BoundaryNet - An Attentive Deep Network with Fast Marching Distance Maps for Semi-automatic Layout Annotation
Abstract
In this work, we propose BoundaryNet, a novel resizing-free approach for high-precision semi-automatic layout annotation. The variable-sized user selected region of interest is first processed by an attention-guided skip network. The network optimization is guided via Fast Marching distance maps to obtain a good quality initial boundary estimate and an associated feature representation. These outputs are processed by a Residual Graph Convolution Network optimized using Hausdorff loss to obtain the final region boundary. Results on a challenging image manuscript dataset demonstrate that BoundaryNet outperforms strong baselines and produces high-quality semantic region boundaries. Qualitatively, our approach generalizes across multiple document
image datasets containing different script systems and layouts, all without additional fine-tuning.
Architecture
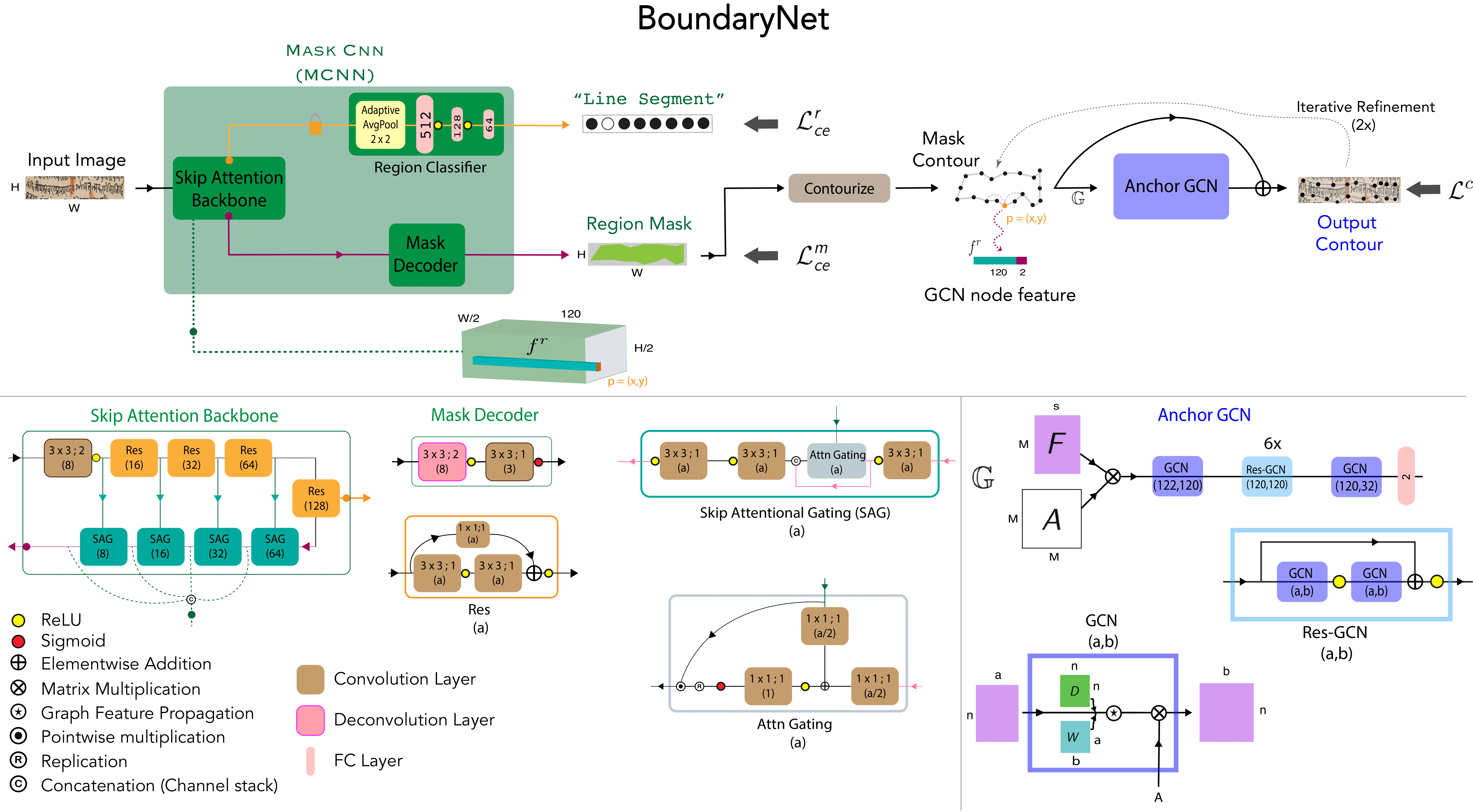 The architecture of BoundaryNet (top) and various sub-components (bottom). The variable-sized H×W input image is processed by Mask-CNN (MCNN) which predicts a region mask estimate and an associated region class. The mask’s boundary is determined using a contourization procedure (light brown) applied on the estimate from MCNN. M boundary points are sampled on the boundary. A graph is constructed with the points as nodes and edge connectivity defined by 6 k-hop neighborhoods of each point. The spatial coordinates of a boundary point location p = (x, y) and corresponding back- bone skip attention features from MCNN f^r are used as node features for the boundary point. The feature-augmented contour graph G = (F, A) is iteratively
processed by Anchor GCN to obtain the final output contour points defining the region boundary.
The architecture of BoundaryNet (top) and various sub-components (bottom). The variable-sized H×W input image is processed by Mask-CNN (MCNN) which predicts a region mask estimate and an associated region class. The mask’s boundary is determined using a contourization procedure (light brown) applied on the estimate from MCNN. M boundary points are sampled on the boundary. A graph is constructed with the points as nodes and edge connectivity defined by 6 k-hop neighborhoods of each point. The spatial coordinates of a boundary point location p = (x, y) and corresponding back- bone skip attention features from MCNN f^r are used as node features for the boundary point. The feature-augmented contour graph G = (F, A) is iteratively
processed by Anchor GCN to obtain the final output contour points defining the region boundary.
Instance-level Results from Bounding Box Supervision
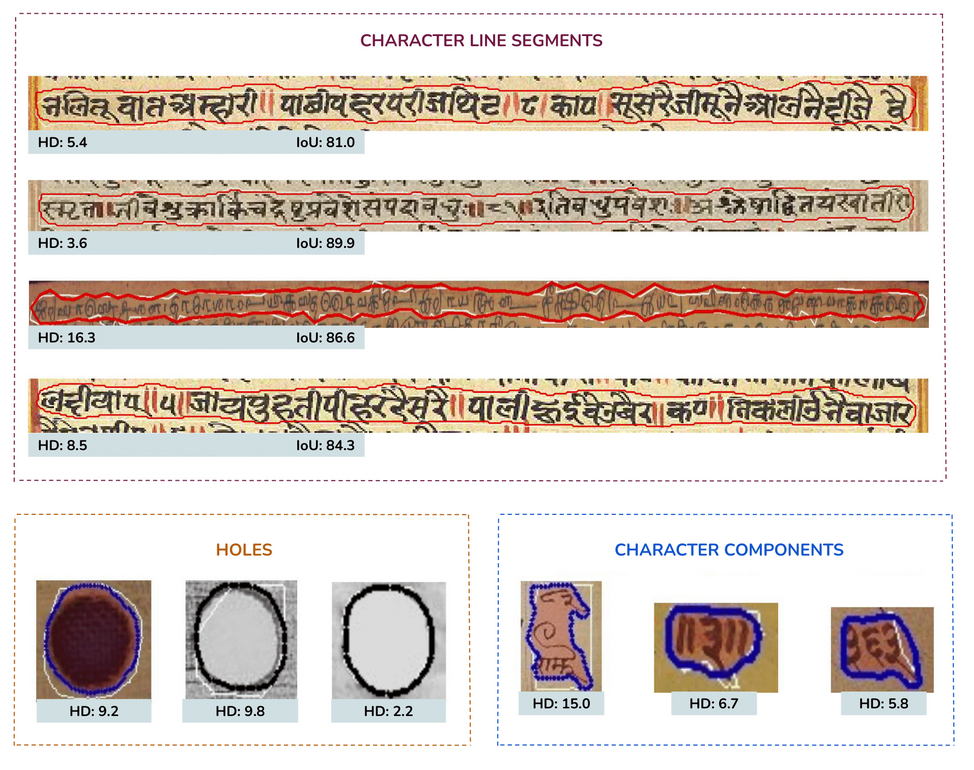
Page-level Results on Historical Documents

Interaction with Human Annotators
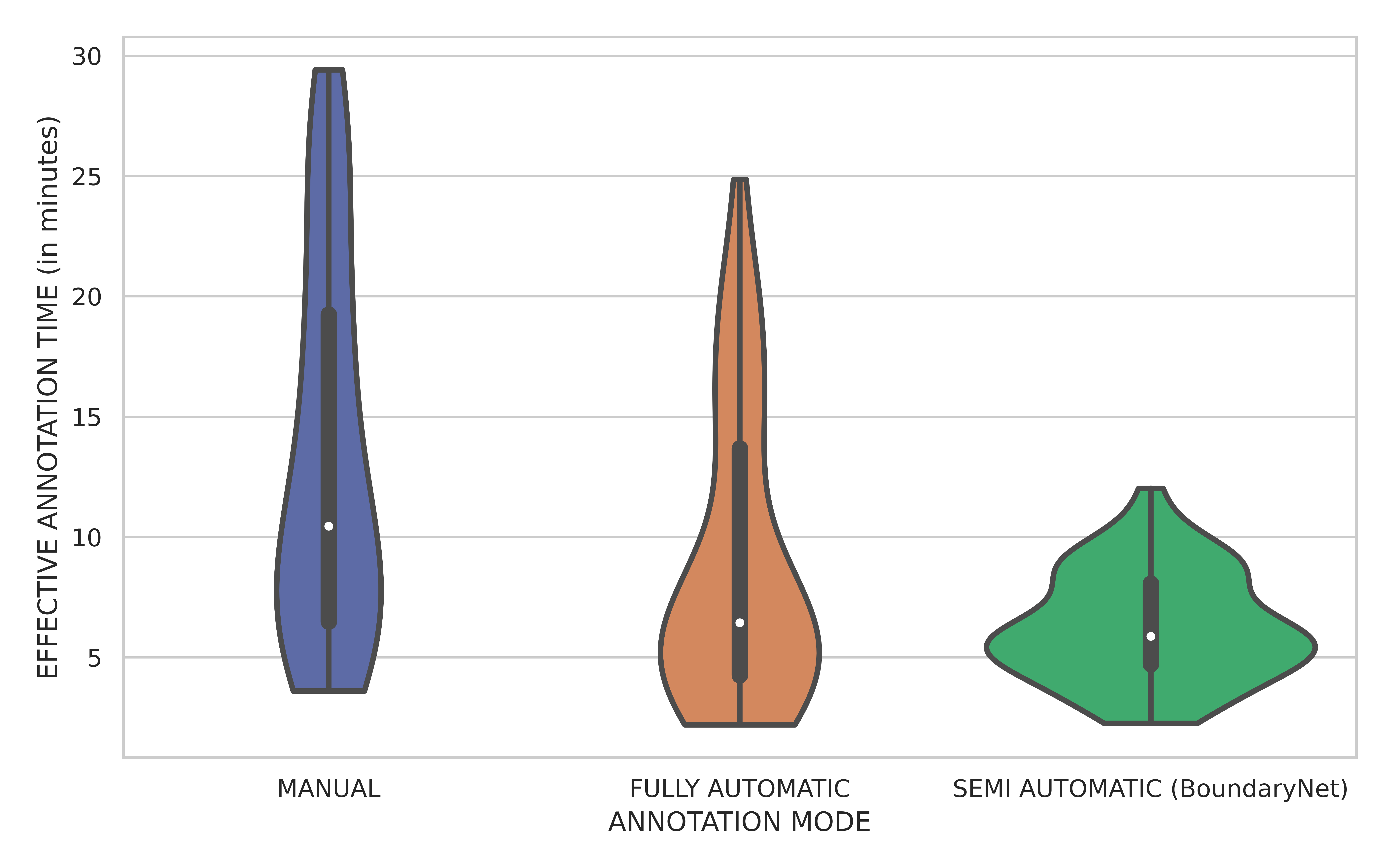 A small scale experiment was conducted with real human annotators in the loop to determine BoundaryNet utility in a practical setting. The annotations for a set of images were sourced using HINDOLA document annotation system in three distinct modes: Manual Mode (hand-drawn contour generation and region labelling), Fully Automatic Mode (using an existing instance segmentation approach- Indiscapes with post-correction using the annotation system) and Semi-Automatic Mode (manual input of region bounding boxes which are subsequently sent to BoundaryNet, followed by post-correction). For each mode, we recorded the end-to-end annotation time at per-document level, including manual correction time (Violin plots shown in the figure). BoundaryNet outperforms
other approaches by generating superior quality contours which minimize post-inference manual correction burden.
A small scale experiment was conducted with real human annotators in the loop to determine BoundaryNet utility in a practical setting. The annotations for a set of images were sourced using HINDOLA document annotation system in three distinct modes: Manual Mode (hand-drawn contour generation and region labelling), Fully Automatic Mode (using an existing instance segmentation approach- Indiscapes with post-correction using the annotation system) and Semi-Automatic Mode (manual input of region bounding boxes which are subsequently sent to BoundaryNet, followed by post-correction). For each mode, we recorded the end-to-end annotation time at per-document level, including manual correction time (Violin plots shown in the figure). BoundaryNet outperforms
other approaches by generating superior quality contours which minimize post-inference manual correction burden.
Citation
@inProceedings{trivedi2021boundarynet,
title = {BoundaryNet: An Attentive Deep Network with Fast Marching Distance Maps for Semi-automatic
Layout Annotation},
author = {Trivedi, Abhishek and Sarvadevabhatla, Ravi Kiran},
booktitile = {International Conference on Document Analysis and Recognition},
year = {2021}
}
Contact
If you have any question, please contact Dr. Ravi Kiran Sarvadevabhatla at