 Minesh Mathew
Minesh Mathew
Publications
Minesh Mathew, Ajoy Mondal and C V Jawahar - Towards Deployable OCR Models for Indic Languages , In International Conference on Pattern Recognition (ICPR), 2024. [ PDF ]
Soumya Jahagirdar, Minesh Mathew, Dimosthenis Karatzas, C. V. Jawahar - Watching the News: Towards VideoQA Models that can Read, Winter Conference on Applications of Computer Vision (WACV 2023) [ PDF ]
Sergi Garcia-Bordils, George Tom, Sangeeth Reddy, Minesh Mathew, Marçal Rusiñol, C.V. Jawahar, and Dimosthenis Karatzas - Read While You Drive - Multilingual Text Tracking on the Road, The 15thIAPR International Workshop on Document Analysis System (DAS 2022) . [ PDF ]
Mathew, Minesh and Karatzas, Dimosthenis and Jawahar C.V. - DocVQA: A Dataset for VQA on Document Images, Winter Conference on Applications of Computer Vision (WACV 2021). [PDF]
Sangeeth Reddy,Minesh Mathew, Lluis Gomez, Marçal Rusinol, Dimosthenis Karatzas and C. V. Jawahar - RoadText-1K: Text Detection & Recognition Dataset for Driving Videos, International Conference on Robotics and Automation (ICRA 2020). [PDF]
Deepayan Das, Jerin Philip, Minesh Mathew and C. V. Jawahar - A Cost Efficient Approach to Correct OCR Errors in Large Document Collections, The 15th International Conference on Document Analysis and Recognition (ICDAR), 2019, 20 - 25 September 2019, Australia.[PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Improving CNN-RNN Hybrid Networks for Handwriting Recognition, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Towards Spotting and Recognition of Handwritten Words in Indic Scripts, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Localizing and Recognizing Text in Lecture Videos, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta,Praveen Krishnan, Minesh Mathew and C. V. Jawahar - Offline Handwriting Recognition on Devanagari using a new Benchmark Dataset, Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, 24-27 April 2018, Vienna, Austria. [PDF]
Mohit Jain, Minesh Mathew and C. V. Jawahar - Unconstrained OCR for Urdu using Deep CNN-RNN Hybrid Networks 4th Asian Conference on Pattern Recognition (ACPR 2017), Nanjing, China, 2017. [PDF]
Minesh Mathew , Mohit Jain and C. V. Jawahar - Benchmarking Scene Text Recognition in Devanagari, Telugu and Malayalam 6th International Workshop on Multilingual OCR, Kyoto, Japan, 2017. [PDF]
V S Vinitha, Minesh Mathew and C. V. Jawahar - An Empirical Study of Effectiveness of Post-processing in Indic Scripts 6th International Workshop on Multilingual OCR, Kyoto, Japan, 2017. [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew, and C. V. Jawahar - Towards Accurate Handwritten Word Recognition for Hindi and Bangla National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), 2017 [PDF]
Mohit Jain, Minesh Mathew and C. V. Jawahar - Unconstrained Scene Text and Video Text Recognition for Arabic Script 1st International Workshop on Arabic Script Analysis and Recognition (ASAR 2017), Nancy, France, 2017. [PDF]
Minesh Mathew, Ajeet Kumar Singh and C V Jawahar - Multilingual OCR for Indic Scripts - Proceedings of 12th IAPR International Workshop on Document Analysis Systems (DAS'16), 11-14 April, 2016, Santorini, Greece. [PDF]
Projects
 Scene Text Recognition in Indian Scripts
Scene Text Recognition in Indian Scripts
People Involved : Minesh Mathew, Mohit Jain and CV Jawahar
This work addresses the problem of scene text recognition in India scripts. As a first step, we benchmark scene text recognition for three Indian scripts - Devanagari, Telugu and Malayalam, using a CRNN model.
 RoadText-1K: Text Detection & Recognition Dataset for Driving Videos
RoadText-1K: Text Detection & Recognition Dataset for Driving Videos
People Involved :Sangeeth Reddy, Minesh Mathew, Lluis Gomez, Marçal Rusinol, Dimosthenis Karatzas, and C. V. Jawahar
Perceiving text is crucial to understand semantics of outdoor scenes and hence is a critical requirement to build intelligent systems for driver assistance and self-driving. Most of the existing datasets for text detection and recognition comprise still images and are mostly compiled keeping text in mind.
 LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
People Involved : Kartik Dutta, Minesh Mathew, Praveen Krishnan and CV Jawahar
Lecture videos are rich with textual information and to be able to understand the text is quite useful for larger video understanding/analysis applications. Though text recognition from images have been an active research area in computer vision, text in lecture videos has mostly been overlooked. In this work, we investigate the efficacy of state-of-the art handwritten and scene text recognition methods on text in lecture videos
 Word level Handwritten datasets for Indic scripts
Word level Handwritten datasets for Indic scripts
People Involved : Kartik Dutta, Praveen Krishnan, Minesh Mathew and CV Jawahar
Handwriting recognition (HWR) in Indic scripts is a challenging problem due to the inherent subtleties in the scripts, cursive nature of the handwriting and similar shape of the characters. Lack of publicly available handwriting datasets in Indic scripts has affected the development of handwritten word recognizers. In order to help resolve this problem, we release 2 handwritten word datasets: IIIT-HW-Dev, a Devanagari dataset and IIIT-HW-Telugu, a Telugu dataset.
 Unconstrained OCR for Urdu using Deep CNN-RNN Hybrid Networks
Unconstrained OCR for Urdu using Deep CNN-RNN Hybrid Networks
People Involved : Mohit Jain, Minesh Mathew, C. V. Jawahar
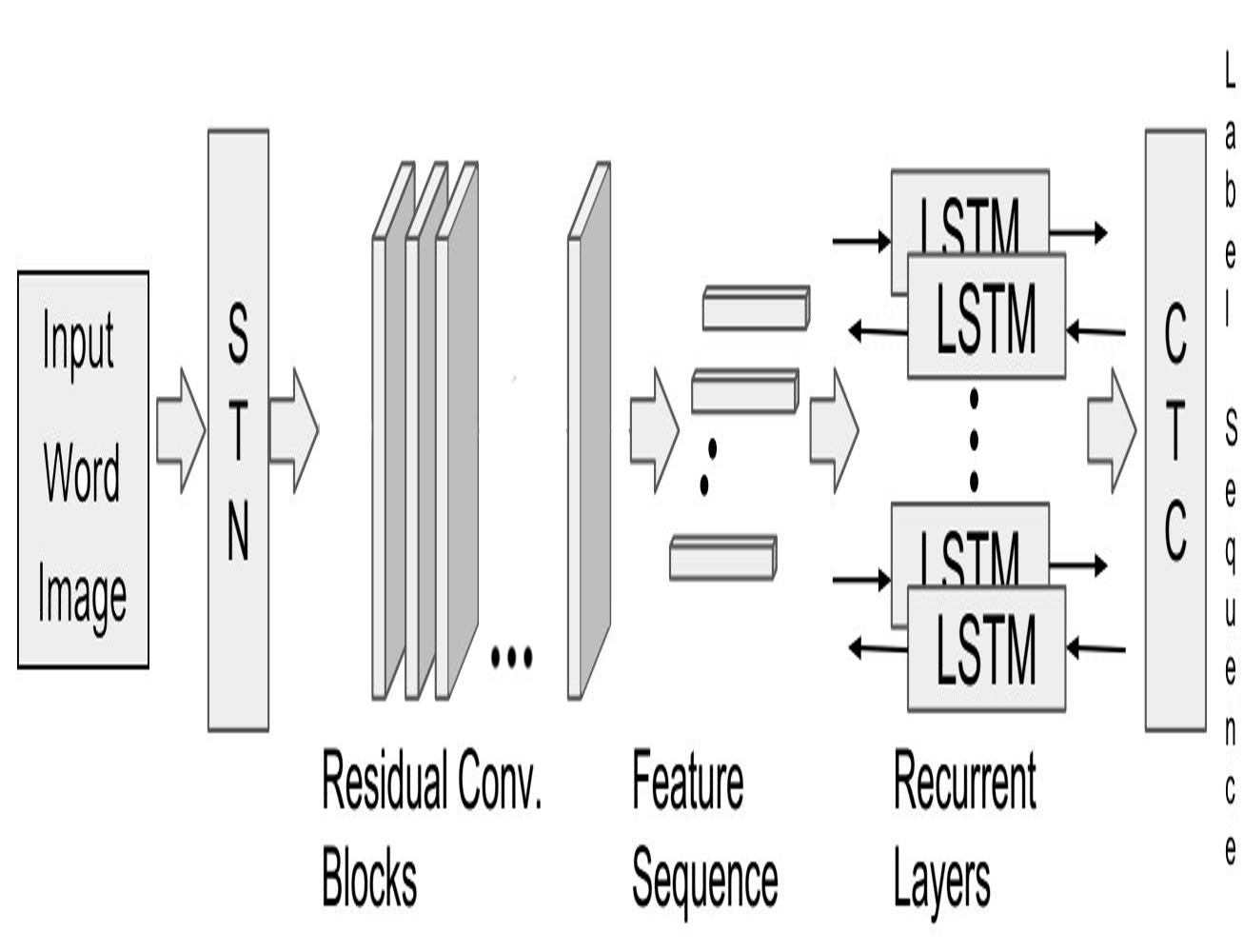
Building robust text recognition systems for languages with cursive scripts like Urdu has always been challenging. Intricacies of the script and the absence of ample annotated data further act as adversaries to this task. We demonstrate the effectiveness of an end-to-end trainable hybrid CNN-RNN architecture in recognizing Urdu text from printed documents, typically known as Urdu OCR. The solution proposed is not bounded by any language specific lexicon with the model following a segmentation-free, sequence-tosequence transcription approach. The network transcribes a sequence of convolutional features from an input image to a sequence of target labels.
 Unconstrained Scene Text and Video Text Recognition for Arabic Script
Unconstrained Scene Text and Video Text Recognition for Arabic Script
People Involved : Mohit Jain, Minesh Mathew, C. V. Jawahar
Building robust recognizers for Arabic has always been challenging. We demonstrate the effectiveness of an end-to-end trainable CNN-RNN hybrid architecture in recognizing Arabic text in videos and natural scenes. We outperform previous state-of-the-art on two publicly available video text datasets - ALIF and AcTiV. For the scene text recognition task, we introduce a new Arabic scene text dataset and establish baseline results. For scripts like Arabic, a major challenge in developing robust recognizers is the lack of large quantity of annotated data. We overcome this by synthesizing millions of Arabic text images from a large vocabulary of Arabic words and phrases.