Learning Appearance Models
Introduction
Our reseach focuses on learning appearance models from images/videos that can be used for a variety of tasks such as recognition, detection and classification etc. Prior information such as geometry and kinematics is used to improve the quality of appearance models learnt thus enabling better performance at these tasks.
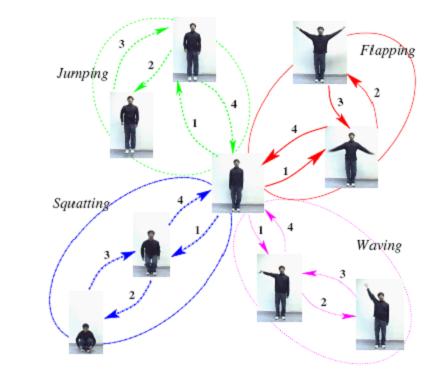
Dynamic Activity Recognition
Many of the human activities such as Jumping, Squatting have a correlated spatiotemporal structure. They are composed of homogeneous units. These units, which we refer to as actions, are often common to more than one activity. Therefore, it is essential to have a representation which can capture these activities effectively. To develop this, we model the frames of activities as a mixture model of actions and employ a probabilistic approach to learn their low-dimensional representation. We present recognition results on seven activities performed by various individuals. The results demonstrate the versatility and the ability of the model to capture the ensemble of human activities.
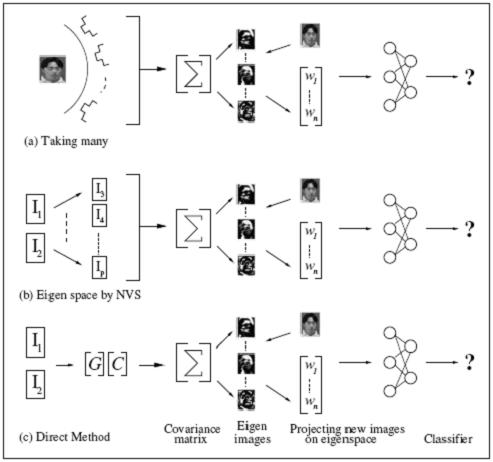
Boosting Appearance Models using Geometry
We developed novel method to construct an eigen space representation from limited number of views, which is equivalent to the one typically obtained from large number of images. This procedure implicitly incorporates a novel view synthesis algorithm in the eigen space construction process. Inherent information in an appearance representation is enhanced using geometric computations. We experimentally verify the performance for orthographic, affine and projective camera models. Recognition results on the COIL and SOIL image database are promising.
Face Video Manipulation using Tensorial Fatorization

We use Tensor Factorization for manipulating videos of human faces. Decomposition of a video represented as a tensor into non-negative rank-1 factors results in sparse and separable factors equivalent to a local parts decomposition of the object in the video. Such a decomposition can be used for tasks like expression transfer and face morphing. For instance, given a facial expression video it can be represented as a tensor which can then be factorized. The factors that best represent the expression can be identied which can then be transfered to another face video thus transferring the expression. A good solution to the problem of expression transfer would require explicit modeling of the expression and its interaction with the underlying face content. Instead the method proposed here is purely appearance based and the results demonstrate that the proposed method is a simple alternative to the popular complex solution.
Related Publication
S. Manikandan, Ranjeeth Kumar and C.V. Jawahar - Tensorial Factorization Methods for Manipulation of Face Videos, The 3rd International Conference on Visual Information Engineering (VIE), 26-28 September 2006 in Bangalore, India. [PDF]
Ranjeeth Kumar, S. Manikandan and C. V. Jawahar - Task Specific Factors for Video Characterization, 5th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Madurai, India, LNCS 4338 pp.376-387, 2006. [PDF]
Paresh K. Jain, Kartik Rao P. and C. V. Jawahar - Computing Eigen Space from Limited Number of Views for Recognition, 5th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Madurai, India, LNCS 4338 pp.662-673, 2006. [PDF]
S. S. Ravi Kiran, Karteek Alahari and C. V. Jawahar, Recognizing Human Activities from Constituent Actions, Proceedings of the National Conference on Communications (NCC), Jan. 2005, Kharagpur, India, pp. 351-355. [PDF]