Retrieval from Large Document Image Collections
Overview
Extracting the relevant information out of a large number of documents is quite a challenging and tedious task.The quality of results generated by the traditionally available full-text search engine and text-based image retrieval systems is not very optimal. These Information Retrieval(IR) tasks become more challenging with the non-traditional language scripts for example in the case of Indic scripts. We have developed OCR (Optical Character Recognition) Search Engine which is an attempt to make an Information Retrieval and Extraction (IRE) system that replicates the current state-of-the-art methods using the IRE and basic Natural Language Processing (NLP) techniques. In this project we have tried to demonstrate the study of the methods that are being used for performing search and retrieval tasks. We also present the small descriptions of the functionalities supported in our system along with the statistics of the dataset. We use Indic-OCR developed at CVIT, for generating the text for the OCR Search Engine.
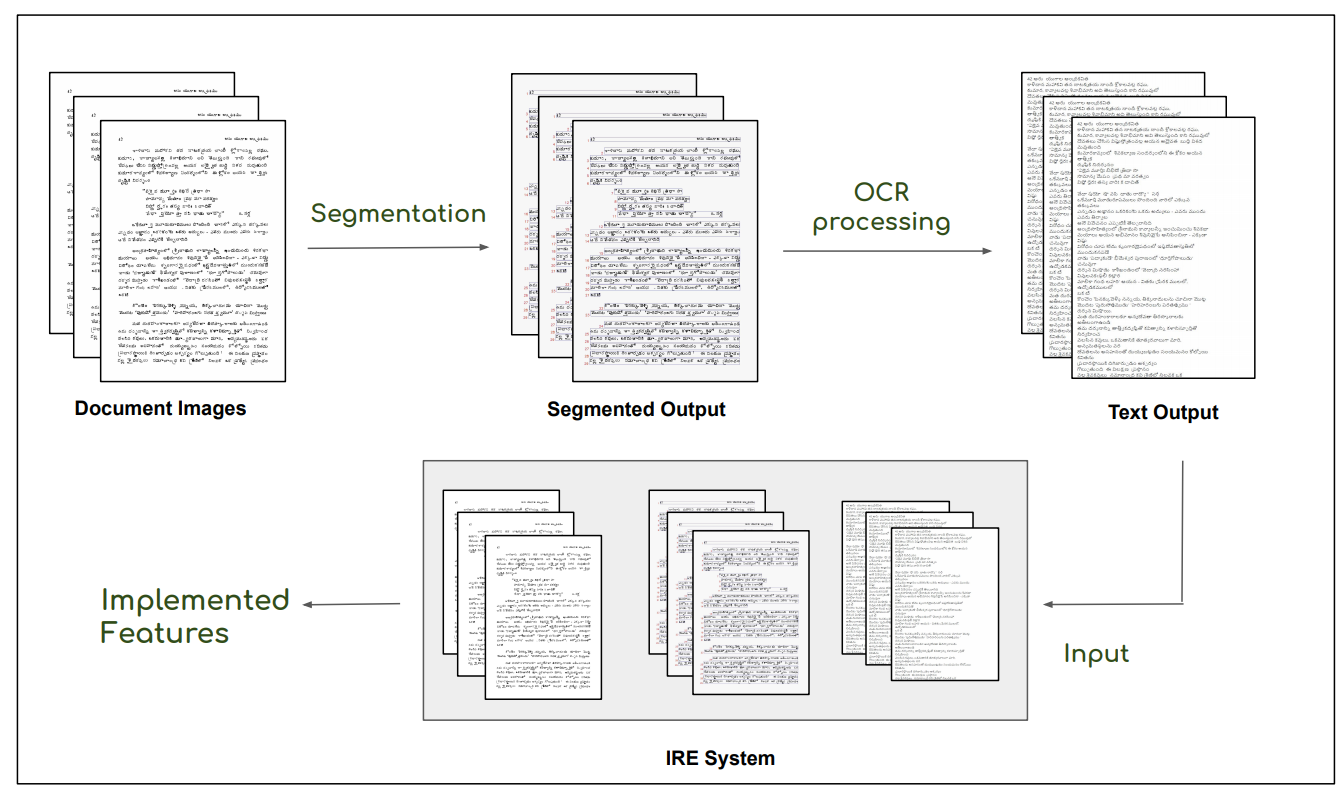 This is the basic pipeline followed by the OCR Search Engine. Digitised images after the preprocessing steps, ex. denoising, are passed through a segmentation pipeline, which generates line level segmentations for the document. These together are passed in the Indic OCR developed at CVIT that generates the text output . This text output, segmented output (line level segmentations) and document images form the database of the IRE system.
This is the basic pipeline followed by the OCR Search Engine. Digitised images after the preprocessing steps, ex. denoising, are passed through a segmentation pipeline, which generates line level segmentations for the document. These together are passed in the Indic OCR developed at CVIT that generates the text output . This text output, segmented output (line level segmentations) and document images form the database of the IRE system.
Functionalities implemented in the IRE system
The developed IRE system performs the following functionalities on the user end:
- Search is based on the keywords entered by the users in this case i.e whether they are single or multiple word query or the query with double quotes.
- Search is based on the language chosen. It also supports multilingual search which enables users to search the books with multiple languages, for instance in the case of "Bhagawadgitha" where a shlokaand its translation is provided.
- Search is based on how relevant the search results are and provide the users with the highlighted line/lines containing searched queries within the complete text.
- Additionally, primary (language, type, author, etc) and secondary(genre and source) filters for the books have been added to ease up the task of search.
- Our system also supports transliteration which enables users to take the benefit of the phonetics of the other language while typing.
Live Demo
--- We will update the link ---
Code available on : [Code]
Dataset
 The datasets (NDLI data & British library data) contains document images of the digitised books in the Indic languages
The datasets (NDLI data & British library data) contains document images of the digitised books in the Indic languages
The dataset provided for use consists of more than 1.5 million documents in languages Hindi, Telugu and Tamil (~ 5 lacs each). This dataset consists of the books from various genres such as religious texts, historical texts, science and philosophy. Dataset statistics are presented in the table given below.
 Statistics of the NDLI dataset and the British Library dataset.
Statistics of the NDLI dataset and the British Library dataset.
In addition to the existing Indic languages, we are also working on the Bangla data which is provided to us by the British Library. Our OCR model is trying to improve the text predictions for the same which will help in achieving better search results.
Acknowledgements
This work was supported, in part, by the National Digital Library of India (IIT Kharagpur) who provided us with more than 1.5 million document images in Indian languages (Hindi, Tamil and Telugu). We also thanks British Library for providing us with the ancient document images in Bangla language. I would also like to acknowledge Krishna Tulsyan for assisting the project, initially.
Contact
For further information about this project please feel free to contact :
Riya Gupta -
Dataset and Server Management: Varun Bhargavan, Aradhana Vinod [varun.bhargavan;aradhana.vinod]@research.iiit.ac.in