Bringing Semantics in Word Image Representation
Overview
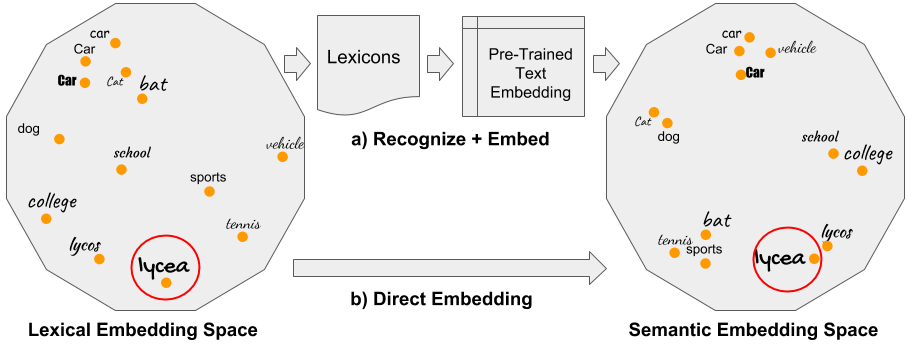
In the domain of document images, for decades we have appreciated the need for learning a holistic word level representation, that is popularly used for the task of word spotting. However, in the past we have restricted the representations which only respect the word form, while completely ignoring its meaning. In this work, we attempt to bridge this gap by encoding the notion of semantics by introducing two novel form of word image representations. The first form learns an inflection invariant representation, thereby focusing on the root of the word, while the second form is built along the lines of recent textual word embedding techniques such as Word2Vec and has much broader scope for semantic relationships. We observe that such representations are useful for both traditional word spotting and also enrich the search results by accounting the semantic nature of the task.
Contributions:
- We propose a normalized word representation which is invariant to word form inflections. The representation achieves state of the art performance as compared to a conventional verbatim based representation.
- We introduce a novel semantic representation for word images which respects both its form and meaning, thereby reducing the vocabulary gap that exists between the query and its retrieved results.
- We demonstrate semantic word spotting task and evaluate the proposed representation on standard IR measures such word analogy and word similarity.
- The proposed representation is successfully demonstrated on both historical and modern document collections in printed and handwritten domains across Latin and Indic scripts.
Codes and Dataset :
Qualitative Results

Related Papers
Contact