My View is the Best View: Procedure Learning from Egocentric Videos
Siddhant Bansal Chetan Arora and C.V. Jawahar
ECCV 2022
What is Procedure Learning?

EgoProceL Dataset
EgoProceL is a large-scale dataset for procedure learning. It consists of 62 hours of egocentric videos recorded by 130 subjects performing 16 tasks for procedure learning. EgoProceL contains videos and key-step annotations for multiple tasks from CMU-MMAC, EGTEA Gaze+, and individual tasks like toy-bike assembly, tent assembly, PC assembly, and PC disassembly.
Why an egocentric dataset for Procedure Learning?

Overview of EgoProceL
EgoProceL consists of
- 62 hours of videos captured by
- 130 subjects
- performing 16 tasks
- maximum of 17 key-steps
- average 0.38 foreground ratio
- average 0.12 missing steps ratio
- average 0.49 repeated steps ratio
Downloads
We recommend referring to the README before downloading the videos. Mirror link.
Videos
Link: pc-assembly
Link: pc-disassembly
Annotations
Link: Google Drive
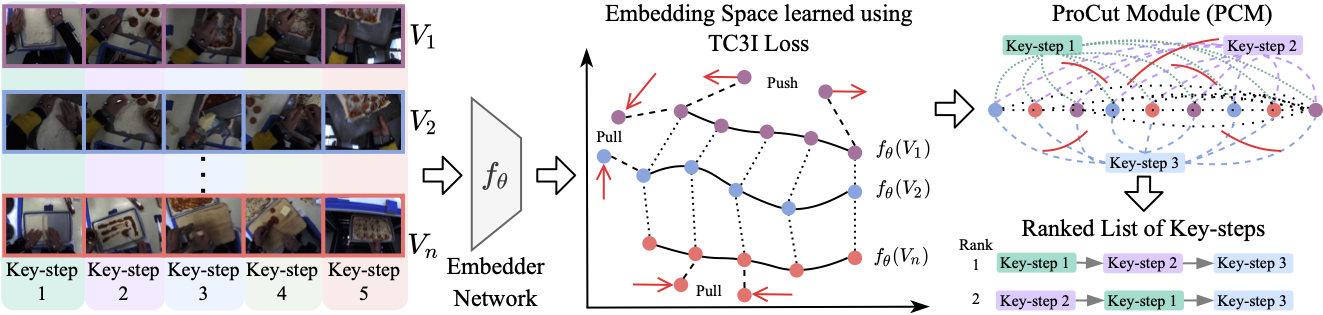
CnC framework for Procedure Learning
We present a novel self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC identifies and utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure. Our experiments show that CnC outperforms the state-of-the-art on the benchmark ProceL and CrossTask datasets by 5.2% and 6.3%, respectively.
Paper
- PDF: Paper; Supplementary
- arXiv: Paper; Abstract
- ECCV: Coming soon!
Code
The code for this work is available on GitHub!
Link: Sid2697/EgoProceL-egocentric-procedure-learning
Acknowledgements
This work was supported in part by the Department of Science and Technology, Government of India, under DST/ICPS/Data-Science project ID T-138. A portion of the data used in this paper was obtained from kitchen.cs.cmu.edu and the data collection was funded in part by the National Science Foundation under Grant No. EEEC-0540865. We acknowledge Pravin Nagar and Sagar Verma for recording and sharing the PC Assembly and Disassembly videos at IIIT Delhi. We also acknowledge Jehlum Vitasta Pandit and Astha Bansal for their help with annotating a portion of EgoProceL.
Please consider citing if you make use of the EgoProceL dataset and/or the corresponding code:
@InProceedings{EgoProceLECCV2022,
author="Bansal, Siddhant
and Arora, Chetan
and Jawahar, C.V.",
title="My View is the Best View: Procedure Learning from Egocentric Videos",
booktitle = "European Conference on Computer Vision (ECCV)",
year="2022"
}
@InProceedings{CMU_Kitchens,
author = "De La Torre, F. and Hodgins, J. and Bargteil, A. and Martin, X. and Macey, J. and Collado, A. and Beltran, P.",
title = "Guide to the Carnegie Mellon University Multimodal Activity (CMU-MMAC) database.",
booktitle = "Robotics Institute",
year = "2008"
}
@InProceedings{egtea_gaze_p,
author = "Li, Yin and Liu, Miao and Rehg, James M.",
title = "In the Eye of Beholder: Joint Learning of Gaze and Actions in First Person Video",
booktitle = "European Conference on Computer Vision (ECCV)",
year = "2018"
}
@InProceedings{meccano,
author = "Ragusa, Francesco and Furnari, Antonino and Livatino, Salvatore and Farinella, Giovanni Maria",
title = "The MECCANO Dataset: Understanding Human-Object Interactions From Egocentric Videos in an Industrial-Like Domain",
booktitle = "Winter Conference on Applications of Computer Vision (WACV)",
year = "2021"
}
@InProceedings{tent,
author = "Jang, Youngkyoon and Sullivan, Brian and Ludwig, Casimir and Gilchrist, Iain and Damen, Dima and Mayol-Cuevas, Walterio",
title = "EPIC-Tent: An Egocentric Video Dataset for Camping Tent Assembly",
booktitle = "International Conference on Computer Vision (ICCV) Workshops",
year = "2019"
}