Audio-Visual Face Reenactment
Madhav Agarwal, Rudrabha Mukhopadhyay, Vinay Namboodiri and C.V. Jawahar
IIIT Hyderabad Univ. of Bath
WACV, 2023
[ Code ] | [ Interactive Demo ] | [ Demo Video ]
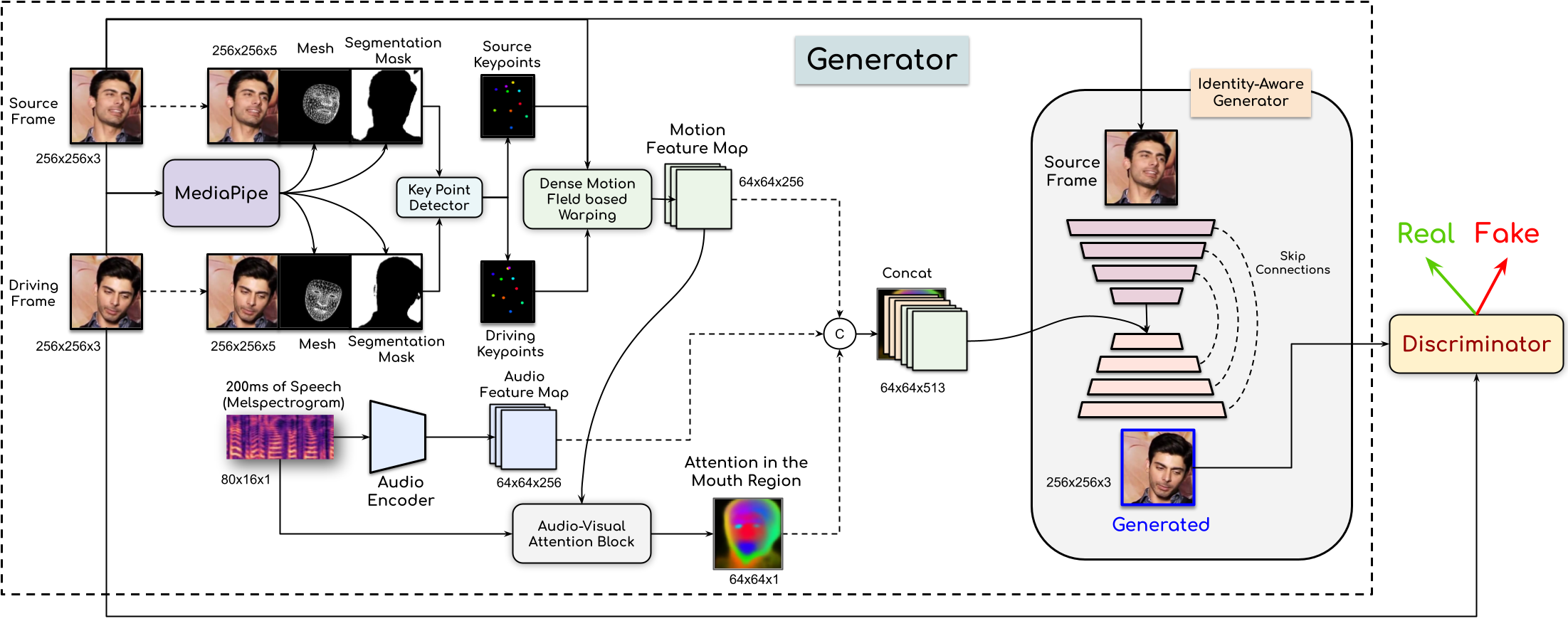
The overall pipeline of our proposed Audio Visual Face Reenactment network (AVFR-GAN) is given in this Figure. We take source and driving images along with their face mesh and segmentation mask to extract keypoints. An audio encoder extracts features from driving audio and use them provide attention on lip region. The audio and visual feature maps are warped together and passed to the carefully designed Identity-Aware Generator along with extracted features of source image to generate the final output.
Abstract
This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls.
Paper
-

Audio-Visual Face Reenactment
Madhav Agarwal, Rudrabha Mukhopadhyay, Vinay Namboodiri and C.V. Jawahar
IEEE/CVF Winter Conference on Applications of Computer Vision,WACV, 2023.
[PDF ] | [BibTeX]@InProceedings{Agarwal_2023_WACV,
author = {Agarwal, Madhav and Mukhopadhyay, Rudrabha and Namboodiri, Vinay P. and Jawahar, C. V.},
title = {Audio-Visual Face Reenactment},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2023},
pages = {5178-5187}
}
Demo
Contact
- Madhav Agarwal -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Rudrabha Mukhopadhyay -
This email address is being protected from spambots. You need JavaScript enabled to view it.