Fine-Grained Descriptions for Domain Specific Videos
Abstract
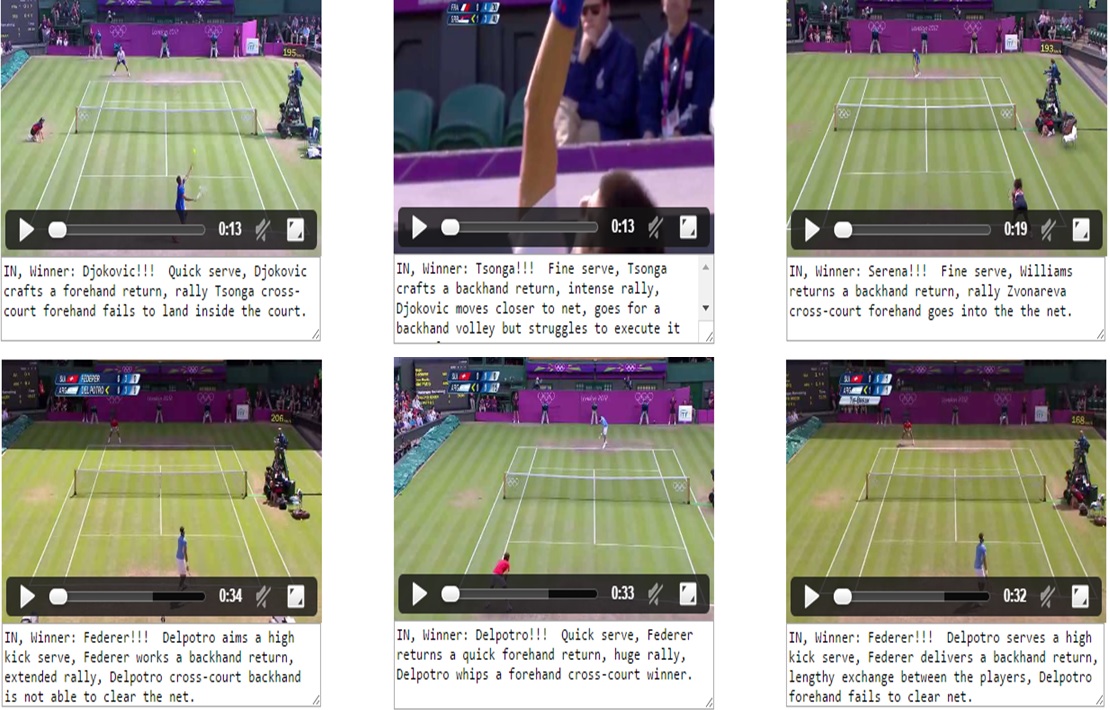
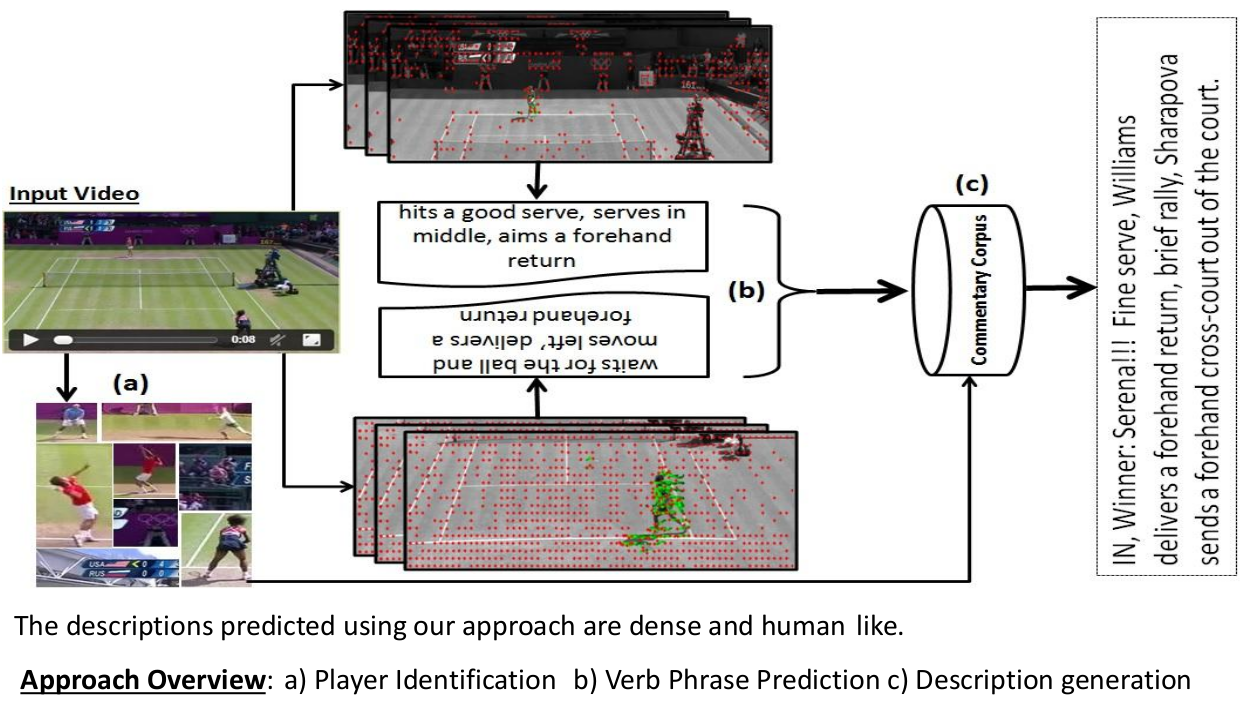
In this work, we attempt to describe videos from a specific domain - broadcast videos of lawn tennis matches. Given a video shot from a tennis match, we intend to generate a textual commentary similar to what a human expert would write on a sports website. Unlike many recent works that focus on generating short captions, we are interested in generating semantically richer descriptions. This demands a detailed low-level analysis of the video content, specially the actions and interactions among subjects. We address this by limiting our domain to the game of lawn tennis. Rich descriptions are generated by leveraging a large corpus of human created descriptions harvested from Internet. We evaluate our method on a newly created tennis video data set. Extensive analysis demonstrate that our approach addresses both semantic correctness as well as readability aspects involved in the task. We demonstrate the utility of the simultaneous use of vision, language and machine learning techniques in a domain specific environment to produce semantically rich and human-like descriptions. The proposed method can be well adopted to situations where activities are in a limited context and the linguistic diversity is confined.
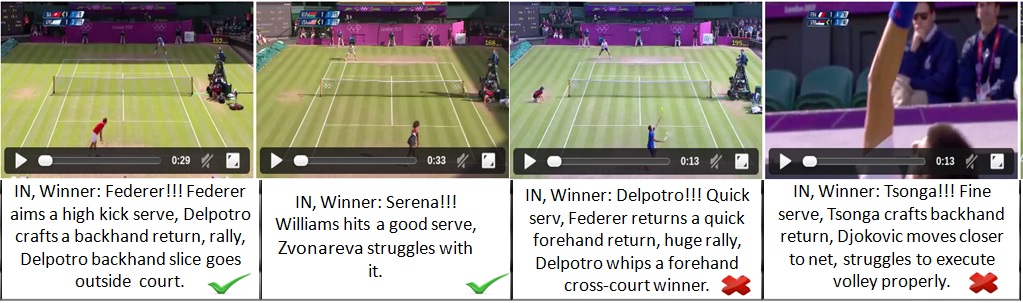
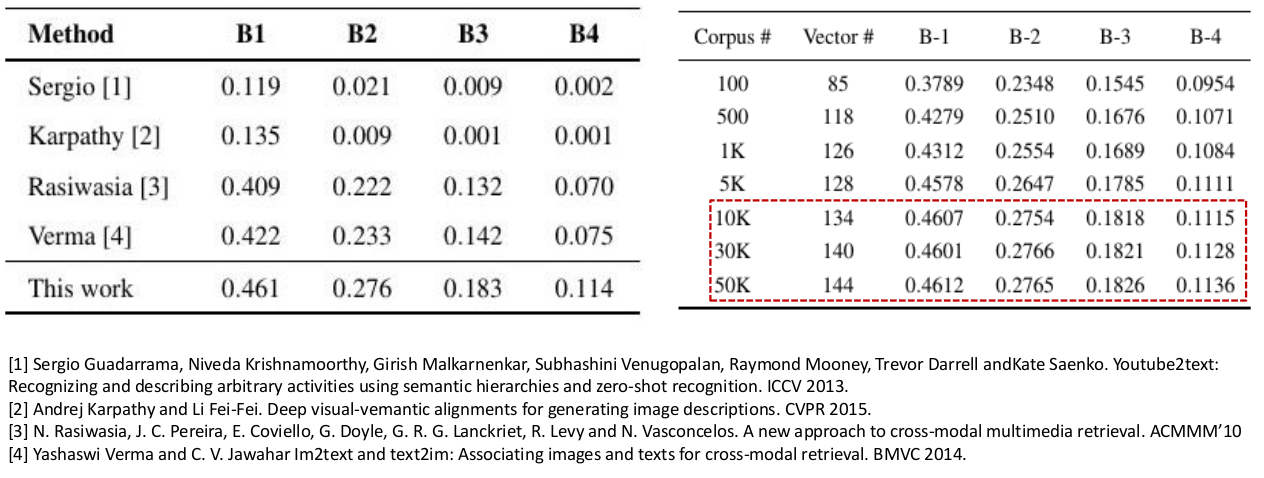
Results
Supplementary Video
Related Publications
- Mohak Sukhwani, C. V. Jawahar - "Tennis Vid2Text: Fine-grained Descriptions for Domain Specific Videos" Proceedings of the 26th British Machine Vision Conference, 07-10 Sep 2015, Swansea, UK. [Paper][Supplementary][Abstract][Poster]
Dataset
- Lawn Tennis Dataset: Dataset