Retrieval from Video Databases
Introduction
Broadcast Television is one of the primary and popular sources of information. With the advent of video recorders, TV programs could be recorded and stored locally. Digital Libraries of broadcast videos could be easily built with existing technology. The storage, archival, search and retrieval of broadcast videos provide a large number of challenges for the research community. The following projects address these challenges.
Building a Digital Library of Broadcast Videos
Digital libraries of broadcast videos allows one to archive television content for later viewing and reference. The importance and significance of such a library is similar to building a digital library for all books. The collection in the library is built by recording TV. Since it is difficult to record and store all channels simultaneously, a schedule is chosen to record programmes across various channels. An UI allows users to choose the schedule to be recorded for later viewing.
The videos are stored over multiple nodes that act as a storage cluster. An explicit file system structure is maintained for storing the videos. The file system incorporates the meta level information regarding the videos, such as date, time and channel recorded from. This allows users to easily browse and search the library for programs using these details.
Indexing Broadcast News
Broadcast news is a class of multimedia that is of importance to both the scientific community and the general public. In broadcast news, the requirement is to provide content-level search and retrieval, which is very challenging. Though many broadcast news datasets are available, there is no collection pertaining to news in the Indian context. We built a system to automatically record and build a respository of Indian news broadcasts.
Our present collection consists of more than a month's news telecasts, recorded from 5 different news channels, covering 3 languages. The size of the collection is an ever increasing number, and is currently limited by the storage space available.
The videos are first divided into stories, by detecting the anchor-person. A keyframe is extracted from each of the shots in the story. An effective and intuitive way of visualising the videos is designed such that the user can get a feel of the content without actually needing to stream the videos and see them. Each video is presented as a slide show of the thumbnails of the constituent shots. User can zoom in on any thumbnail by hovering the mouse pointer over it. The adjacent figure shows a screenshot of this UI.
Searching News Using Overlaid Text (Without Characrter Recognition)
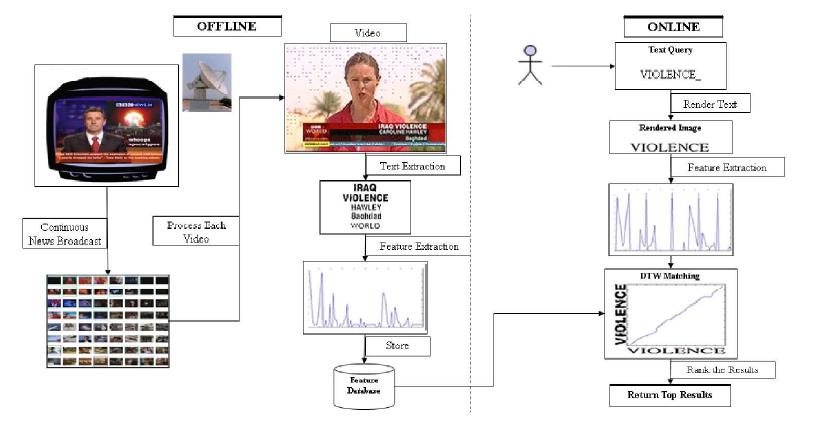
There have been several appraoches to video indexing and retrieval, based on spatio-temporal visual features. However, they are not always reliable and do not allow for easy querying. News video have many clues regarding the content of the video, in the form of overlaid text. This text is reliable for video indexing and retrieval. However, the recognition of overlaid text is difficult, due to the limited accuracy of Optical Character Recognisers (OCR). The inaccuracies are more pronounced in the context of Indian languages, which have a complex script and writing style.
To avoid explicit recognition, we use a novel recognition-free approach that matches words in the image space. Each word extracted from the videos is represented as a feature vector, the features carefully chosen to provide invariance to font type, style and size variations. Given a textual query, the word is rendered into an image and features are extracted from it. The query features are compared to those in the database, using a Dynamic Time Warping (DTW) based distance measure. The words in the databse that have high similarity with the query, are obtained, and the source videos are retrieved for the user.
Automatic Annotation of Cricket Videos
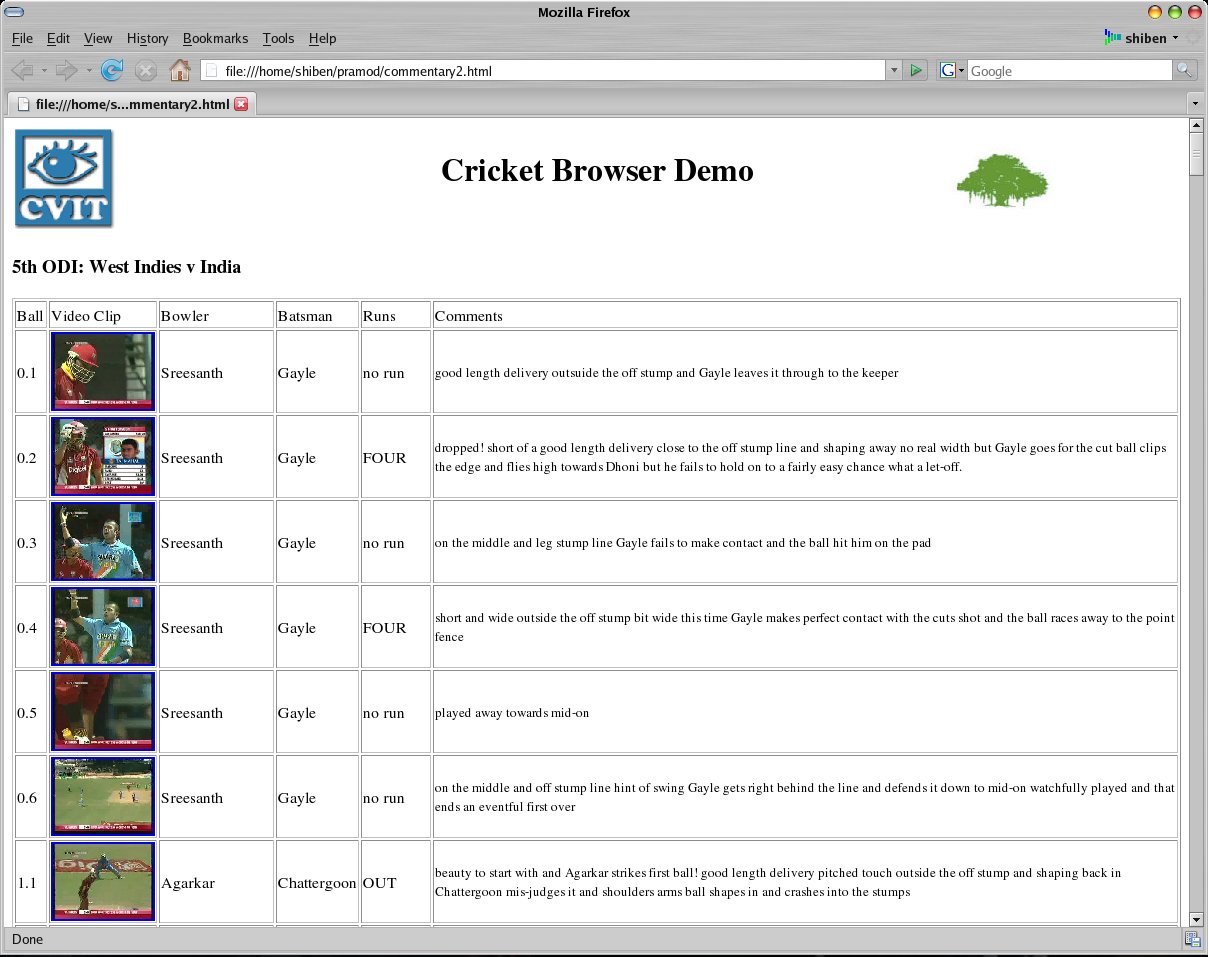
Sports videos are another popular class of multimedia. Sports videos are generally long where only a small part of the video is of real interest. The video is a sequence of action scenes, which occur semi-regularly. It was further observed that, for sports such as Cricket, detailed descriptions of these scenes is provided in the form of textual commentary available from online websites (such as www.cricinfo.com). This description is excellent for annotation and retrieval.
However, there is no explicit synchronisation between the textual descriptions, and the video segments that they correspond to. The synchronisation is achieved by using the text to drive the segmentation of the video. The scene categories are modeled in a suitable (visual) feature space, and the text is used to obtain the category of each scene in the video. A hypothetical video is generated from the text, which is aligned with the real video using Dynamic Programming. The scenes in the real video are segmented based on the known scene boundaries of the hypothetical video.
Once segmented, the scenes are automatically annotated with the detailed textual descriptions which allows us to build a Table-of-Contents representation for the entire video. This interface is very intutitve and allows for easy browsing of the video using the corresponding text. The text can now be used to index the videos, which allows for video retrieval using texttual queries (of semantic concepts).
Ongoing Work
In ongoing work, we are addressing various novel directions for enabling retrieval from video collections. In one of the projects for annotating news videos, we are using the people in the news to identify the news content. Faces in the news are annotated with the name of the person, and the news stories can be queried based on the people involved in it.
In another ongoing project, we are exploring the use of various compressed domain techniques for video data retrieval and mining. Videos are generally stored in the MPEG format which is a compressed domain representation. The use of a large number of exisiting techniques for compressed domain, avoids explicit decoding of video, and can convey further information without visual recognition and understanding.
Related Publications
Pramod Sankar K., Saurabh Pandey and C. V. Jawahar - Text Driven Temporal Segmentation of Cricket Videos , 5th Indian Conference on Computer Vision, Graphics and Image Processing, Madurai, India, LNCS 4338 pp.433-444, 2006. [PDF]
C. V. Jawahar, Balakrishna Chennupati, Balamanohar Paluri and Nataraj Jammalamadaka, Video Retrieval Based on Textual Queries , Proceedings of the Thirteenth International Conference on Advanced Computing and Communications (ICACCS), Coimbatore, December 2005. [PDF]
Associated People
- Tarun Jain
- Anurag Singh Rana
- Balakrishna C.
- Pramod Sankar K.
- Saurabh Pandey
- Balamanohar P.
- Natraj J.
- Dr. C. V. Jawahar