Matching Handwritten Document Images
Abstract
We address the problem of predicting similarity between a pair of handwritten document images written by different individuals. This has applications related to matching and mining in image collections containing handwritten content. A similarity score is computed by detecting patterns of text re-usages between document images irrespective of the minor variations in word morphology, word ordering, layout and paraphrasing of the content. Our method does not depend on an accurate segmentation of words and lines. We formulate the document matching problem as a structured comparison of the word distributions across two document images. To match two word images, we propose a convolutional neural network based feature descriptor. Performance of this representation surpasses the state-of-the-art on handwritten word spotting. Finally, we demonstrate the applicability of our method on a practical problem of matching handwritten assignments.
Problem Statement
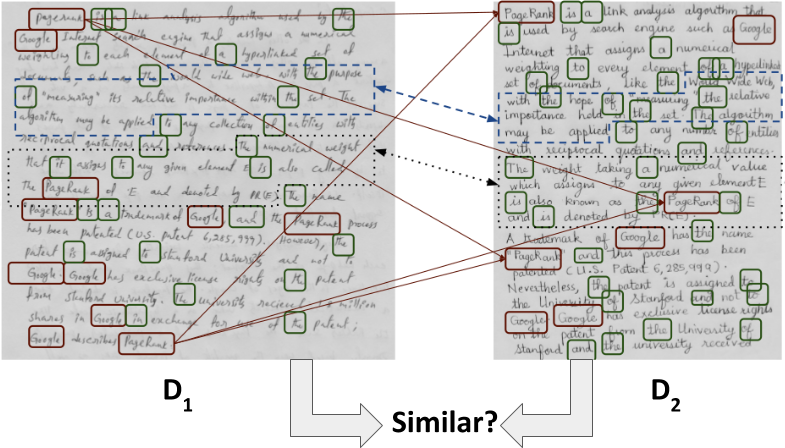
In this work, we compute a similarity score by detecting patterns of text re-usages across documents written by different individuals irrespective of the minor variations in word forms, word ordering, layout or paraphrasing of the content.
Major Contribution:
- To address the lack of data for training handwritten word images, we build a synthetic handwritten dataset of 9 million word images referred as IIIT-HWS dataset.
- We report a 56% error reduction in word spotting task on the challenging dataset of IAM and pages from George Washington collection.
- We also propose a normalized feature representation for word images which is invariant to different inflectional endings or suffixes present in words.
- We demonstrate two immediate applications (i) searching handwritten text from instructional videos, and (ii) comparing handwritten assignments.
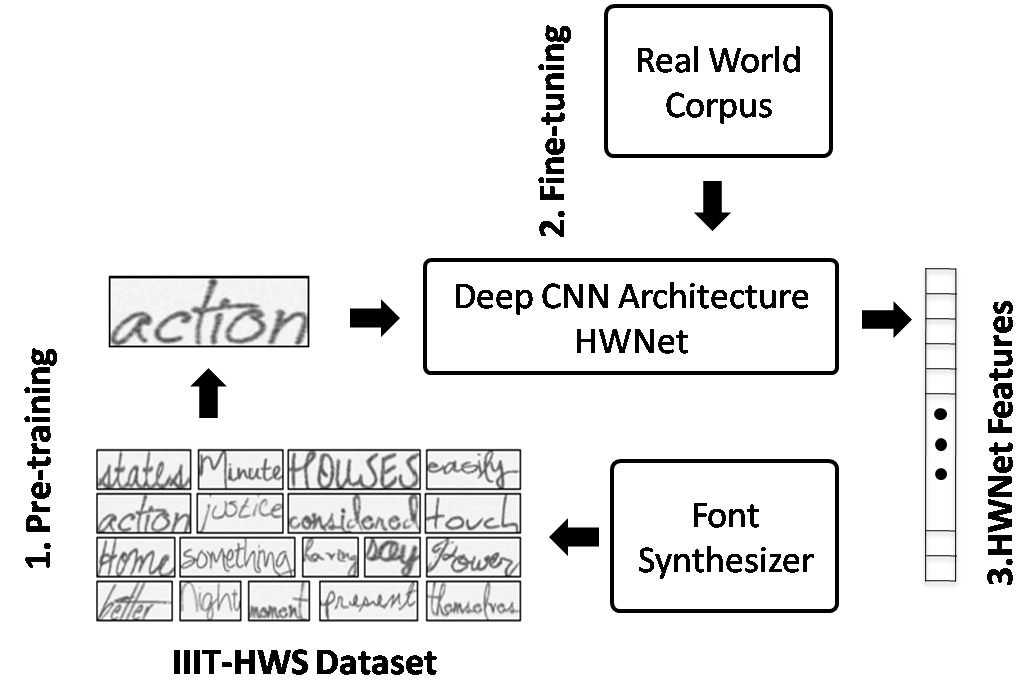
IIIT-HWS dataset

Generating synthetic images is an art which emulates the natural process of image generation in a closest possible manner. In this work, we exploit such a framework for data generation in handwritten domain. We render synthetic data using open source fonts and incorporate data augmentation schemes. As part of this work, we release 9M synthetic handwritten word image corpus which could be useful for training deep network architectures and advancing the performance in handwritten word spotting and recognition tasks.
Download link:
| Description | Download Link | File Size |
| Readme file | Readme | 4.0 KB |
| IIIT-HWS image corpus | IIIT-HWS | 32 GB |
| Ground truth files | GroundTruth | 229 MB |
Please cite the below paper in case you are using the dataset.
HWNet Architecture
Measure of document similarity (MODS)

Datasets and Codes
Please contact author
Related Papers
Praveen Krishnan and C.V Jawahar - Matching Handwritten Document Images, The 14th European Conference on Computer Vision (ECCV) – Amsterdam, The Netherlands, 2016. [PDF]
Contact