Visual Place Recognition in Unstructured Driving Environments
[ Paper ] [ Code ] [ Dataset ]

Fig. 1: Illustration of visual place recognition encountering various challenges across the three routes within our unstructured driving VPR dataset. The challenges include occlusions, traffic density changes, viewpoint changes, and variations in illumination.
Abstract
The problem of determining geolocation through visual inputs, known as Visual Place Recognition (VPR), has attracted significant attention in recent years owing to its potential applications in autonomous self-driving systems. The rising interest in these applications poses unique challenges, particularly the necessity for datasets encompassing unstructured environmental conditions to facilitate the development of robust VPR methods. In this paper, we address the VPR challenges by proposing an Indian driving VPR dataset that caters to the semantic diversity of unstructured driving environments like occlusions due to dynamic environments, variations in traffic density, viewpoint variability, and variability in lighting conditions. In unstructured driving environments, GPS signals are unreliable, often affecting the vehicle to accurately determine location. To address this challenge, we develop an interactive image-to-image tagging annotation tool to annotate large datasets with ground truth annotations for VPR training. Evaluation of the state-of-the-art methods on our dataset shows a significant performance drop of up to 15%, defeating a large number of standard VPR datasets. We also provide an exhaustive quantitative and qualitative experimental analysis of frontal-view, multi-view, and sequence-matching methods. We believe that our dataset will open new challenges for the VPR research community to build robust models. The dataset, code, and tool will be released on acceptance.
The IDD-VPR dataset
Data Capture and Collection
Table 1: Comparison of datasets for visual place recognition. Total length is the coverage multiplied by the number of times each route was traversed. Time span is from the first recording of a route to the last recording.
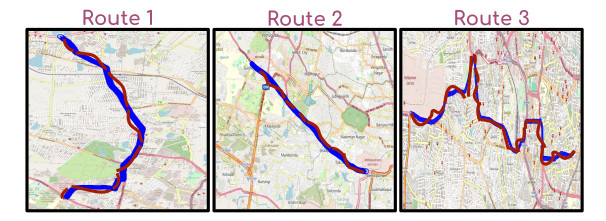
Fig. 2: Data collection map for the three routes. The map displays the actual routes (in blue color) taken and superimposed with maximum GPS drift due to signal loss (dashed lines in red color). This GPS inconsistency required manual correction.
Data Annotation
During data capture ensuring consistency and error-free GPS reading for all three route traversals was challenging as shown in Fig. 2. Through our image-to-image tagging annotation process, we ensured the consistency of each location being tagged with the appropriate GPS readings, maintaining a mean error of less than 10 meters. We developed an image-to-image matching annotation tool as presented in Fig. 3.
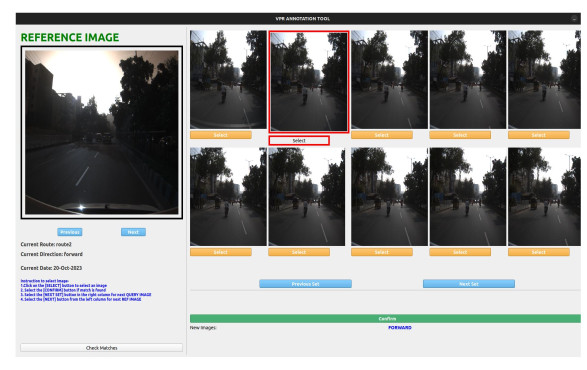
Fig. 3: Image-to-image annotation tool for (query, reference) pair matching by the annotators with GPS tagging.
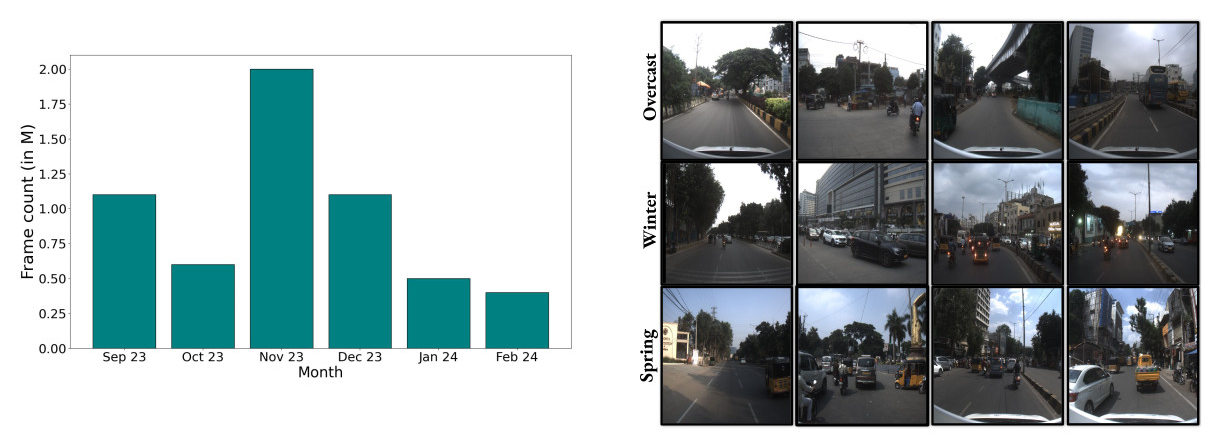
Fig. 4: Data capture span. Left: based on months and Right: diversity of samples encompasses different weather conditions, including overcast (Sep’23, Oct’23), winter (Dec’23, Jan’24), and spring (Feb’24).
Results
Frontal-View Place Recognition
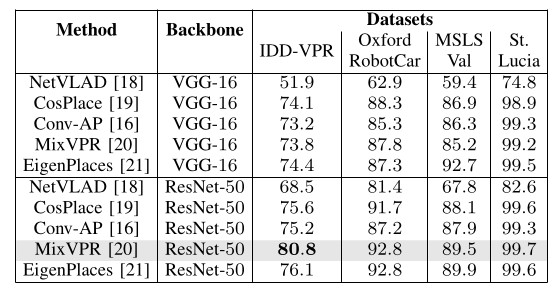
Table 2: Evaluation of baselines on Frontal-View datasets inclusive of IDD-VPR: Report overall recall@1, split by utilized backbone and descriptor dimension of 4096-D.
Multi-View Place Recognition
Table 2: Evaluation of baselines on Multi-View datasets inclusive of IDD-VPR: Report overall recall@1, split by utilized backbone and descriptor dimension of 4096-D.
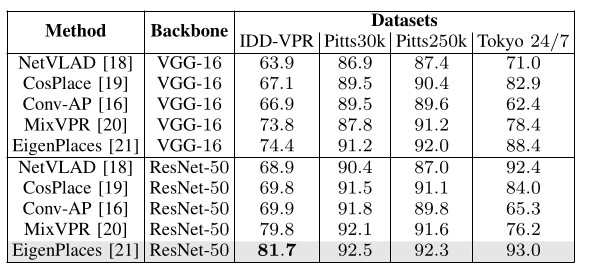

Fig. 5: Qualitative comparison of baselines on our dataset. The first column comprises query images of unstructured driving environmental challenges, while the subsequent columns showcase the retrieved images for each of the methods. Green: true positive; Red: false positive.
Citation
@inproceedings{idd2024vpr,
author = {Utkarsh Rai, Shankar Gangisetty, A. H. Abdul Hafez, Anbumani Subramanian and
C. V. Jawahar},
title = {Visual Place Recognition in Unstructured Driving Environments},
booktitle = {IROS},
pages = {10724--10731},
publisher = {IEEE},
year = {2024}
}
Acknowledgements
This work is supported by iHub-Data and Mobility at IIIT Hyderabad.