors like multiple fonts, simplistic vocabulary statistics, updated data generation tools, and writing systems.
People Involved : Aryamaan Jain, Jyoti Sunkara, Ishaan Shah, Avinash Sharma and K S Rajan
Trees are an integral part of many outdoor scenes and are rendered in a wide variety of computer applications like computer games, movies, simulations, architectural models, AR and VR. This has led to increasing demand for realistic, intuitive, lightweight and easy to produce computer-generated trees. The current approaches at 3D tree generation using a library of trees lack variations in structure and are repetitive. This paper presents an extended grammar-based automated solution for 3D tree generation that can model a wide range of species, both Western and Indian. For the foliage, we adopt a particle system approach that models the leaf, its size, orientation and changes.
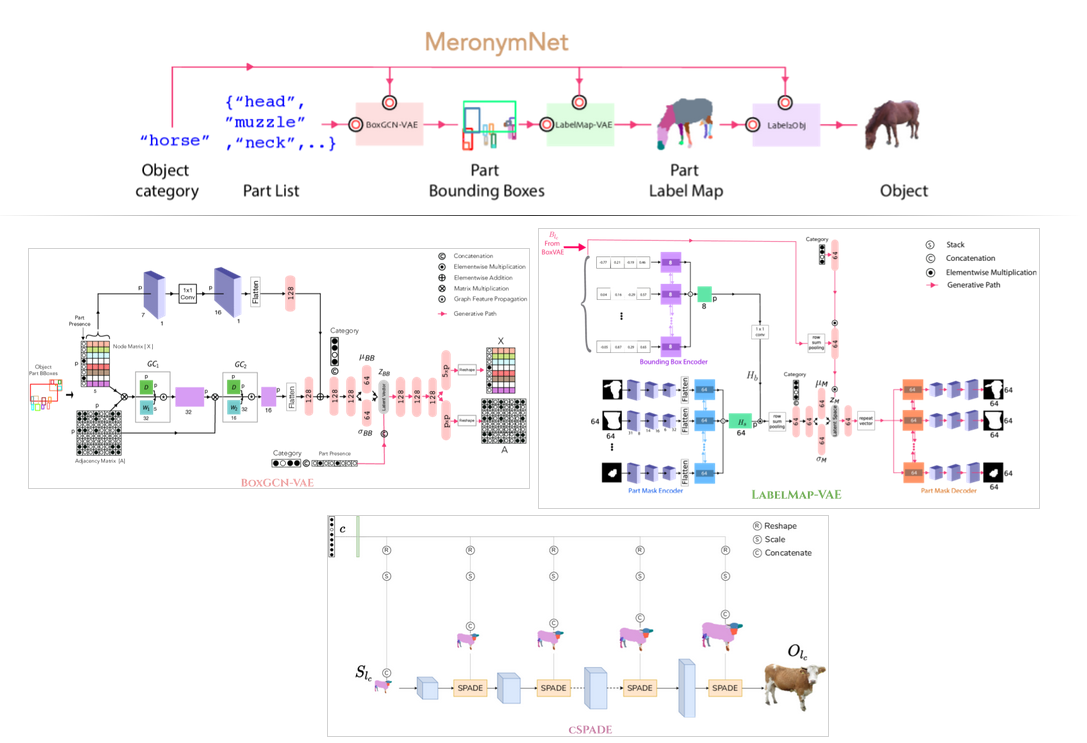 MeronymNet: A Hierarchical Model for Unified and Controllable Multi-Category Object Generation
MeronymNet: A Hierarchical Model for Unified and Controllable Multi-Category Object Generation
People Involved : Rishabh Baghel, Abhishek Trivedi, Tejas Ravichandran, and Ravi Kiran Sarvadevabhatla
We introduce MeronymNet, a novel hierarchical approach for controllable, part-based generation of multi-category objects using a single unified model. We adopt a guided coarse-to-fine strategy involving semantically conditioned generation of bounding box layouts, pixel-level part layouts and ultimately, the object depictions themselves.
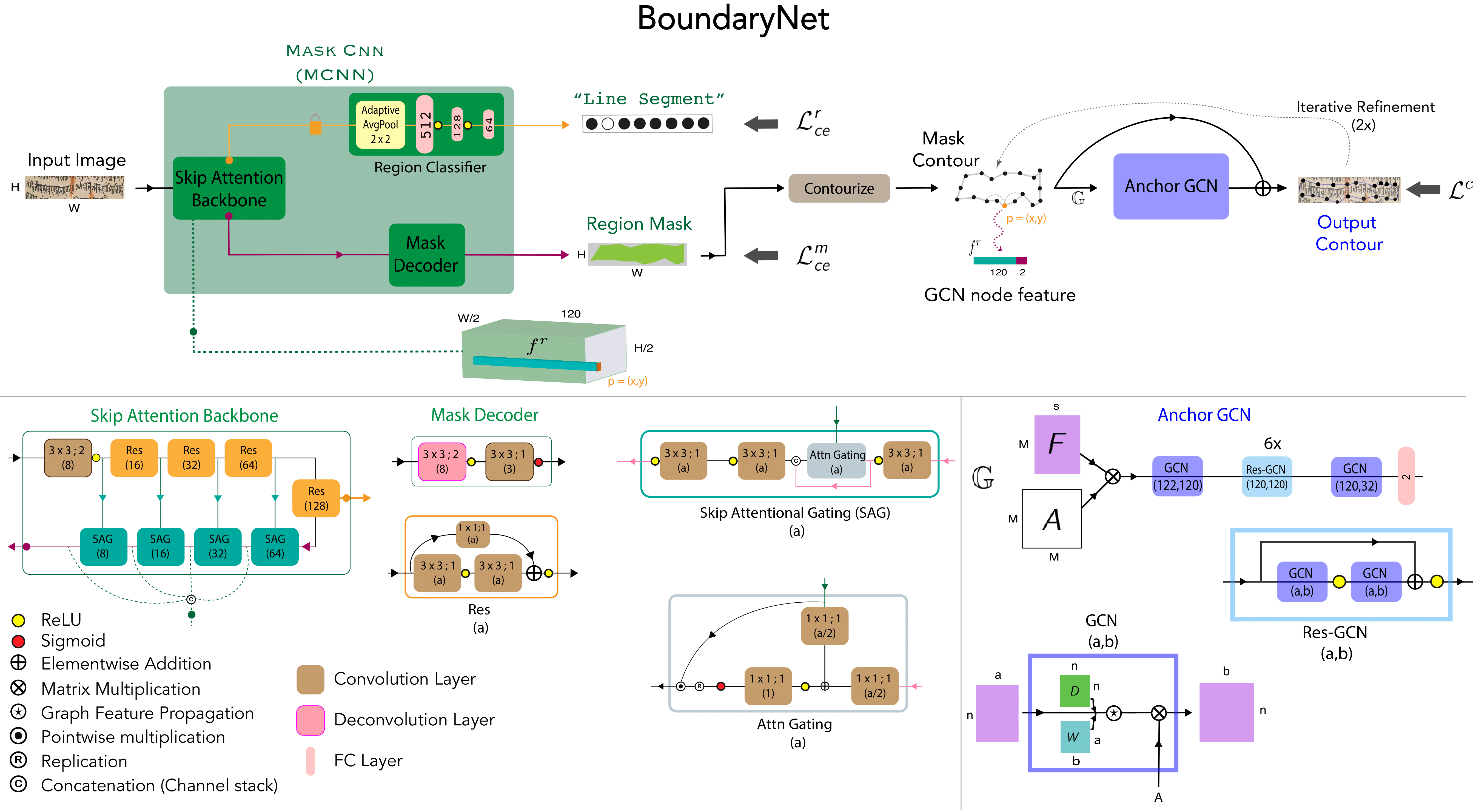
People Involved : Abhishek Trivedi, Ravi Kiran Sarvadevabhatla
A novel resizing-free approach for high-precision semi-automatic layout annotation.
People Involved : Sharan, S P and Aitha, Sowmya and Amandeep, Kumar and Trivedi, Abhishek and Augustine, Aaron, Ravi Kiran Sarvadevabhatla
Introducing (1) Indiscapes2 handwritten manuscript layout dataset - 150% larger than its predecessor Indiscapes (2) PALMIRA - a novel deep network ..
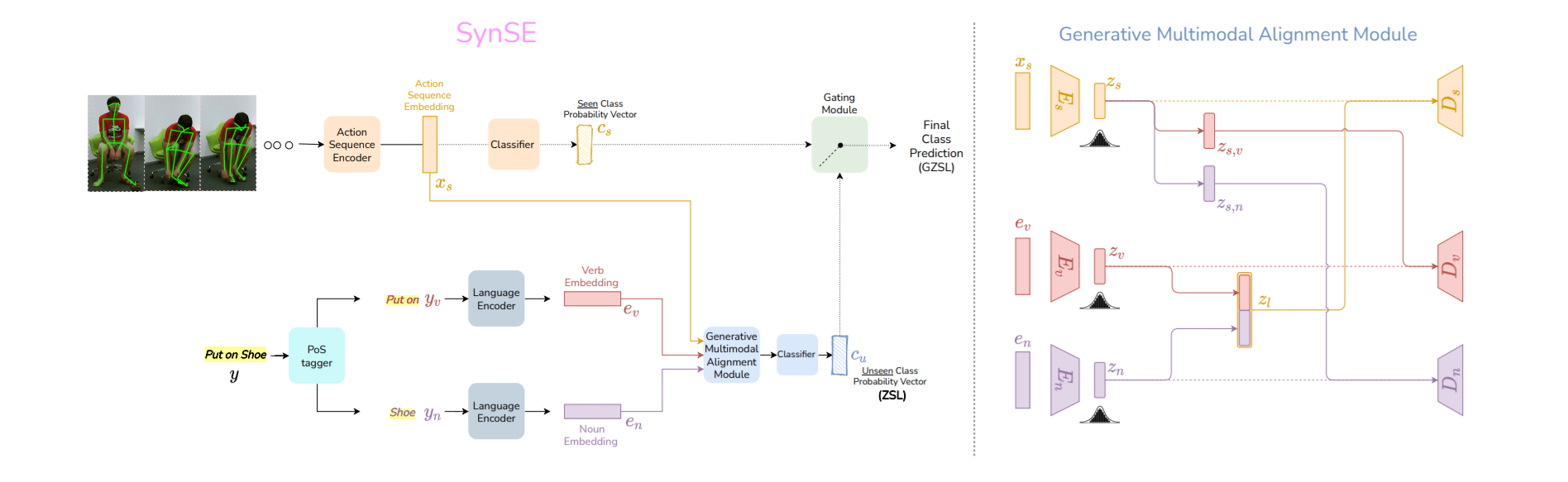 Syntactically Guided Generative Embeddings for Zero Shot Skeleton Action Recognition
Syntactically Guided Generative Embeddings for Zero Shot Skeleton Action Recognition
People Involved : Pranay Gupta, Divyanshu Sharma, Ravi Kiran Sarvadevabhatla
We propose a language-guided approach to enable state of the art performance for the challenging problem of Zero Shot Recognition of human actions.
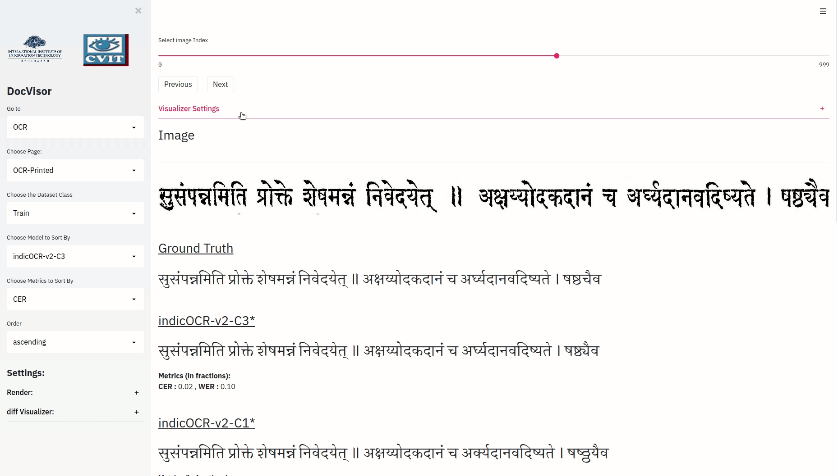 DocVisor: A Multi-purpose Web-based Interactive Visualizer for Document Image Analytics
DocVisor: A Multi-purpose Web-based Interactive Visualizer for Document Image Analytics
People Involved :Khadiravana Belagavi, Pranav Tadimeti, Ravi Kiran Sarvadevabhatla
DocVisor is an open-source visualization tool for document layout analysis. With DocVisor, it is possible to visualize data from three prominent document analysis tasks: Full Document Analysis, OCR and Box-Supervised Region Parsing. DocVisor offers various features such as ground-truth and intermediate output visualization, sorting data by key metrics as well as comparison of outputs from various other models simultaneously.

People Involved : Akshay Praveen Deshpande, Vaishnav Rao Potlapalli, Ravi Kiran Sarvadevabhatla
DocVisor is an open-source visualization tool for document layout analysis. With DocVisor, it is possible to visualize data from three prominent document analysis tasks: Full Document Analysis, OCR and Box-Supervised Region Parsing. DocVisor offers various features such as ground-truth and intermediate output visualization, sorting data by key metrics as well as comparison of outputs from various other models simultaneously.
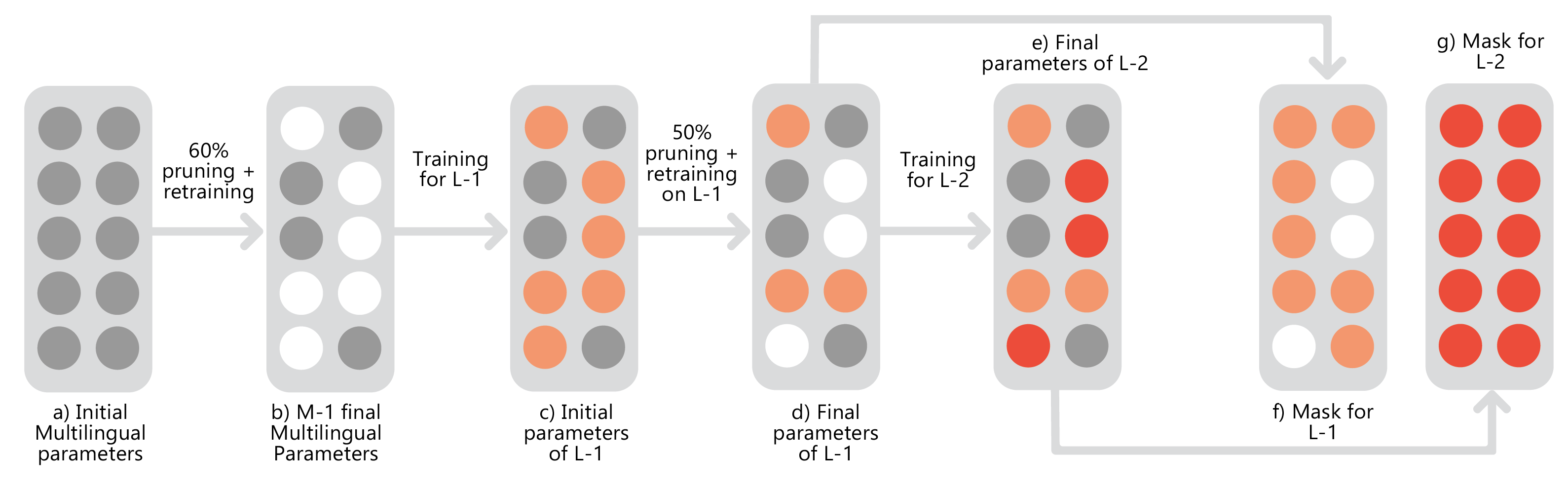
People Involved : Zeeshan Khan, Kartheek Akella , Vinay Namboodiri C.V. Jawahar
This work studies the long-standing problems of model capacity and negative interference in multilingual neural machine translation (MNMT). We use network pruning techniques and observe that pruning 50-70% of the parameters from a trained MNMT model results only in a 0.29-1.98 drop in the BLEU score. Suggesting that there exist large redundancies even in MNMT models.
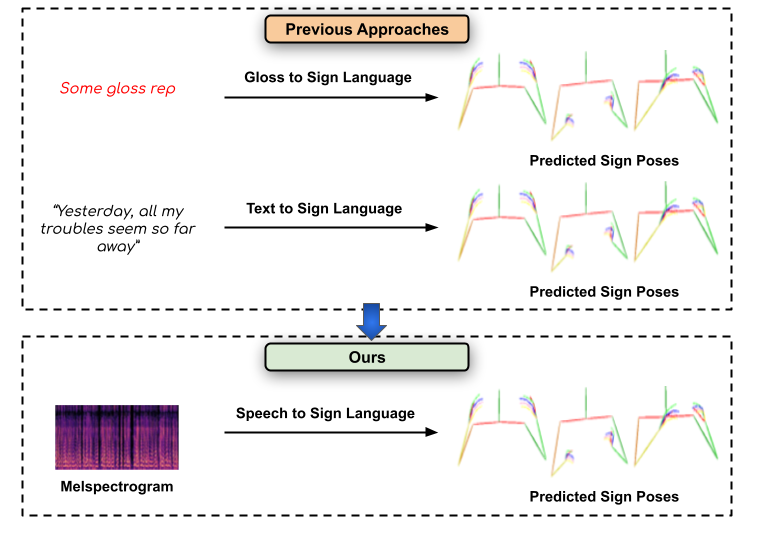 Towards Speech to Sign Language Generation
Towards Speech to Sign Language Generation
People Involved : Parul Kapoor, Rudrabha Mukhopadhyay Sindhu B Hegde , Vinay Namboodiri and C.V. Jawahar
We aim to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss.
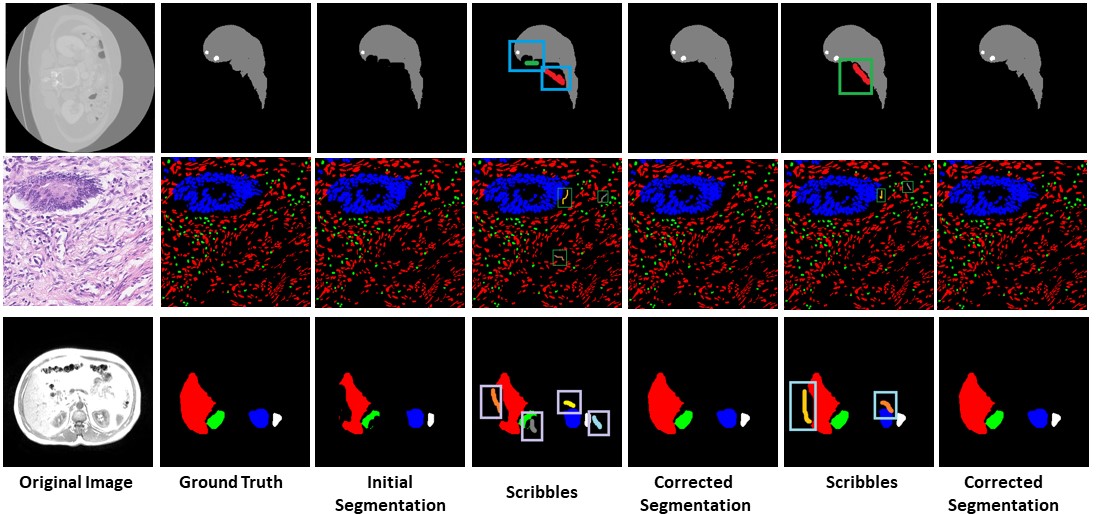 Semi-Automatic Medical Image Annotation
Semi-Automatic Medical Image Annotation
People Involved : Bhavani Sambaturu*, Ashutosh Gupta, C.V. Jawahar and Chetan Arora
Semantic segmentation of medical images is an essential first step in computer-aided diagnosis systems for many applications.
 IIIT-INDIC-HW-WORDS: A Dataset for Indic Handwritten Text Recognition
IIIT-INDIC-HW-WORDS: A Dataset for Indic Handwritten Text Recognition
People Involved : Santhoshini Gongidi, and C V Jawahar
Handwritten text recognition for Indian languages is not yet a well-studied problem. This is primarily due to the unavailability of large annotated datasets in the associated scripts. Existing datasets are small in size. They also use small lexicons. Such datasets are not sufficient to build robust solutions to HTR using modern machine learning techniques. In this work, we introduce a large-scale handwritten dataset for Indic scripts, referred to as the IIIT-INDIC-HW-WORDS dataset.
 Scene Text Recognition in Indian Scripts
Scene Text Recognition in Indian Scripts
People Involved : Minesh Mathew, Mohit Jain and CV Jawahar
This work addresses the problem of scene text recognition in India scripts. As a first step, we benchmark scene text recognition for three Indian scripts - Devanagari, Telugu and Malayalam, using a CRNN model.
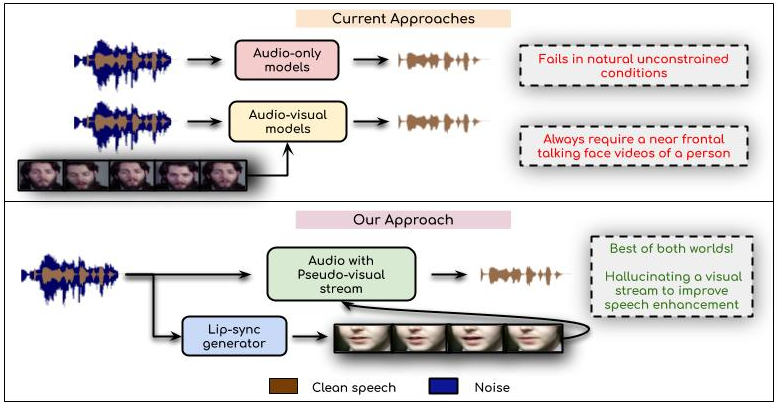 Visual Speech Enhancement Without a Real Visual Stream
Visual Speech Enhancement Without a Real Visual Stream
People Involved : Sindhu Hegde, Prajwal Renukanand, Rudrabha Mukhopadhyay, Vinay Namboodiri and C. V. Jawahar
In this work, we re-think the task of speech enhancement in unconstrained real-world environments. Current state-of-the-art methods use only the audio stream and are limited in their performance in a wide range of real-world noises.
 DGAZE Dataset for driver gaze mapping on road
DGAZE Dataset for driver gaze mapping on road
People Involved : Isha Dua Thrupthi John Riya Gupta and C.V. Jawahar
DGAZE is a new dataset for mapping the driver's gaze onto the road. Currently, driver gaze datasets are collected using eye-tracking hardware which are expensive and cumbersome, and thus unsuited for use during testing
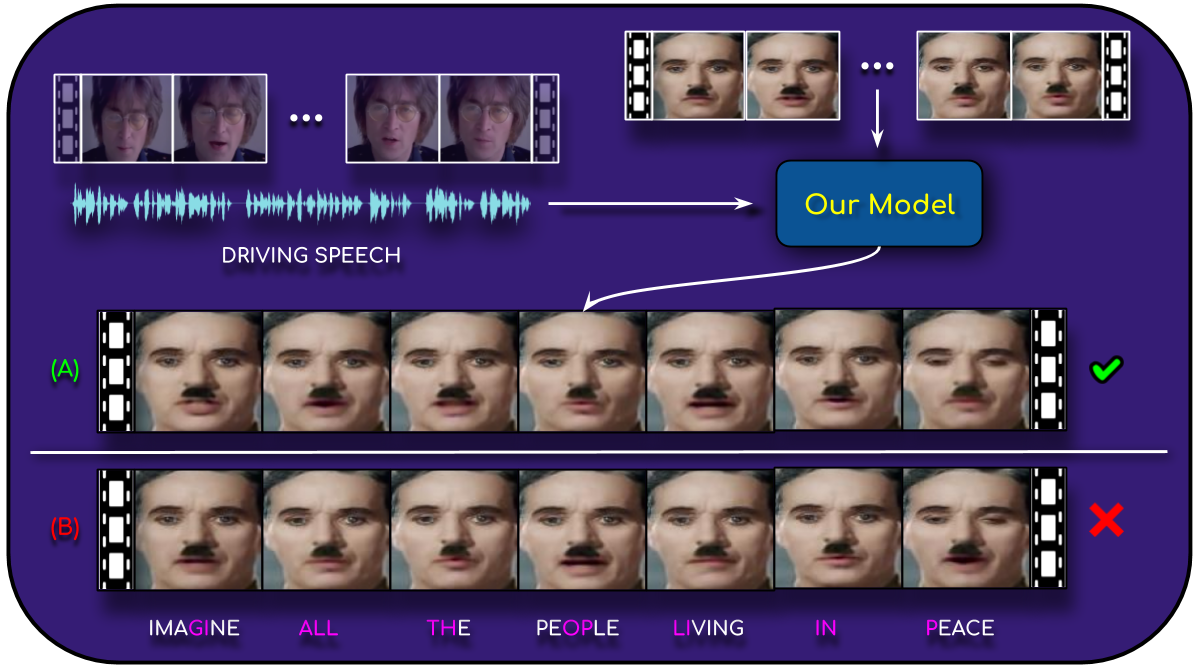 A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild
A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild
People Involved : Prajwal Renukanand, Rudrabha Mukhopadhyay, Vinay Namboodiri, and C.V. Jawahar
n this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech segment. Current works excel at producing accurate lip movements on a static image or on videos of specific people seen during the training phase. However, they fail to accurately morph the actual lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the newly chosen audio.
 Quo Vadis, Skeleton Action Recognition ?
Quo Vadis, Skeleton Action Recognition ?
People Involved : Pranay Gupta, Anirudh Thatipelli, Aditya Aggarwal, Shubh Maheshwari, Neel Trivedi, Sourav Das, Ravi Kiran Sarvadevabhatla
In this paper, we study current and upcoming frontiers across the landscape of skeleton-based human action recognition.
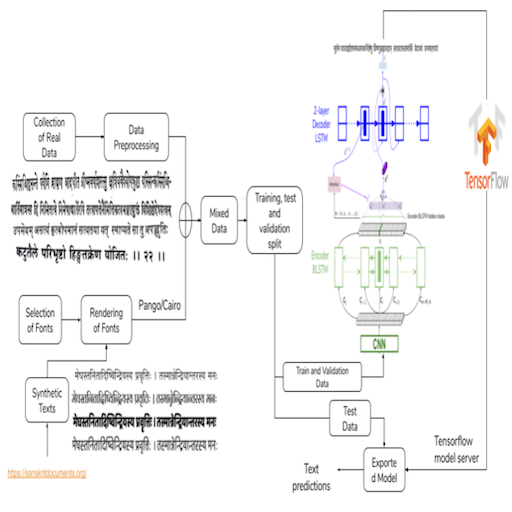 An OCR for Classical Indic Documents Containing Arbitrarily Long Words
An OCR for Classical Indic Documents Containing Arbitrarily Long Words
People Involved : Agam Dwivedi, Rohit Saluja, Ravi Kiran Sarvadevabhatla
Datasets (real, synthetic) and a CNN-LSTM Attention OCR for printed classical Indic documents containing very long words.
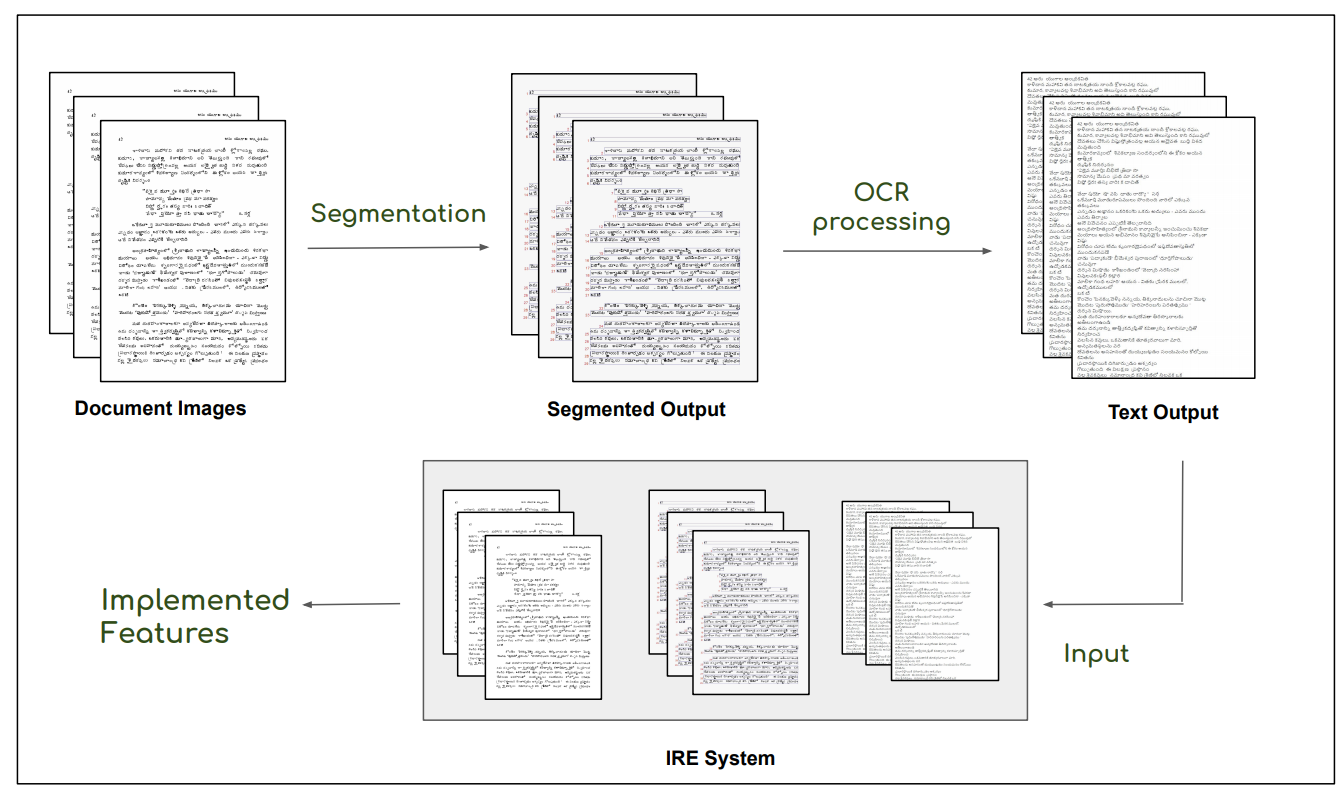 Retrieval from Large Document Image Collections
Retrieval from Large Document Image Collections
People Involved : Riya Gupta and C.V. Jawahar
Extracting the relevant information out of a large number of documents is quite a challenging and tedious task. he quality of results generated by the traditionally available full-text search engine and text-based image retrieval systems is not very optimal.
 Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
People Involved :Siddhant Bansal, Praveen Krishnan and C. V. Jawahar
Recognition and retrieval of textual content from the large document collections have been a powerful use case for the document image analysis..
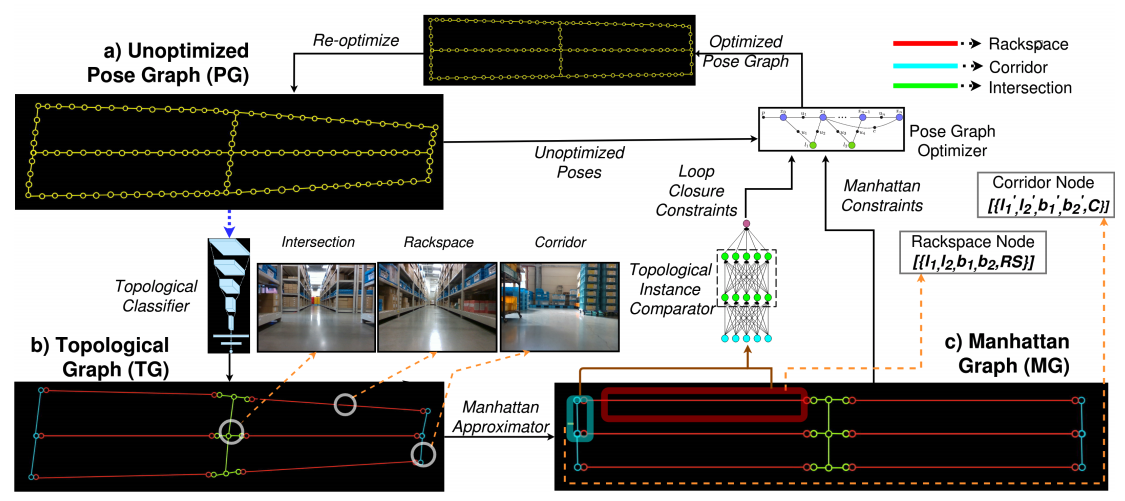 Topological Mapping for Manhattan-like Repetitive Environments
Topological Mapping for Manhattan-like Repetitive Environments
People Involved : Sai Shubodh Puligilla, Satyajit Tourani, Tushar Vaidya, Udit Singh Parihar, Ravi Kiran Sarvadevabhatla, K. Madhava Krishna
This paper explores the role of topological understanding and benefits of such an understanding to the robot SLAM framework.
 RoadText-1K: Text Detection & Recognition Dataset for Driving Videos
RoadText-1K: Text Detection & Recognition Dataset for Driving Videos
People Involved :Sangeeth Reddy, Minesh Mathew, Lluis Gomez, Marçal Rusinol, Dimosthenis Karatzas, and C. V. Jawahar
Perceiving text is crucial to understand semantics of outdoor scenes and hence is a critical requirement to build intelligent systems for driver assistance and self-driving. Most of the existing datasets for text detection and recognition comprise still images and are mostly compiled keeping text in mind.
 Text-to-Speech Dataset for Indian Languages
Text-to-Speech Dataset for Indian Languages
People Involved : Nimisha Srivastava, Rudrabha Mukhopadhyay, Prajwal K R and C.V. Jawahar
India is a country where several tens of languages are spoken by over a billion strong population. Text-to-speech systems for such languages will thus be extremely beneficial for wide-spread content creation and accessibility.
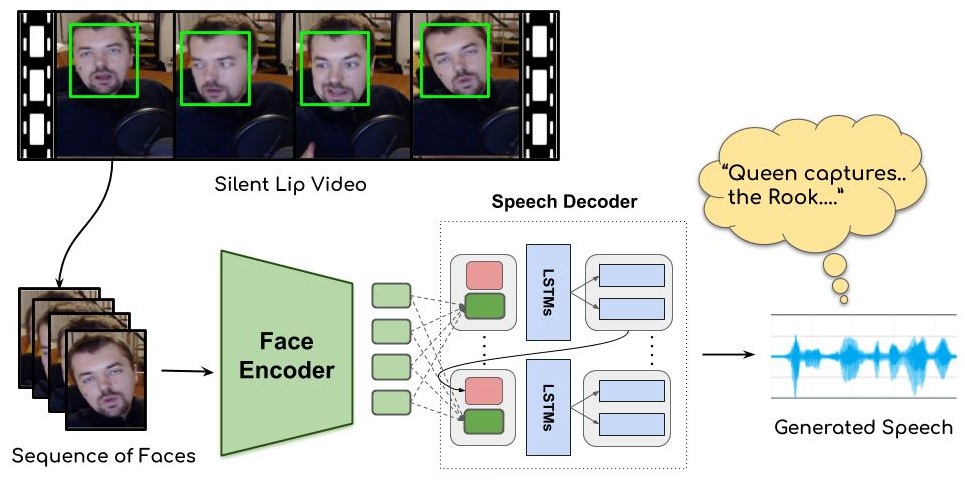 Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
People Involved : Rudrabha Mukhopadhyay* Vinay Namboodiri and C.V. Jawahar
Humans involuntarily tend to infer parts of the conversation from lip movements when the speech is absent or corrupted by external noise. In this work, we explore the task of lip to speech synthesis,
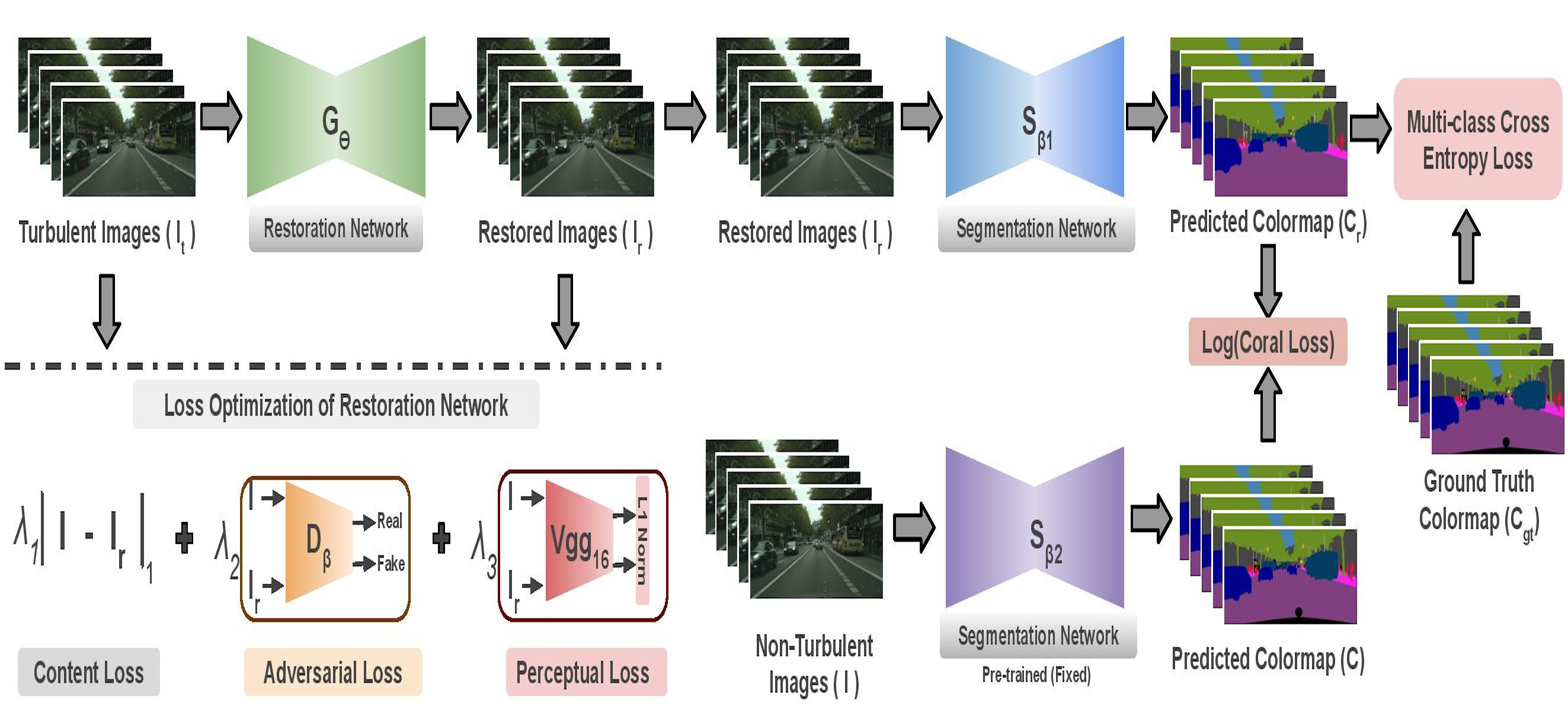 Munich to Dubai: How Far is it for Semantic Segmentation?
Munich to Dubai: How Far is it for Semantic Segmentation?
People Involved : Shyam Nandan Rai, Vineeth N Balasubramanian, Anbumani Subramanian and C. V. Jawahar
Cities having hot weather conditions results in geometrical distortion, thereby adversely affecting the performance of semantic segmentation model.
 Indiscapes: Instance segmentation networks for layout parsing of historical indic manuscripts
Indiscapes: Instance segmentation networks for layout parsing of historical indic manuscripts
People Involved : Abhishek Prusty, Aitha Sowmya, Abhishek Trivedi, Ravi Kiran Sarvadevabhatla
We introduce Indiscapes - the largest publicly available layout annotated dataset of historical Indic manuscript images.
People Involved : Raghava Modhugu, Ranjith Reddy and C. V. Jawahar
Inspecting and assessing the quality of traffic infrastructure is a challenging task due to the massive length of roads and the regular frequency at which this needs to be done. We demonstrate a scalable system that uses computer vision for automatic inspection of road infrastructure on 1500kms of roads captured in a city.
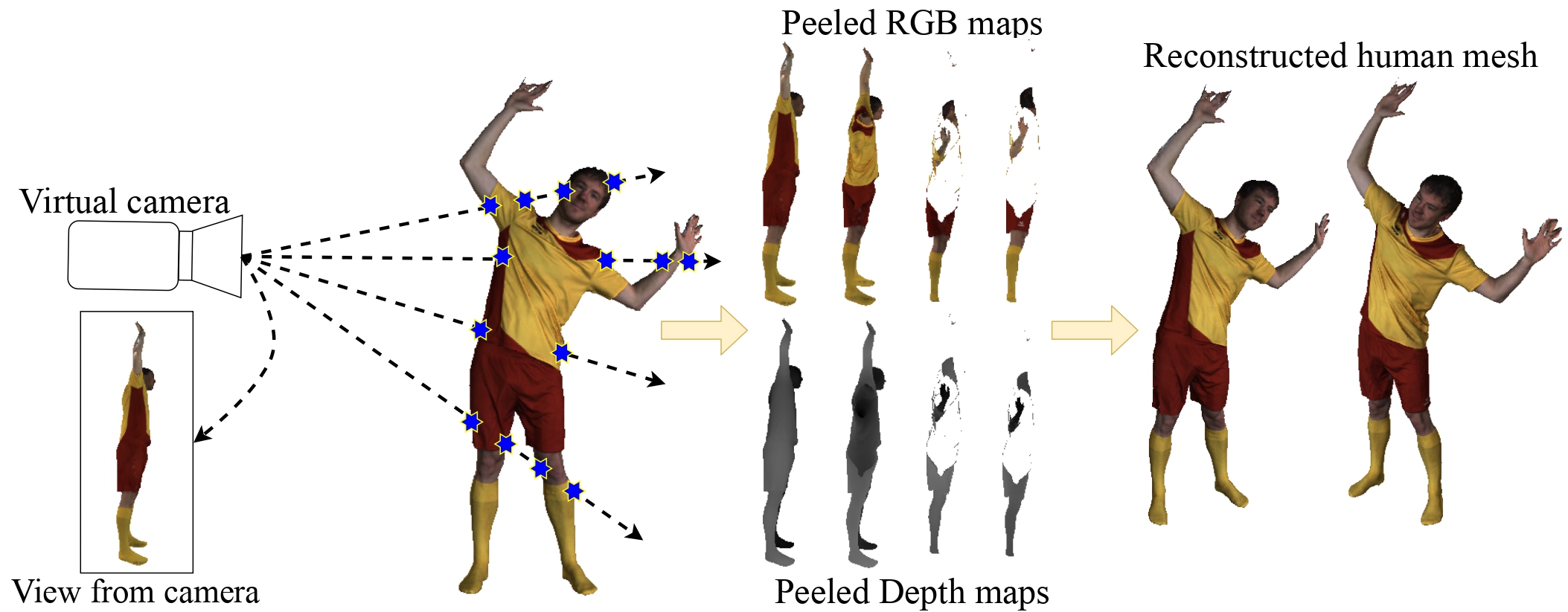 PeeledHuman: Robust Shape Representation for Textured 3D Human Body Reconstruction
PeeledHuman: Robust Shape Representation for Textured 3D Human Body Reconstruction
People Involved : Sai Sagar Jinka, Rohan Chacko, Avinash Sharma and P.J. Narayanan
We introduce PeeledHuman - a novel shape representation of the human body that is robust to self-occlusions. PeeledHuman encodes the human body
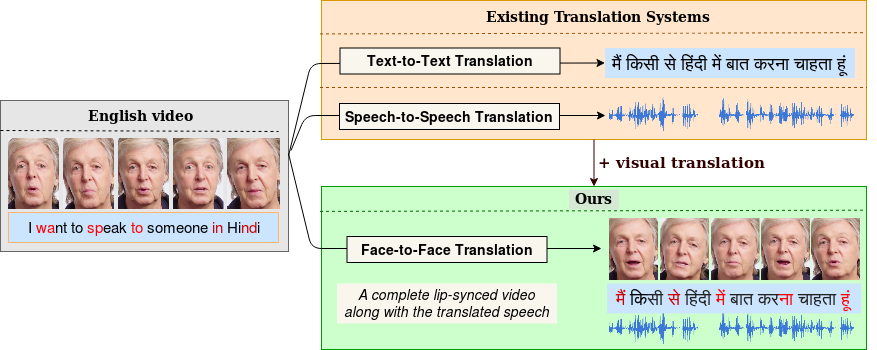 Towards Automatic Face-to-Face Translation
Towards Automatic Face-to-Face Translation
People Involved : Prajwal Renukanand, Rudrabha Mukhopadhyay, Jerin Philip, Abhishek Jha, Vinay Namboodiri and C.V. Jawahar
In light of the recent breakthroughs in automatic machine translation systems, we propose a novel approach of what we term as "Face-to-Face Translation".

People Involved : Research Students of Dr. Avinash Sharma
We are interested in computer vision and machine learning with a focus on 3D scene understanding, reconstruction etc. In particular, we deal with problems where human body is reconstructed from 2D images and analysed in 3D, registration of point clouds of indoor scenes captured from commodity sensors as well as large outdoor scenes captured from LIDAR scanners.
 Bringing Semantics in Word Image Representation
Bringing Semantics in Word Image Representation
People Involved : Praveen Krishnan, C. V. Jawahar
In this work, we propose two novel forms of word image semantic representations. The first form learns an inflection invariant representation, thereby focusing on the root of the word, while the second form is built along the lines of textual word embedding techniques such as Word2Vec. We observe that such representations are useful for both traditional word spotting and also enrich the search results by accounting the semantic nature of the task.
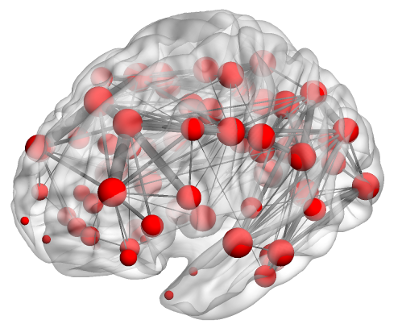 Spectral Analysis of Brain Graphs
Spectral Analysis of Brain Graphs
People Involved :Sriniwas Govinda Surampudi, Joyneel Misra, Raju Bapi Surampudi and Avinash Sharma
Our research objective is to analyze neuroimaging data using graph-spectral techniques in understanding how the static brain anatomical structure gives rise to dynamic functions during rest. We approach the problem by viewing the human brain as a complex graph of cortical regions and the anatomical fibres which connect them. We employ a range of modelling techniques which utilize methods from spectral graph theory, time series analysis, information theory, graph deep learning etc.
People Involved : Sudhir Yarram, Girish Varma and C. V. Jawahar
Road networks in cities are massive and is a critical component of mobility. Fast response to defects, that can occur not only due to regular wear and tear but also because of extreme events like storms, is essential. Hence there is a need for an automated system that is quick, scalable and cost- effective for gathering information about defects. We propose a system for city-scale road audit, using some of the most recent developments in deep learning and semantic segmentation. For building and benchmarking the system, we curated a dataset which has annotations required for road defects. However, many of the labels required for road audit have high ambiguity which we overcome by proposing a label hierarchy
 Learning Human Poses from Actions
Learning Human Poses from Actions
People Involved : Aditya Arun, C. V. Jawahar and M. Pawan Kumar
We consider the task of learning to estimate human pose in still images. In order to avoid the high cost of full supervision, we propose to use a diverse data set, which consists of two types of annotations: (i) a small number of images are labeled using the expensive ground-truth pose; and (ii) other images are labeled using the inexpensive action label. As action information helps narrow down the pose of a human, we argue that this approach can help reduce the cost of training without significantly affecting the accuracy.
 View-graph Selection Framework for Structure from Motion
View-graph Selection Framework for Structure from Motion
People Involved : Rajvi Shah, Visesh Chari, and P J Narayanan
View-graph is an essential input to large-scale structure from motion (SfM) pipelines. Accuracy and efficiency of large-scale SfM is crucially dependent on the input view-graph. Inconsistent or inaccurate edges can lead to inferior or wrong reconstruction. Most SfM methods remove `undesirable' images and pairs using several fixed heuristic criteria, and propose tailor-made solutions to achieve specific reconstruction objectives such as efficiency, accuracy, or disambiguation.
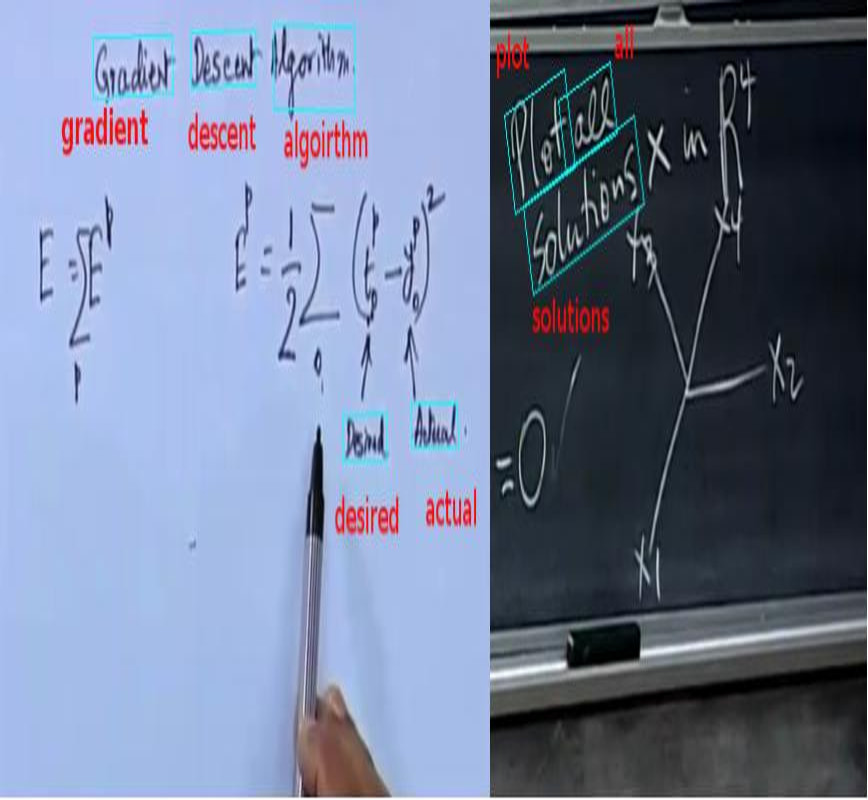 LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
People Involved : Kartik Dutta, Minesh Mathew, Praveen Krishnan and CV Jawahar
Lecture videos are rich with textual information and to be able to understand the text is quite useful for larger video understanding/analysis applications. Though text recognition from images have been an active research area in computer vision, text in lecture videos has mostly been overlooked. In this work, we investigate the efficacy of state-of-the art handwritten and scene text recognition methods on text in lecture videos
 Word level Handwritten datasets for Indic scripts
Word level Handwritten datasets for Indic scripts
People Involved : Kartik Dutta, Praveen Krishnan, Minesh Mathew and CV Jawahar
Handwriting recognition (HWR) in Indic scripts is a challenging problem due to the inherent subtleties in the scripts, cursive nature of the handwriting and similar shape of the characters. Lack of publicly available handwriting datasets in Indic scripts has affected the development of handwritten word recognizers. In order to help resolve this problem, we release 2 handwritten word datasets: IIIT-HW-Dev, a Devanagari dataset and IIIT-HW-Telugu, a Telugu dataset.
![]() Human Shape Capture and Tracking at Home
Human Shape Capture and Tracking at Home
People Involved : Gaurav Mishra, Saurabh Saini, Kiran Varanasi and P.J. Narayanan
Human body tracking typically requires specialized capture set-ups. Although pose tracking is available in consumer devices like Microsoft Kinect, it is restricted to stick figures visualizing body part detection. In this paper, we propose a method for full 3D human body shape and motion capture of arbitrary movements from the depth channel of a single Kinect, when the subject wears casual clothes
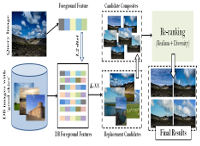 Find me a sky : a data-driven method for color-consistent sky search & replacement
Find me a sky : a data-driven method for color-consistent sky search & replacement
People Involved : Saumya Rawat, Siddhartha Gairola, Rajvi Shah, and P J Narayanan
Replacing overexposed or dull skies in outdoor photographs is a desirable photo manipulation. It is often necessary to color correct the foreground after replacement to make it consistent with the new sky. Methods have been proposed to automate the process of sky replacement and color correction. However, many times a color correction is unwanted by the artist or may produce unrealistic results.
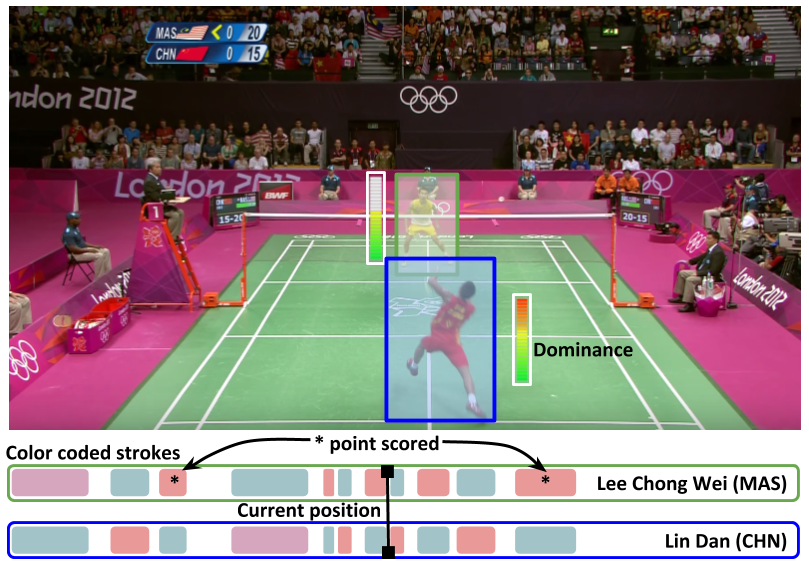 Towards Structured Analysis of Broadcast Badminton Videos
Towards Structured Analysis of Broadcast Badminton Videos
People Involved :Anurag Ghosh, Suriya Singh and C. V. Jawahar
Sports video data is recorded for nearly every major tournament but remains archived and inaccessible to large scale data mining and analytics. It can only be viewed sequentially or manually tagged with higher-level labels which is time consuming and prone to errors. In this work, we propose an end-to-end framework for automatic attributes tagging and analysis of sport videos.
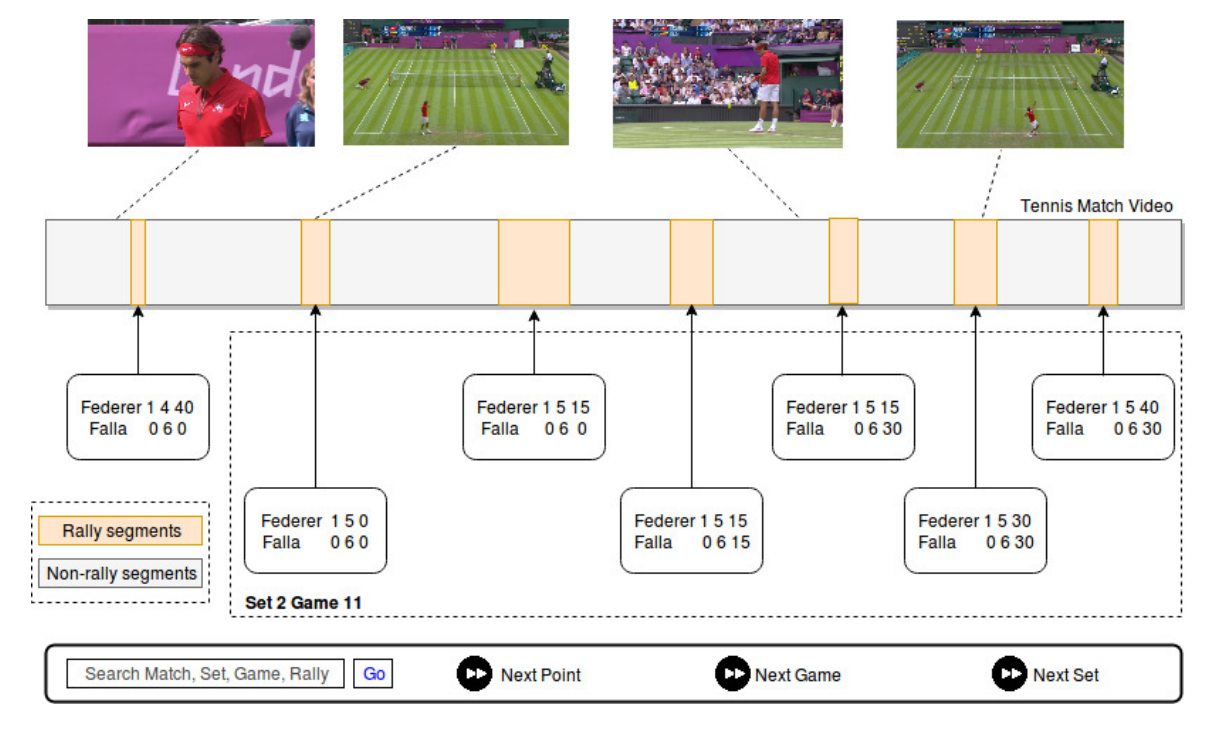 SmartTennisTV: Automatic indexing of tennis videos
SmartTennisTV: Automatic indexing of tennis videos
People Involved :Anurag Ghosh and C. V. Jawahar
In this paper, we demonstrate a score based indexing approach for tennis videos. Given a broadcast tennis video (BTV), we index all the video segments with their scores to create a navigable and searchable match. Our approach temporally segments the rallies in the video and then recognizes the scores from each of the segments, before refining the scores using the knowledge of the tennis scoring system
 Word Spotting in Silent Lip Videos
Word Spotting in Silent Lip Videos
People Involved :Abhishek Jha, Vinay Namboodiri and C. V. Jawahar
Our goal is to spot words in silent speech videos without explicitly recognizing the spoken words, where the lip motion of the speaker is clearly visible and audio is absent. Existing work in this domain has mainly focused on recognizing a fixed set of words in word-segmented lip videos, which limits the applicability of the learned model due to limited vocabulary and high dependency on the model's recognition performance.
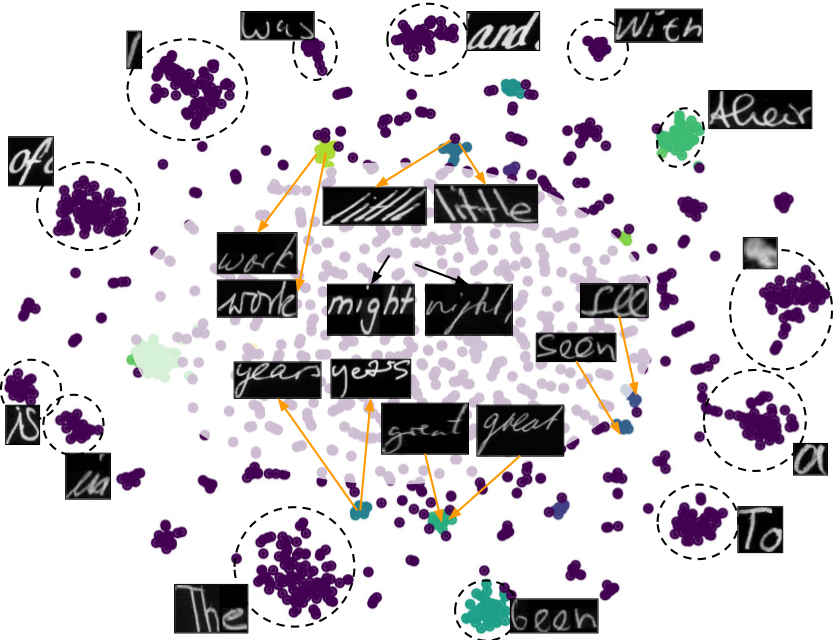 HWNet - An Efficient Word Image Representation for Handwritten Documents
HWNet - An Efficient Word Image Representation for Handwritten Documents
People Involved : Praveen Krishnan, C. V. Jawahar
We propose a deep convolutional neural network named HWNet v2 (successor to our earlier work [1]) for the task of learning efficient word level representation for handwritten documents which can handle multiple writers and is robust to common forms of degradation and noise. We also show the generic nature of our representation and architecture which allows it to be used as off-the-shelf features for printed documents and building state of the art word spotting systems for various languages.
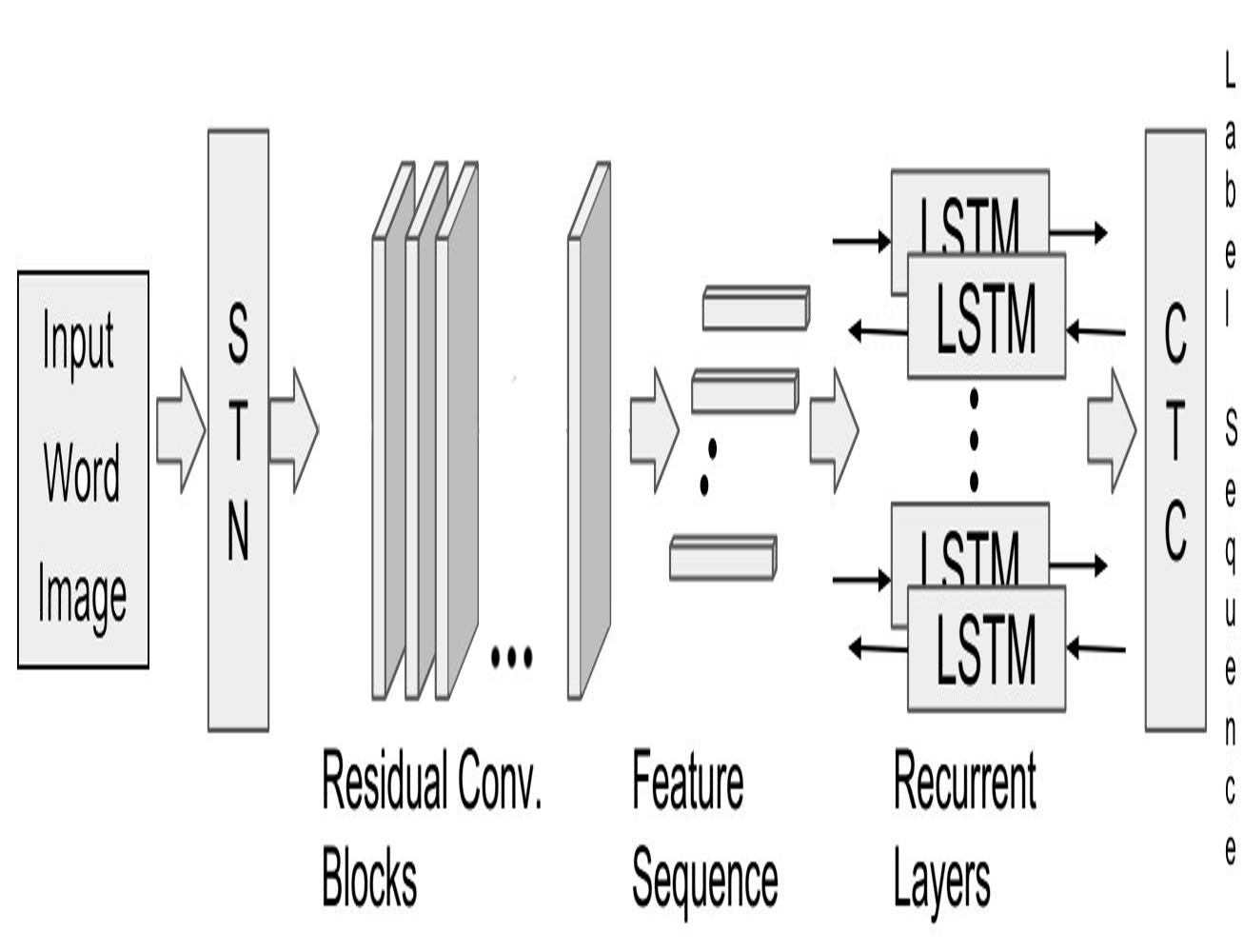
 Unconstrained OCR for Urdu using Deep CNN-RNN Hybrid Networks
Unconstrained OCR for Urdu using Deep CNN-RNN Hybrid Networks
People Involved : Mohit Jain, Minesh Mathew, C. V. Jawahar
Building robust text recognition systems for languages with cursive scripts like Urdu has always been challenging. Intricacies of the script and the absence of ample annotated data further act as adversaries to this task. We demonstrate the effectiveness of an end-to-end trainable hybrid CNN-RNN architecture in recognizing Urdu text from printed documents, typically known as Urdu OCR. The solution proposed is not bounded by any language specific lexicon with the model following a segmentation-free, sequence-tosequence transcription approach. The network transcribes a sequence of convolutional features from an input image to a sequence of target labels.
 Unconstrained Scene Text and Video Text Recognition for Arabic Script
Unconstrained Scene Text and Video Text Recognition for Arabic Script
People Involved : Mohit Jain, Minesh Mathew, C. V. Jawahar
Building robust recognizers for Arabic has always been challenging. We demonstrate the effectiveness of an end-to-end trainable CNN-RNN hybrid architecture in recognizing Arabic text in videos and natural scenes. We outperform previous state-of-the-art on two publicly available video text datasets - ALIF and AcTiV. For the scene text recognition task, we introduce a new Arabic scene text dataset and establish baseline results. For scripts like Arabic, a major challenge in developing robust recognizers is the lack of large quantity of annotated data. We overcome this by synthesizing millions of Arabic text images from a large vocabulary of Arabic words and phrases.

People Involved : Vijay Kumar, Anoop Namboodiri, Manohar Paluri, C. V. Jawahar
Person recognition methods that use multiple body regions have shown significant improvements over traditional face-based recognition. One of the primary challenges in full-body person recognition is the extreme variation in pose and view point. In this work, (i) we present an approach that tackles pose variations utilizing multiple models that are trained on specific poses, and combined using pose-aware weights during testing. (ii) For learning a person representation, we propose a network that jointly optimizes a single loss over multiple body regions. (iii) Finally, we introduce new benchmarks to evaluate person recognition in diverse scenarios and show significant improvements over previously proposed approaches on all the benchmarks including the photo album setting of PIPA.
 The IIIT-CFW dataset
The IIIT-CFW datasetPeople Involved : Ashutosh Mishra, Shyam Nandan Rai, Anand Mishra, C. V. Jawahar
The IIIT-CFW is database for the cartoon faces in the wild. It is harvested from Google image search. Query words such as Obama + cartoon, Modi + cartoon, and so on were used to collect cartoon images of 100 public figures. The dataset contains 8928 annotated cartoon faces of famous personalities of the world with varying profession. Additionally, we also provide 1000 real faces of the public figure to study cross modal retrieval tasks, such as, Photo2Cartoon retrieval. The IIIT-CFW can be used for the study spectrum of problems as discussed in our ECCVW paper.
![]() Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text
Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text
People Involved : Praveen Krishnan, Kartik Dutta and C. V. Jawahar
We propose a deep convolutional feature representation that achieves superior performance for word spotting and recognition for handwritten images. We focus on :- (i) enhancing the discriminative ability of the convolutional features using a reduced feature representation that can scale to large datasets, and (ii) enabling query-by-string by learning a common subspace for image and text using the embedded attribute framework. We present our results on popular datasets such as the IAM corpus and historical document collections from the Bentham and George Washington pages.
![]() Matching Handwritten Document Images
Matching Handwritten Document Images
People Involved : Praveen Krishnan and C. V. Jawahar
We address the problem of predicting similarity between a pair of handwritten document images written by different individuals. This has applications related to matching and mining in image collections containing handwritten content. A similarity score is computed by detecting patterns of text re-usages between document images irrespective of the minor variations in word morphology, word ordering, layout and paraphrasing of the content.
 Visual Aesthetic Analysis for Handwritten Document Images
Visual Aesthetic Analysis for Handwritten Document Images
People Involved : Anshuman Majumdar, Praveen Krishnan and C. V. Jawahar
We present an approach for analyzing the visual aesthetic property of a handwritten document page which matches with human perception. We formulate the problem at two independent levels: (i) coarse level which deals with the overall layout, space usages between lines, words and margins, and (ii) fine level, which analyses the construction of each word and deals with the aesthetic properties of writing styles. We present our observations on multiple local and global features which can extract the aesthetic cues present in the handwritten documents.
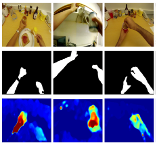 First Person Action Recognition
First Person Action Recognition
People Involved : Suriya Singh, Chetan Arora, C. V. Jawahar
 Panoramic Stereo Videos With A Single Camera
Panoramic Stereo Videos With A Single Camera
People Involved : Rajat Aggarwal, Amrisha Vohra, Anoop M. Namboodri
We present a practical solution for generating 360° stereo panoramic videos using a single camera. Current approaches either use a moving camera that captures multiple images of a scene, which are then stitched together to form the final panorama, or use multiple cameras that are synchronized. A moving camera limits the solution to static scenes, while multi-camera solutions require dedicated calibrated setups. Our approach improves upon the existing solutions in two significant ways: It solves the problem using a single camera, thus minimizing the calibration problem and providing us the ability to convert any digital camera into a panoramic stereo capture device. It captures all the light rays required for stereo panoramas in a single frame using a compact custom designed mirror, thus making the design practical to manufacture and easier to use. We analyze several properties of the design as well as present panoramic stereo and depth estimation results.
 Face Fiducial Detection by Consensus of Exemplars
Face Fiducial Detection by Consensus of Exemplars
People Involved : Mallikarjun B R, Visesh Chari, C. V. Jawahar , Akshay Asthana
An exemplar based approach to detect the facial landmarks. We show that by using a very simple SIFT and HOG based descriptor, it is possible to identify the most accurate fiducial outputs from a set of results produced by regression and mixture of trees based algorithms (which we call candidate algorithms) on any given test image. Our approach manifests as two algorithms, one based on optimizing an objective function with quadratic terms and the other based on simple kNN.
 Fine-Tuning Human Pose Estimation in Videos
Fine-Tuning Human Pose Estimation in Videos
People Involved :Digvijay Singh, Vineeth Balasubramanian, C. V. Jawahar
A semi-supervised self-training method for fine-tuning human pose estimations in videos that provides accurate estimations even for complex sequences.
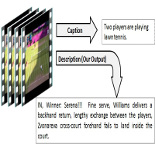 Fine-Grained Descriptions for Domain Specific Videos
Fine-Grained Descriptions for Domain Specific Videos
People Involved :Mohak Kumar Sukhwani, C. V. Jawahar
Generation of human like natural descriptions for multimedia content pose an interesting challenge for vision community. In our current work we tackle the challenge of generating descriptions for the videos. The proposed method demonstrates considerable success in generating syntactically and pragmatically correct text for lawn tennis videos and is notably effective in capturing majority of the video content. Unlike any previous work our method focuses on generating exhaustive and richer human like descriptions. We aim to provide reliable descriptions that facilitate the task of video analysis and help understand the ongoing events in the video. Large volumes of text data are used to compute associated text statistics which is thereafter used along with computer vision algorithms to produce relevant descriptions
 Learning relative attributes using parts
Learning relative attributes using parts
People Involved :Ramachandruni N Sandeep, Yashaswi Verma, C. V. Jawahar
Our aim is to learn relative attributes using local parts that are shared across categories. First, instead of using a global representation, we introduce a part-based representation combining a pair of images that specifically compares corresponding parts. Then, with each part we associate a locally adaptive “significance coefficient” that represents its discriminative ability with respect to a particular attribute. For each attribute, the significance-coefficients are learned simultaneously with a max-margin ranking model in an iterative manner. Compared to the baseline method , the new method is shown to achieve significant improvements in relative attribute prediction accuracy. Additionally, it is also shown to improve relative feedback based interactive image search.
 Motion Trajectory Based Video Retrieval
Motion Trajectory Based Video Retrieval
People Involved : Koustav Ghosal & Anoop Namboodiri
Extracting robust motion trajectories from videos is an active problem in Computer Vision. The task is more challenging in unconstrained videos in presence of dynamic background, blur, camera motion and affine irregularities. But once extracted, one can retrieve the videos based on them by giving an online (temporal) sketch as a query. But different individuals have different perception about motion trajectories and hence sketch differently. Through this work we are trying to extract robust trajectories from unconstrained videos and then model the sketch in a way so that the perceptual variability among different sketches is removed.
 Decomposing Bag of Words Histograms
Decomposing Bag of Words Histograms
People Involved :Ankit Gandhi, Karteek Alahari, C V Jawahar
We aim to decompose a global histogram representation of an image into histograms of its associated objects and regions. This task is formulated as an optimization problem, given a set of linear classifiers, which can effectively discriminate the object categories present in the image. Our decomposition bypasses harder problems associated with accurately localizing and segmenting objects.
 Action Recognition using Canonical Correlation Kernels
Action Recognition using Canonical Correlation Kernels
People Involved :G Nagendar, C V Jawahar
Action recognition has gained significant attention from the computer vision community in recent years. This is a challenging problem, mainly due to the presence of significant camera motion, viewpoint transitions, varying illumination conditions and cluttered backgrounds in the videos. A wide spectrum of features and representations has been used for action recognition in the past. Recent advances in action recognition are propelled by (i) the use of local as well as global features, which have significantly helped in object and scene recognition, by computing them over 2D frames or over a 3D video volume (ii) the use of factorization techniques over video volume tensors and defining similarity measures over the resulting lower dimensional factors. In this project, we try to take advantages of both these approaches by defining a canonical correlation kernel that is computed from tensor representation of the videos. This also enables seamless feature fusion by combining multiple feature kernels.
 Image Annotation
Image AnnotationPeople Involved :Yashaswi Verma, C V Jawahar
In many real-life scenarios, an object can be categorized into multiple categories. E.g., a newspaper column can be tagged as "political", "election", "democracy"; an image may contain "tiger", "grass", "river"; and so on. These are instances of multi-label classification, which deals with the task of associating multiple labels with single data. Automatic image annotation is a multi-label classification problem that aims at associating a set of text with an image that describes its semantics.
 Computational Displays
Computational DisplaysPeople Involved :Parikshit Sakurikar, Revanth N R, Pawan Harish, Nirnimesh and P J Narayanan
Displays have seen many improvements over the years but have many shortcomings still. These include rectangular shape, low color gamut, low dynamic range, lack of focus and context in a scene, lack of 3D viewing, etc. We propose Computational Displays, which employ computation to economically alleviate some of the shortcomings of today's displays.
 Scene Text Understanding
Scene Text UnderstandingPeople Involved :Udit Roy, Anand Mishra, Karteek Alahari and C.V. Jawahar
Scene text recognition has gained significant attention from the computer vision community in recent years. Often images contain text which gives rich and useful information about their content. Recognizing such text is a challenging problem, even more so than the recognition of scanned documents. Scene text exhibits a large variability in appearances, and can prove to be challenging even for the state-of-the-art OCR methods. Many scene understanding methods recognize objects and regions like roads, trees, sky etc in the image successfully, but tend to ignore the text on the sign board. Our goal is to fill this gap in understanding the scene.
 Parallel Computing using CPU and GPU
Parallel Computing using CPU and GPU
People Involved : Aditya Deshpande, Parikshit Sakurikar, Harshit Sureka, K. Wasif, Ishan Misra, Pawan Harish, Vibhav Vineet and P J Narayanan
Commodity graphics hardware has become a cost-effective parallel platform for solving many general problems. New Graphics hardware by Nvidia offers an alternate programming model called CUDA which can be used in more flexible ways than GPGPU.
 Exploiting SfM Data from Community Collections
Exploiting SfM Data from Community Collections
People Involved : Aditya Singh, Apurva Kumar, Krishna Kumar Singh, Kaustav Kundu, Rajvi Shah, Aditya Deshpande, Shubham Gupta, Siddharth Choudhary and P J Narayanan
Progress in the field of 3D Computer Vision has led to the development of robust SfM (Structure from Motion) algorithms. These SfM algorithms, allow us to build 3D models of the monuments using community photo collections. We work on improving the speed and accuracy of these SfM algorithms and also on developing tools that use the rich geometry present in the SfM datasets.
 Ray Tracing on the GPU
Ray Tracing on the GPUPeople Involved : Srinath Ravichandran, Rohit Nigam, Sashidhar Guntury, Jag Mohan Singh, Suryakant Patidar and P J Narayanan
Ray tracing is used to render photorealistic images in computer graphics. We work on real time ray tracing of static, dynamic and deformable scenes composed of polygons as well as higher order surfaces on the GPU.
People Involved : Gopal Datt Joshi, Mayank Chawla, Arunava Chakravarty, Akhilesh Bontala, Shashank Mujjumdar, Rohit Gautam, Subbu, Sushma
Digital medical images are widely used for diagnostic purposes. Our goal is to develop algorithms for medical image analysis focusing on enhancement, segmentation, multi-modal registration and classification.
 Terrain Rendering and Information System
Terrain Rendering and Information System
People Involved : Shiben Bhattacharjee, Suryakant Patidar and P J Narayanan
Digital Terrain Model refer to a data model that attempts to provide a three dimensional representation of a continuous surface, since terrains are two and a half dimensional rather than three dimensional.
 Data Generation Tool kit
Data Generation Tool kitPeople Involved :V Krishna
Synthetic data is very useful for validating the algorithms developed for various computer vision and image based rendering algorithms.
 Recognition of Indian Language Documents
Recognition of Indian Language Documents
People Involved : Million Meshesha, Balasubramanian Anand, Sesh Kumar, L. Jagannathan, Neeba N V, Venkat Rasagna
The present growth of digitization of documents demands an immediate solution to enable the archived valuable materials searchable and usable by users in order to achieve its objective.
 Retrieval of Document Images
Retrieval of Document ImagesPeople Involved : Million Meshesha, Balasubramanian Anand, Pramod Sankar K, Anand Kumar
Our approach towards retrieval of document images, avoids explicit recognition of the text. Instead, we perform word matching in the image space. Given a query word, we generate its corresponding word image, and compare it against the words in the documents.
 Retrieval from Video Databases
Retrieval from Video Databases
People Involved :Tarun Jain, Anurag Singh Rana, Balakrishna C., Pramod Sankar K., Saurabh Pandey, Balamanohar P., Natraj J.
Digital Libraries of broadcast videos could be easily built with existing technology. The storage, archival, search and retrieval of broadcast videos provide a large number of challenges for the research community. We address these challenges in different novel directions.
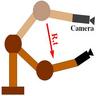 Robotic Vision
Robotic VisionPeople Involved : Abdul Hafez, Visesh Uday Kumar, Supreeth, Anil, D. Santosh
Our research activity is primarily concerned with the geometric analysis of scenes captured by vision sensors and the control of a robot so as to perform set tasks by utilzing the scene intepretation.
 Content Based Image Retrieval : CBIR
Content Based Image Retrieval : CBIR
People Involved : Pradhee Tandon, P. Suman Karthik, Natraj J., Dhaval Mehta, E. S. V. N. L. S. Diwakar
We strive to enable machines with subjective perception capabilities at par with human their counterparts, especially with regards to images.
 Contours, Textures, Homography and Fourier Domain
Contours, Textures, Homography and Fourier Domain
People Involved :Sujit Kuthirummal, Paresh Kumar Jain, M. Pawan Kumar, Saurabh Goyal
The aim of this study is to come up with a Fourier representation of contours and then utilise it to estimate two view relationships like homography and also come up with novel invariants.
 Biometrics
BiometricsPeople Involved :Vandana Roy, Sachin Gupta
The aim of the work is to develop robust and accurate biometric recognition systems, primarily for use in civilian applications. We are currently working on enhancing soft biometric traits such as hand geometry and palm texture, and also on gathering identity information from online handwritten documents.
 Online Handwriting Analysis
Online Handwriting AnalysisPeople Involved :Naveen Chandra Tewari, Sachin Gupta
Handwritten Recognition refers to mapping of meaningful handwritten lexemes to computer understandable codes. There are many applications in which entering data using handwriting is more convenient than keyboard like in making notes or making hand sketches.
 Garuda: A Scalable, Geometry Managed Display Wall
Garuda: A Scalable, Geometry Managed Display Wall
People Involved :Pawan Harish, Nirnimesh and P J Narayanan
Cluster-based tiled display walls simultaneously provide high resolution and large display area (Focus + Context) and are suitable for many applications. They are also cost-effective and scalable with low incremental costs. Garuda is a client-server based display wall solution designed to use off-the-shelf graphics hardware and standard Ethernet network.
 Depth-Image Representations
Depth-Image RepresentationsPeople Involved : Pooja Verlani, Aditi Goswami, Shekhar Dwivedi, Sireesh Reddy K, Sashi Kumar Penta
Depth Images are viable representations that can be computed from the real world using cameras and/or other scanning devices. The depth map provides a 2 and a half D structure of the scene. The depth map gives a visibility-limited model of the scene and can be rendered easily using graphics techniques.
 Biological Vision
Biological VisionPeople Involved :Gopal Datt Joshi, Kartheek N V, Varun Jampani
The perceptual mechanisms used by different organisms to negotiate the visual world are fascinatingly diverse. Even if we consider only the sensory organs of vertebrates, such as eye, there is much variety.
 Learning Appearance Models
Learning Appearance ModelsPeople Involved :Karteek Alahari, Paresh Jain, Ranjeeth Kumar, Manikandan
Our reseach focuses on learning appearance models from images/videos that can be used for a variety of tasks such as recognition, detection and classification etc.
 Projected Texture for 3D Object Recognition
Projected Texture for 3D Object Recognition
People Involved : Avinash Sharma, Nishant Shobhit
We are solving the problem of 3D object recognition. Instead of recovering the 3D of object we are encoding the depth variation in object with deformation induced in pattern projected on object from certain pose. We proposed some effective features which can effectively characterize deformation of projected pattern for the purpose of recognition.
 Security and Privacy of Visual Data
Security and Privacy of Visual Data
People Involved : Maneesh Upmanyu, Narsimha Raju, Shashank Jagarlamudi, Kowshik Palivela
With a rapid development and acceptablity of computer vision based systems in one's daily life, securing of the visual data has become imperative. Security issues in computer vision primarily originates from the storage, distribution and processing of the personal data, whereas privacy concerns with tracking down of the user's activity. Through this work we address specific security and privacy concerns of the visual data. We propose application specific, computationally efficient and provably secure computer vision algorithms for the encrypted domain.
Semantic Classification of Boundaries of an RGBD Image
People Involved :Nishit Soni, Anoop M. Namboodiri, C. V. Jawahar, Srikumar Ramalingam
 Retinal Image Analysis
Retinal Image AnalysisPeople Involved : Arunava, Ujjwal, Gopal, Akhilesh, Sai, Yogesh
Analysis of retinal images for diagnostic purposes
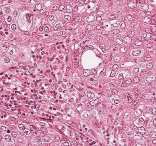 Histo Pathological Image Analysis
Histo Pathological Image Analysis
People Involved : Anisha
Automatic analysis of histo-pathological images.
People Involved :
Analysis of brain MRI and CT images for dignostic purposes.
 Image Reconstruction
Image ReconstructionPeople Involved : Neha, Kartheek
Image upsampling on square and rotated lattice.
 Fine-Grain Annotation of Cricket Videos
Fine-Grain Annotation of Cricket Videos
People Involved : Rahul Anand Sharma, Pramod Sankar K, C. V. Jawahar
 Fine Pose Estimation of Known Objects in Cluttered Scene Images
Fine Pose Estimation of Known Objects in Cluttered Scene Images
People Involved :Sudipto Banerjee, Sanchit Aggarwal, Anoop M. Namdoodiri
 Medical Image Perception
Medical Image PerceptionPeople Involved : Varun & Samrudhdhi Rangrej
Extracting robust motion trajectories from videos is an active problem in Computer Vision. The task is more challenging in unconstrained videos in presence of dynamic background, blur, camera motion and affine irregularities. But once extracted, one can retrieve the videos based on them by giving an online (temporal) sketch as a query. But different individuals have different perception about motion trajectories and hence sketch differently. Through this work we are trying to extract robust trajectories from unconstrained videos and then model the sketch in a way so that the perceptual variability among different sketches is removed.
 Currency Recognition on Mobile Phones
Currency Recognition on Mobile Phones
People Involved : Suriya Singh, Shushman Choudhury, Kumar Vishal and C.V. Jawahar
In this project, we present an application for recognizing currency bills using computer vision techniques, that can run on a low-end smartphone. The application runs on the device without the need for any remote server. It is intended for robust, practical use by the visually impaired.