Recognition of Indian Language Documents
Introduction
The present growth of digitization of documents demands an immediate solution to enable the archived valuable materials searchable and usable by users in order to achieve its objective. In response, active research has been going on in similar direction to make access to digital documents imminent through indexing and retrieval of relevant documents.
A direct solution to this problem is the use of character recognition systems to convert document images into text followed by the use of existing text search engines to make them available for the public at large via the Internet. Significant advancement is made in the recognition of documents written in Latin-based scripts. There are many excellent attempts in building robust document analysis systems in industry, academia and research institutions. Intelligent recognition systems are commercially available for use for some scripts. On the contrary, there is only limited research effort made for the recognition of African, Indian and other oriental languages. In addition diversity and complexity of documents archived in digital libraries complicate the problem of document analysis and understanding to a great extent. Machine learning offers one of the most cost effective and practical approaches to the design of pattern classifiers for such documents. Mechanisms such as relevance feedback and feature selection are used to facilitate adaptation to new situations, and to improve its performance accordingly. Deviating from the conventional OCR design, we explore the prospect of designing character recognition systems for large collection of document images.
Problems with existing OCRs
Digitized documents are extremely poor in quality, varying in scripts, fonts, sizes and styles. Besides, document images in digital libraries are from diverse languages and hence vary in scripts. Accessing from these complex collection of document images is a challenging task, specially when there is no textual representation available. Though there are many excellent research works in developing robust OCR systems, most of these research in the area of character recognition has been centered around developing fully automatic systems with high performance classifiers. The recognizers were trained offline and used online without any feedback. However the diversity of document collections (language-wise, quality-wise, time-wise, etc.) reduce the performance of the system greatly. Hence, building an omnifont OCR that can convert all these documents into text does not look imminent. The system fails mostly to scale to the expected level of performance when a new font and poor quality documents are presented. Therefore most of the documents in digital libraries are not accessible by their content.
Challenges in OCR for Indic Scripts
High accuracy OCR systems are reported for English with excellent performance in presence of printing variations and document degradation. For Indian and many other oriental languages,OCR systems are not yet able to successfully recognise printed document images of varying scripts, quality, size, style and font. compared to European languages, Indian languages pose many additional challenges. Some of them are (i) Large number of vowels, consonants, and conjuncts, (ii) Most scripts spread over several zones, (iii) inflectional in nature and having complex character grapheme, (iv) lack of statistical analysis of most popular fonts and/or databases, (v) lack of standard test databases (ground truth data) of the Indian languages, Also issues like, (i) lack of standard representation for the fonts and encoding, (ii) lack of support from operating system, browsers and keyboard, and (iii) lack of language processing routines, add to the complexity of the design and implementation of a document image retrieval system.
Character Recognition systems
We have an OCR system that is setup for the recognition of Indian and Amharic documents. It has many functionalities including preprocessing, character segmentation, feature extraction, classification and post-processing modules.
Classifier design and feature selection for large class systems :-
The system accepts either already scanned documents or scans document pages from a flat-bed scanner. Scanned pages are preprocessed (binarized, skew corrected and noise removed) and segmented into character components. Then features are extracted for classification using dimensionality reduction scheme like Principal component analysis (PCA). PCA-based features enable us to manage the large number characters available in the script. These features are used for training the DDAG-based SVM classifier for classification. Finally characters are recognized and a post-processor is used to correct miss-classified once. Results of the OCR are converted texts that can be employed for retrieval tasks.
The performance of the OCR needs to be improved so that it can perform well on real-life documents such as books, magazines, newspapers, etc. To this end, we are working towards an intelligent OCR system that learns from its experience.
 Annotated Corpora and Test Suite
Annotated Corpora and Test Suite
Large annotated corpora is critical to the development of robust optical character recognizers (OCRs). we propose an efficient hierarchical approach for annotation of large collection of printed document images. The method is model-driven and is designed to annotate 50M characters from 40,000 documents scanned at three different resolutions. We employ an XML representation for storage of the annotation information. APIs are provided for access at content level for easy use in training and evaluation of OCRs and other document understanding tasks.
Document image annotation is carried out in a hierarchy of levels.
Block Level Annotation: In block level annotation, the document image is segmented into blocks of text paragraphs, tables, pictures and graphs.
Line level annotation is done by labeling the lines from paragraph of the document image with their corresponding extracted text lines. Line images are labeled by parallel alignment with the text lines.
Akshara annotation is the process of mapping a sequence of connected components from the word image to the corresponding text akshara. Image of akshara text is rendered for matching with components of the word image.
Machine Learning in OCR Systems
Adaptable OCR System (DAS) :-
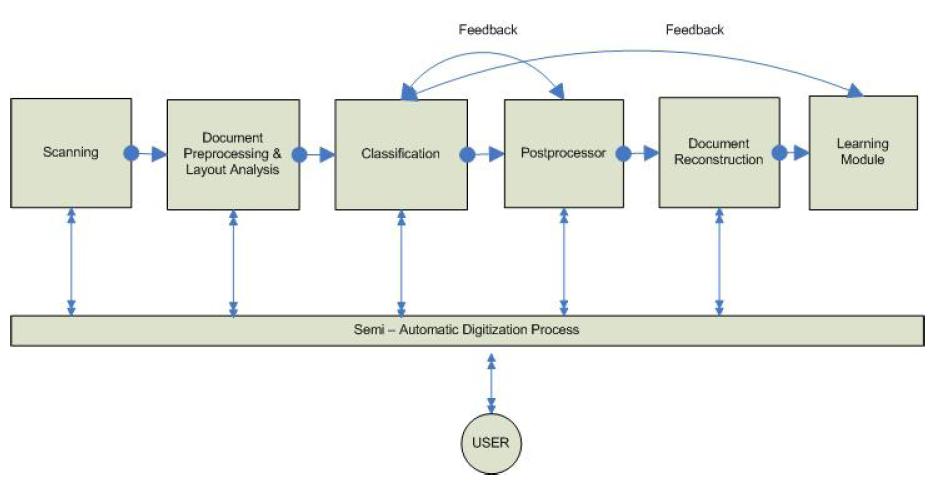
We presents a novel approach for designing a semi-automatic adaptive OCR for large document image collections in digital libraries. We describe an interactive system for continuous improvement of the results of the OCR. In this paper a semi-automatic and adaptive system is implemented. Applicability of our design for the recognition of Indian Languages is demonstrated. Recognition errors are used to train the OCR again so that it adapts and learns for improving its accuracy. Limited human intervention is allowed for evaluating the output of the system and take corrective actions during the recognition process.
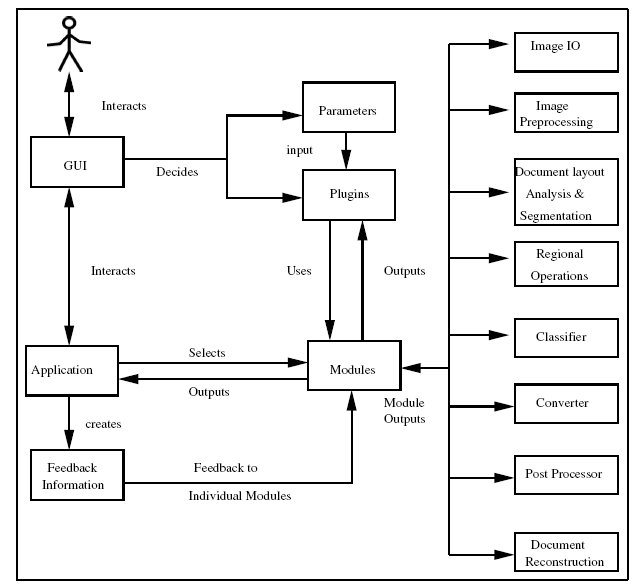
We design the general architecture of an interactivemultilingual OCR (IMOCR) system that is open for learning and adaptation. An overviewof the architecture of the system is shown in Figure. The IMOCR design is based on a multi-core approach. At the heart of the same is an application tier, which acts as the interface between the Graphical User Interface (GUI) and the OCR modules. This application layer identifies the user-made choices, initialises data and document structures and invokes relevant modules with suitable parameters. The GUI layer provides the user with the tools to configure the data-flow, select the plug-ins and supply initialization parameters. The system provides appropriate performance metrics in the form of graphs and tables for better visualization of the results of each step and module during the recognition process.
The last layer is the module/algorithm layer where the actual OCR operations are done. This layer is segmented based on clearly identified functionality. Each module implements a standard interface to be invoked via the application. Each module internally can decide on multiple algorithm implementations of the same functionality that may be interchanged at run-time. This helps in selection and use of an appropriate algorithm or a set of parameters for a book, collection or script. This layer is designed on the principle of plug-ins. The system allows transparent runtime addition and selection of modules (as shared objects/ dynamic libraries) thereby enabling the decoupling of the application and the plug-ins. Feature addition and deployment is as simple as copying the plug-in to the appropriate directory. The other advantages of this approach are lower size of application binary, lower runtime memory footprint and effective memory management (through dynamic loading and unloading, caching etc.).
Book OCR :-
 To alleviate such problems there is a need to build new generation document analysis systems; systems that are intelligent enough to learn and adjust themselves to the new documents that vary in quality, fonts, styles and sizes. The development of such systems should aim at learning not through explicit training, but through feedback at normal operation. Such systems are expected to register an acceptable accuracy rate so as to facilitate effective access to relevant documents from these large collection of document images.
To alleviate such problems there is a need to build new generation document analysis systems; systems that are intelligent enough to learn and adjust themselves to the new documents that vary in quality, fonts, styles and sizes. The development of such systems should aim at learning not through explicit training, but through feedback at normal operation. Such systems are expected to register an acceptable accuracy rate so as to facilitate effective access to relevant documents from these large collection of document images.
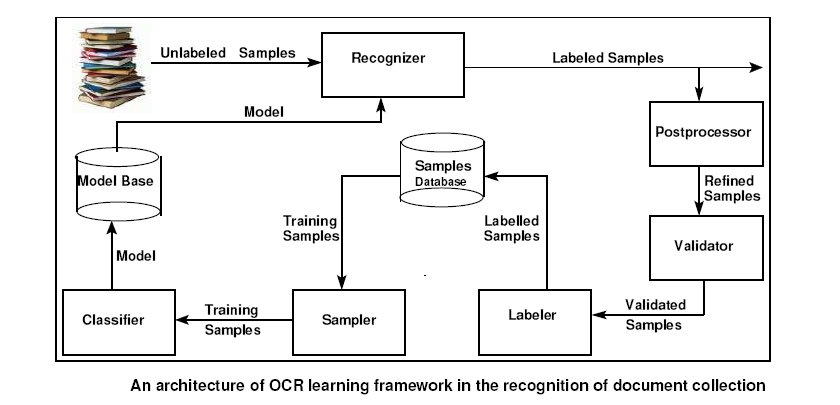
To this end, we propose a new approach towards the recognition of large collection of text images using an interactive (adaptive) learning system. In this project we show for the first time an OCR system that learns from its mistakes and improves its performance continuously across a large collection of document images through feedback mechanism. The strategy of designing this system is with the aim of enabling the OCR learn on-the-fly using knowledge derived from an input sequence of word images. The resulting system is expected to learn the characteristics of symbol shape, context, and noise that are present in a collection of images in the corpus, and thus should be able to generalize and achieve higher accuracy across diverse documents.
This system enables us to build a generic OCR that has a minimal core, and leaves most of the sophisticated tuning to on-line learning. This can be a recurrent process involving frequent feedback and backtracking. Such a strategy is valuable to handle, in a situation like ours where there is a huge collection of degraded documents in different languages and there are human operators working on OCRing the scanned books. We integrate a number of modules to realize the learning framework. A post-processor based feedback mechanism is enabled to identify and pass recognition errors as new training datasets. The quality of the new training samples are controlled using validation techniques in the image-space. We propose incremental learning approach to enhance the efficiency of training the classifier on-line during normal operation. Sampling is done to make sure that each time new datasets are fed for training the classifier and appropriate features are selected at each node of the DDAG for pair-wise classification.
To suit Learn OCR there is a need to design intelligent postprocessor. At present we are investigating language modeling techniques in image space. Sample data is being generated by Learn OCR through feedback. There is a need to systematically use these data for performance improvement. We are also working towards the application of learning framework for labeling the unlabeled data.
Algorithms for Document Understanding
Segmentation :
The problem of document segmentation is that of dividing a document image (I) into a hierarchy of meaningful regions like paragraphs, text lines, words, image regions, etc. These regions are associated with a homogeneity property Φ( . ) and the segmentation algorithms are parameterized by θ . Conventionally, segmentation has been viewed as a deterministic partitioning scheme characterized by the parameter θ. The challenge has been in finding an optimal set of values for θ, to segment the input Image I into appropriate regions. In our formulation, the parameter vector θ is learned based on the feedback calculated in the form a homogeneity measure Φ( . ) (a model based metric to represent the distance from ideal segmentation). The feedback is propagated upwards in the hierarchy to improve the performance of each level above, estimating the new values of the parameters to improve the overall performance of the system. Hence the values of θ are learned based on the feedback from present and lower levels of the system. In order to improve the performance of an algorithm over time using multiple examples or by processing an image multiple times, the algorithm is given appropriate feedback in the form of homogeneity measure of the segmented regions. Feedback mechanisms for learning the parameters could be employed at various levels.
Perspective Correction for Camera based Document Analysis :
We demonestrate intelligent use of commonly available clues for rectification of docment images for camera-based analysis and recognition. Camear-based imaging has many challenges such as projection distortion, uneven lighting and lens distortion.
There are different rectification techniques. One is the deterimination of document image boundaries using aspect ratio of the documents, and parallel and perpendicular lines. If the original aspect ratio of the rectangle is known, the vertices of the quadrilaterals could be used to obtain the homography between an arbitrary view to the frontal view. The other is the use of page layout and structural information. We can extract information like text and graphics block present in the image, repetitive or apriori known structure of cells in tables. Finally, content specific rectification using the properties of text (or the content of the image itself). For example, sirorekha can be used for text written in Devanagari and Bangla in estimating the vanishing point
Related Publications
K.S.Sesh Kumar, Anoop M. Namboodiri and C. V. Jawahar - Learning Segmentation of Documents with Complex Scripts, 5th Indian Conference on Computer Vision, Graphics and Image Processing(ICVGIP), Madurai, India LNCS 4338 pp.749-760, 2006. [PDF]
Sachin Rawat, K. S. Sesh Kumar, Million Meshesha, Indineel Deb Sikdar, A. Balasubramanian and C. V. Jawahar - A Semi-Automatic Adaptive OCR for Digital Libraries, Proceedings of Seventh IAPR Workshop on Document Analysis Systems, 2006 (LNCS 3872), pp 13-24. [PDF]
M. N. S. S. K. Pavan Kumar and C. V. Jawahar, Design of Hierarchical Classifier with Hybrid Architectures, Proceedings of First International Conference on Pattern Recognition and Machine Intelligence(PReMI 2005) Kolkata, India. December 2005, pp 276-279. [PDF]
Million Meshesha and C. V. Jawahar - Recognition of Printed Amharic Documents, Proceedings of Eighth International Conference on Document Analysis and Recognition(ICDAR), Seoul, Korea 2005, Vol 1, pp 784-788. [PDF]
M. N. S. S. K. Pavan Kumar and C. V. Jawahar, Configurable Hybrid Architectures for Character Recognition Applications, Proceedings of Eighth International Conference on Document Analysis and Recognition(ICDAR), Seoul, Korea 2005, Vol 1, pp 1199-1203. [PDF]
C. V. Jawahar, MNSSK Pavan Kumar and S. S. Ravikiran - A Bilingual OCR system for Hindi-Telugu Documents and its Applications, Proceedings of the International Conference on Document Analysis and Recognition(ICDAR) Aug. 2003, Edinburgh, Scotland, pp. 408--413. [PDF]
Associated People
- Million Meshesha
- Balasubramanian Anand
- Sesh Kumar.
- L. Jagannathan
- Neeba N V
- Venkat Rasagna
- Dr. C. V. Jawahar