Retrieval of Document Images
Introduction
Large collections of paper-based documents and books are being brought to the digital domain, through the efforts of various digitisation projects. The Digital Library of India initiative has scanned and archived more than a Million books. The automatic transcription of document images using Optical Character Recognition (OCR) is handicapped by the poor accuracy of OCRs, especially for Indian, African and oriental languages. Consequently, retrieval from document image collections is a challenging task.
Our approach towards retrieval of document images, avoids explicit recognition of the text. Instead, we perform word matching in the image space. Given a query word, we generate its corresponding word image, and compare it against the words in the documents. Documents that contain similar-looking words to the query, are retrieved for the user. This enables the user to search and retrieve from document images, using text queries.
Indexing Word Images
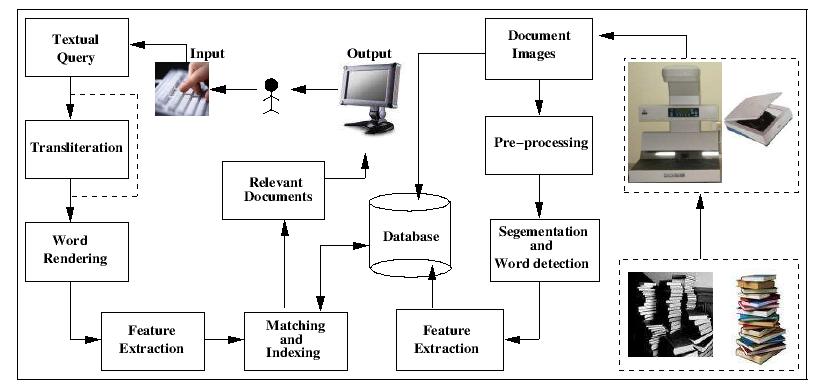 Matching words in the image space should handle the many variations in font size, font type, style, noise, degradations etc. that are present in document images. The features and the matching technique were carefully designed to handle this variety. Further, morphological word variations, such as prefix and suffixes for a given stem word, are identified using an innovative partial matching scheme. We use Dynamic Time Warping (DTW) based matching algorithm which enables us to efficiently exploit the information supplied by local features, that scans vertical strips of the word images.
Matching words in the image space should handle the many variations in font size, font type, style, noise, degradations etc. that are present in document images. The features and the matching technique were carefully designed to handle this variety. Further, morphological word variations, such as prefix and suffixes for a given stem word, are identified using an innovative partial matching scheme. We use Dynamic Time Warping (DTW) based matching algorithm which enables us to efficiently exploit the information supplied by local features, that scans vertical strips of the word images.
This matching scheme is used to build an index for the documents. Word images are matched and clustered, such that a cluster contains all instances of a given word from all document images. These clusters allow us to build an indexing scheme for the document images. The index is built in the image space. Each entry in the index corresponds to the various words in the documents, while the index points to the documents that contain the given word. The documents are ranked using the term frequency inverse document frequency, TF/IDF measure. Given a query word, its word image is rendered and matched against the word images in the index. The index term that matches is used to immediately retireve all documents that contain the given query word.
This scheme was successfully demonstrated on tens of books. The search system is able to efficiently and quickly retrieve from document images, given a textual query. The system allows for cross-lingual search using transliteration and dictionary based translation. The system is available here . Popular search queries include arjuna, devotion, said, poolan, etc.
Word Annotation for Search
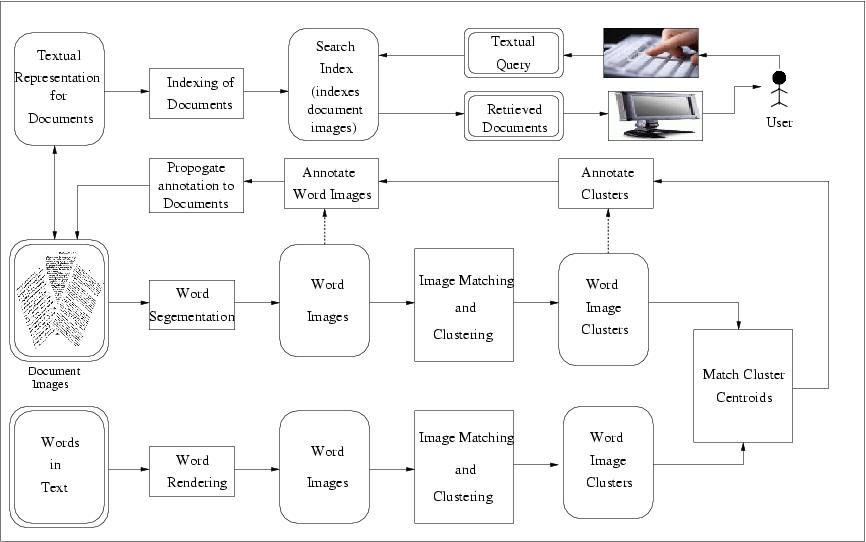 Online matching of a query word against a search index is a computationally intensive process and thus time consuming. This can be avoided by performing annotation of the word images. Annotation assigns a corresponding text word to each word image. This enables further processing, such as indexing and retrieval, to occur in the text domain. Search and retireval in text domain allows us to build search systems which have interactive response times.
Online matching of a query word against a search index is a computationally intensive process and thus time consuming. This can be avoided by performing annotation of the word images. Annotation assigns a corresponding text word to each word image. This enables further processing, such as indexing and retrieval, to occur in the text domain. Search and retireval in text domain allows us to build search systems which have interactive response times.
Automatic annotation of word images is performed by the following procedure
- Cluster Word images from documents, as similar to indexing
- Generate labeled keyword images, by rendering from text
- Cluster keyword images, using the techniques used for word images
- Form associations between clusters of word images and keyword images
- Annotate each word image with the most similar keyword to each word image
The annotation procedure is a one time offline computation, that results in a text equivalent for documents. A text based search system was built over the annotated documents. We have built a search system for 500 books in the Telugu language, which retrieves documents in real time. The procedure is scalable to large collections, while the retrieval time is unchanged.
Hashing of Word Images
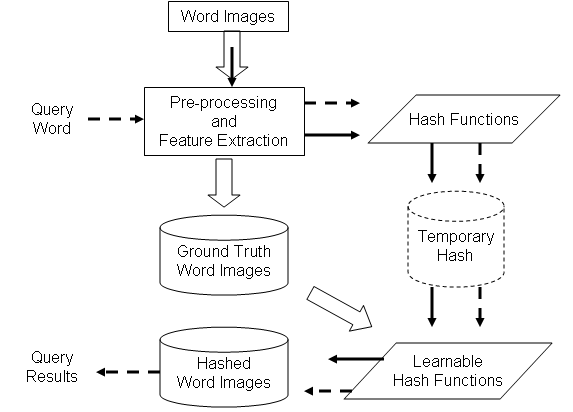 In databases, hashing of data is considered an efficient alternative to indexing (and clustering). In hashing, a single function value is computed for each word image. The words that have same (or similar) hash values are placed in the same bin. Effectively, the words with similar hash values are clustered together. With such a scheme, indexing search and retrieval of documents is linear in time complexity, which is a significant prospect.
In databases, hashing of data is considered an efficient alternative to indexing (and clustering). In hashing, a single function value is computed for each word image. The words that have same (or similar) hash values are placed in the same bin. Effectively, the words with similar hash values are clustered together. With such a scheme, indexing search and retrieval of documents is linear in time complexity, which is a significant prospect.
We are building hash functions such that similar word images are mapped to same hash value. The features extracted from word images are used to hash using Locality Sensitive Hashing (LSH). With LSH, we ensure that for each function, the probability of collision is much higher for words which are close to each other than for those which are far apart. In the first stage, the images are hashed to a temporary hash table using randomly generated hash functions. These hash functions may hash different words into same index. To minimize such errors in hashing, we use the second level of hash function, which are learnable from ground truth data. When a query is given, the primary hash functions are applied to identify the first level hash value. The learned hash functions are then applied to rehash the image to another hash table. From the final hash table a linear search is done to retrieve the relevant word images. Thus the linear searching time is changed to sublinear with the use of locality sensitive hashing.
Related Publications
Million Meshesha and C. V. Jawahar - Matching word image for content-based retrieval from printed document images Proceeding of the International Journal on Document Analysis and Recognition, IJDAR 11(1), 29-38, 2008. [PDF]
Pramod Sankar K. and C.V. Jawahar - Enabling Search over Large Collections of Telugu Document Images-An Automatic Annotation Based Approach , 5th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Madurai, India, LNCS 4338 pp.837-848, 2006. [PDF]
Pramod Sankar K., Million Meshesha and C. V. Jawahar - Annotation of Images and Videos Based on Textual Content Without OCR, Workshop on Computation Intensive Methods for Computer Vision(in conjuction with ECCV 2006), 2006. [PDF]
A. Balasubramanian, Million Meshesha and C. V. Jawahar - Retrieval from Document Image Collections, Proceedings of Seventh IAPR Workshop on Document Analysis Systems, 2006 (LNCS 3872), pp 1-12. [PDF]
C. V. Jawahar, Million Meshesha and A. Balasubramanian, Searching in Document Images, Proceedings of the Indian Conference on Vision, Graphics and Image Processing(ICVGIP), Dec. 2004, Calcutta, India, pp. 622--627. [PDF]
Associated People
- Million Meshesha
- Balasubramanian Anand
- Pramod Sankar K.
- Anand Kumar
- Dr. C. V. Jawahar