IndicDLP : A Foundational Dataset for Multi-Lingual and Multi-Domain Document Layout Parsing
ICDAR 2025 (Oral) — 🏆 Best Student Paper Runner-Up Award
[Paper] [Code] [Dataset]


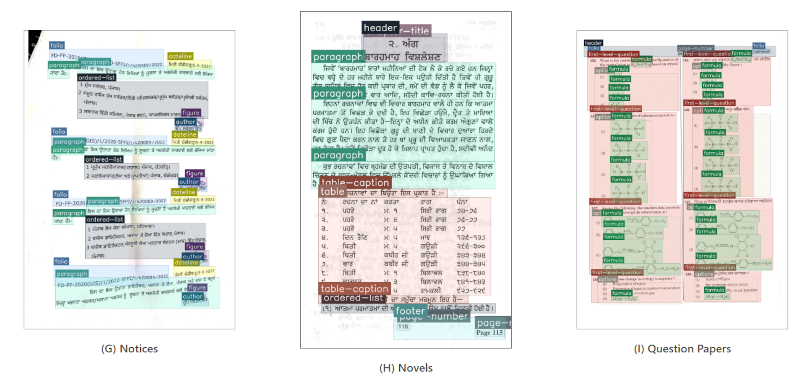

Samples from the IndicDLP dataset highlighting its diversity across document formats, domains, languages, and temporal span. For improved differentiability, segmentation masks are used instead of bounding boxes to highlight regions more effectively.
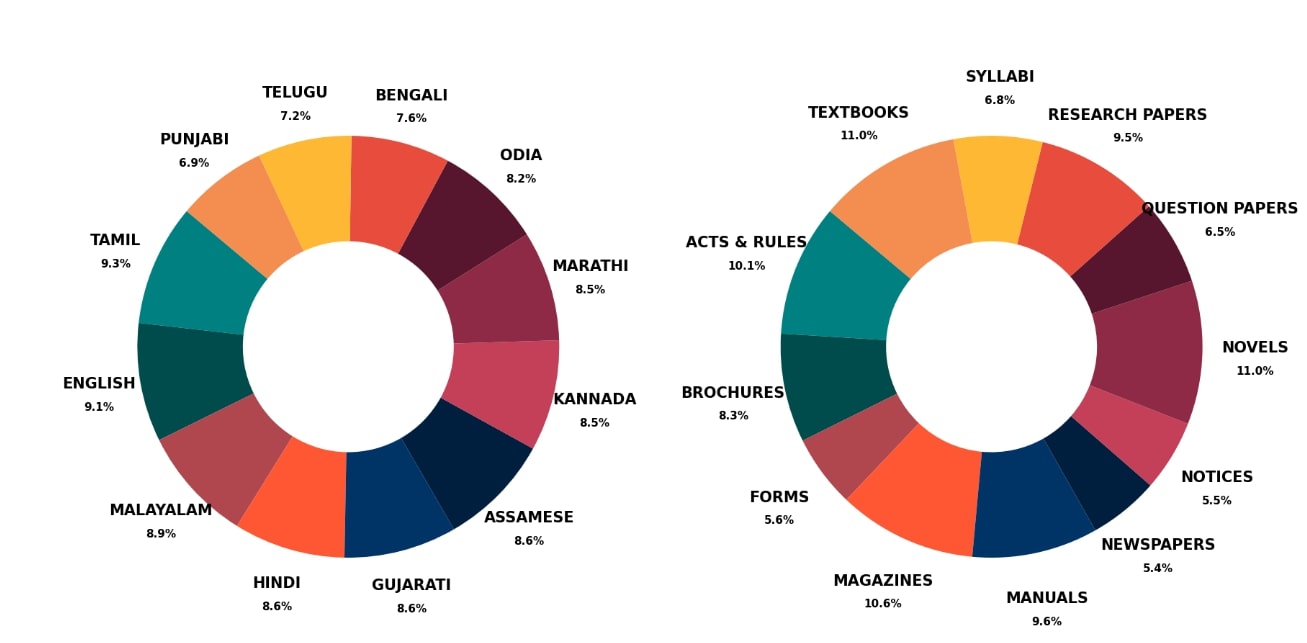
The above figure illustrates the contributions of 12 languages (left) and 12 document domains (right) in the IndicDLP dataset. The distribution is fairly balanced across both categories, with no single language or domain overwhelmingly dominating the dataset. This ensures a diverse and well-represented collection.
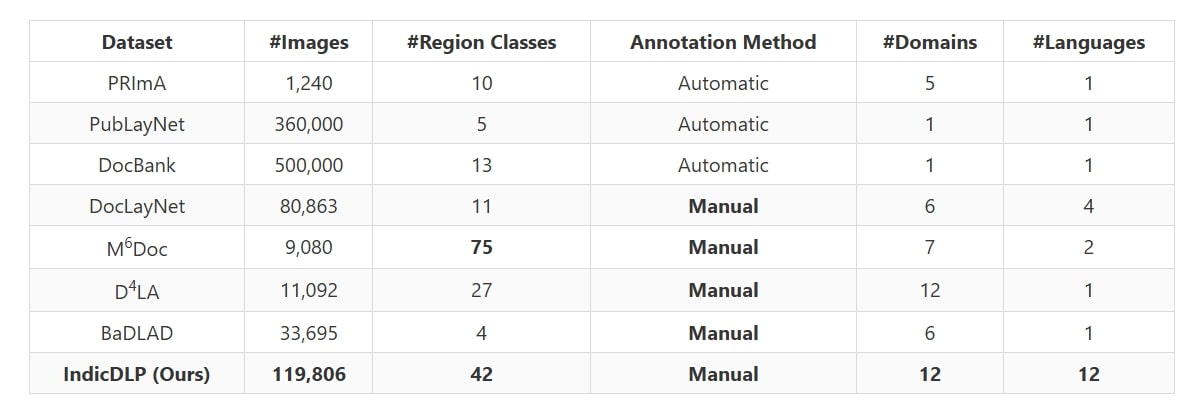
Comparison of modern document layout parsing datasets.
Citation
Please cite our paper if you find this dataset or work useful:
@Inproceedings{10.1007/978-3-032-04614-7_2,
author = {Oikantik Nath, Sahithi Kukkala, Mitesh Khapra, Sarvadevabhatla, Ravi Kiran},
editor = {Xu-Cheng Yin, Dimosthenis Karatzas, and and Daniel Lopresti },
title = {IndicDLP: A Foundational Dataset for Multi-lingual and Multi-domain Document Layout Parsing},
booktitle = {Document Analysis and Recognition -- ICDAR 2025},
year = {2026}
publisher = {Springer Nature Switzerland},
address = {Cham},
pages = {23--39},
abstract = {Document layout analysis is essential for downstream tasks such as information retrieval,
extraction, OCR, and digitisation. However, existing large-scale datasets like PubLayNet and DocBank lack
fine-grained region labels and multilingual diversity, making them insufficient for representing complex documents
layouts. Human-annotated datasets such as {\$}{\$}M^{\{}6{\}}Doc{\$}{\$}M6Doc and {\$}{\$}{\backslash}text
{\{}D{\}}^{\{}4{\}}{\backslash}text {\{}LA{\}}{\$}{\$}D4LA offer richer labels and greater domain diversity,
but are too small to train robust models and lack adequate multilingual coverage. This gap is especially
pronounced for Indic documents, which encompass diverse scripts yet remain underrepresented in current datasets,
further limiting progress in this space. To address these shortcomings, we introduce IndicDLP, a large-scale
foundational document layout dataset spanning 11 representative Indic languages alongside English and 12 common
document domains. Additionally, we curate UED-mini, a dataset derived from DocLayNet
and {\$}{\$}M^{\{}6{\}}Doc{\$}{\$}M6Doc, to enhance pretraining and provide a solid foundation for Indic layout
models. Our experiments demonstrate that fine-tuning existing English models on IndicDLP significantly boosts
performance, validating its effectiveness. Moreover, models trained on IndicDLP generalise well beyond Indic
layouts, making it a valuable resource for document digitisation. This work bridges gaps in scale, diversity, and
annotation granularity, driving inclusive and efficient document understanding.}
isbn = {978-3-032-04614-7}
Acknowledgments
Assamese
Yuvaraj - Superchecker
Rondeep Bordoloi - Reviewer
Ajit Kumar Sarma - Annotator
Anjali Steephan - Annotator
Madhutrishna Chetia - Annotator
Riya Chutia - Annotator
Ruh Ullah Khan - Annotator
Bengali
Praneeth Reddy - Superchecker
Rondeep Bordoloi Reviewer
Gargi Mukherjee Kolley - Annotator
Madhumita Pal - Annotator
Priyanjana Banerjee - Annotator
Soupat Biswas - Annotator
Sushmita Pal - Annotator
English
Hemavardhini R - Superchecker
Yuvaraj - Superchecker
Ragavan S - Reviewer
Ghiridharan M G - Annotator
Munish Mangla - Annotator
Rubeena - Annotator
Vidhya J G - Annotator
Gujarati
Praneeth Reddy - Superchecker
Kaniz Fatema - Reviewer
Bhargav Bhatt - Annotator
Kinjal Joshi - Annotator
Naman Mehta - Annotator
Parth B - Annotator
Parthiv Makwana - Annotator
Shreya Parmar - Annotator
Vama Soni - Annotator
Hindi
Hemavardhini R - Superchecker
Puru Koli - Reviewer
Adiba Khan - Annotator
Anima Chetry - Annotator
Arati Giri - Annotator
Ashish Kumar Jha - Annotator
Bhakti Rai - Annotator
Furtengi Sherpa - Annotator
Keshav Prasad Sapkota - Annotator
Nilesh lagade - Annotator
Rushaid Abbas - Annotator
Kannada
Hemavardhini R - Superchecker
Ragavan S - Reviewer
Ramya - Reviewer
Sreejanani Sanke - Reviewer
Charulatha S - Annotator
Nandini Vijay - Annotator
Rajeshwari Lakkannavar - Annotator
Suma Girish - Annotator
Vidya Kulkarni - Annotator
Virat Kumar Pandey - Annotator
Malayalam
Neha Bandekar - Superchecker
Ramya - Reviewer
Swetha - Reviewer
ABHINAV P M - Annotator
Amal I C - Annotator
Nadha rashada S V - Annotator
SANJAY.R - Annotator
Sreelekshmi S - Annotator
Marathi
Neha Bandekar - Superchecker
Nikita Digraskar - Reviewer
Manjunath Renake - Annotator
Nitin Paranjape - Annotator
Sachin Deepak Londhe - Annotator
Tejas Vishnupant Akhare - Annotator
Odia
Neha Bandekar - Superchecker
Harihara Barik - Reviewer
Lalatendu Bidyadhar Das - Annotator
Rajat Kumar patra - Annotator
Satyabrat Badajena - Annotator
Sradhanjali Pradhan - Annotator
Punjabi
Yuvaraj - Superchecker
Saranpal Singh - Reviewer
HarvinderSingh GurmeetSingh Ragi - Annotator
Inderpreet - Annotator
Jaydeep Singh Shahu - Annotator
Lovepreet Singh - Annotator
Niharika Khanna - Annotator
Sukhpreet Kaur - Annotator
Tamil
Hemavardhini R - Superchecker
Swetha - Reviewer
Bensha Joyson - Annotator
N. Gana Priyan - Annotator
N.Indupriya - Annotator
Telugu
Praneeth Reddy - Superchecker
Sreejanani Sanke - Reviewer
Deepika Senapathi - Annotator
Ediga Sivakumar Goud - Annotator
Naresh Nune - Annotator
Vakkapati Divyasri - Annotator
Vani Bhaskar - Annotator
We would like to acknowledge the support from Indian Institute of Technology, Madras, India and International Institute of Information Technology Hyderabad, India.