Visual Speech Enhancement Without a Real Visual Stream
Sindhu Hegde*, Prajwal Renukanand* Rudrabha Mukhopadhyay* Vinay Namboodiri C.V. Jawahar
IIIT Hyderabad Univ. of Bath
[Code] [Paper] [Demo Video] [Test Sets]
WACV, 2021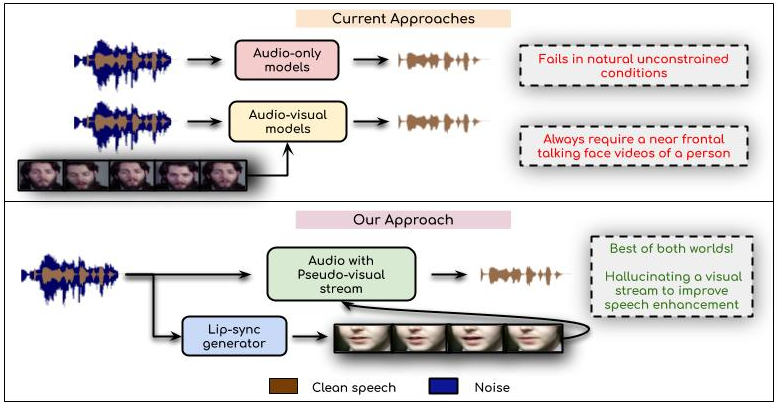
We propose a novel approach to enhance the speech by hallucinating the visual stream for any given noisy audio. In contrast to the existing audio-visual methods, our approach works even in the absence of a reliable visual stream, while also performing better than audio-only works in unconstrained conditions due to the assistance of generated lip movements.
Abstract
In this work, we re-think the task of speech enhancement in unconstrained real-world environments. Current state-of-the-art methods use only the audio stream and are limited in their performance in a wide range of real-world noises. Recent works using lip movements as additional cues improve the quality of generated speech over ``audio-only" methods. But, these methods cannot be used for several applications where the visual stream is unreliable or completely absent. We propose a new paradigm for speech enhancement by exploiting recent breakthroughs in speech-driven lip synthesis. Using one such model as a teacher network, we train a robust student network to produce accurate lip movements that mask away the noise, thus acting as a ``visual noise filter". The intelligibility of the speech enhanced by our pseudo-lip approach is almost close (< 3\% difference) to the case of using real lips. This implies that we can exploit the advantages of using lip movements even in the absence of a real video stream. We rigorously evaluate our model using quantitative metrics as well as qualitative human evaluations. Additional ablation studies and a demo video in the supplementary material containing qualitative comparisons and results clearly illustrate the effectiveness of our approach.
Paper

Demo
Please click on this link : https://www.youtube.com/watch?v=y_oP9t7WEn4&feature=youtu.be
Contact
- Sindhu Hegde -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Prajwal K R -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Rudrabha Mukhopadhyay -
This email address is being protected from spambots. You need JavaScript enabled to view it.