Early Anticipation of Driving Maneuvers
[Paper] [Code] [Dataset]
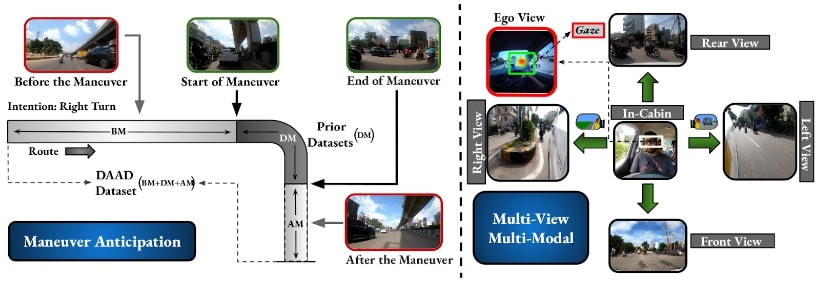
- Fig.: Overview of DAAD dataset for ADM task. Left: Shows previous datasets containing maneuver videos from their initiation to their execution (DM), whereas our DAAD dataset features longer video sequences providing prior context (BM), which proves beneficial for early maneuver anticipation. Right: Illustrates the multi-view and multi-modality (Gaze through the egocentric view) in DAAD for ADM.
Abstract
Prior works have addressed the problem of driver intention prediction (DIP) to identify maneuvers post their onset. On the other hand, early anticipation is equally important in scenarios that demand a preemptive response before a maneuver begins. However, there is no prior work aimed at addressing the problem of driver action anticipation before the onset of the maneuver, limiting the ability of the advanced driver assistance system (ADAS) for early maneuver anticipation. In this work, we introduce Anticipating Driving Maneuvers (ADM), a new task that enables driver action anticipation before the onset of the maneuver. To initiate research in this new task, we curate Driving Action Anticipation Dataset, DAAD, that is multi-view: in- and out-cabin views in dense and heterogeneous scenarios, and multimodal: egocentric view and gaze information. The dataset captures sequences both before the initiation and during the execution of a maneuver. During dataset collection, we also ensure to capture wide diversity in traffic scenarios, weather and illumination, and driveway conditions. Next, we propose a strong baseline based on transformer architecture to effectively model multiple views and modalities over longer video lengths. We benchmark the existing DIP methods on DAAD and related datasets. Finally, we perform an ablation study showing the effectiveness of multiple views and modalities in maneuver anticipation.
The DAAD dataset

Fig.: Data samples. DAAD in comparison to Brain4Cars, VIENA2 and HDD datasets. DAAD exhibits great diversity in various driving conditions (traffic density, day/night, weather, type of routes) across different driving maneuvers.
Results
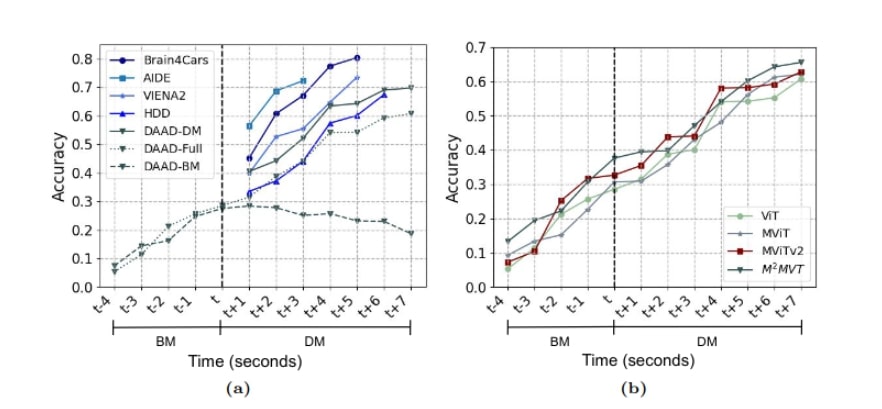
- Fig.: Effect of time-to-maneuver. (a) Accuracy over time for different driving datasets on CEMFormer (with ViT encoder). We conducted three separate experiments for the DAAD dataset. (i) DAAD-DM: Training and testing only on the maneuver sequences (DM). (ii) DAAD-Full: Training and testing on the whole video. (iii) DAAD-BM: Training on a portion of the video captured before the onset of maneuver (BM) and testing on the whole video; (b) Accuracy over time for our dataset on ViT, MViT, MViTv2 encoders, and the proposed method (M2MVT). Here, t is the time of onset of the maneuver.
Dataset
Citation
@inproceedings{adm2024daad,
author = {Abdul Wasi, Shankar Gangisetty, Shyam Nandan Rai and C. V. Jawahar},
title = {Early Anticipation of Driving Maneuvers},
booktitle = {ECCV (70)},
series = {Lecture Notes in Computer Science},
volume = {15128},
pages = {152--169},
publisher = {Springer},
year = {2024}
}
Acknowledgments
This work is supported by iHub-Data and mobility at IIIT Hyderabad.