Biometric Authentication
Introduction
Biometrics deals with recognizing people based on their physiological or behavioral characteristics. Our work primarily concentrates on three different aspects in biometrics:
- Enhancing Weak Biometrics for Authentication: Weak biometrics (hand-geometry, face, voice, keystrokes) are the traits that possess low discriminating content and they change over time for each individual. However, there are several traits of weak biometrics such as social acceptability, ease of sensing, and lack of privacy concerns that make weak biometrics ideally suited for civilian applications. Methods that we developed can effectively handle the problems of low discriminative power and low feature stability of weak biometrics, as well as time-varying population in civilian applications.
- Writer Identification from Handwritten Documents: Handwriting is a behavioural biometric that contains distinctive traits aquired by a person over time. Traditional approaches to writer identification tries to compute feature vectors that capture traits of handwriting that are known to experts as discriminative. In contrast we concentrate on automatic extraction of features that are suitable to specific applications such as writer identification in civilian domain and in problems such as forgery and repudiation in forensics.
- Use of Camera as a Biometric Sensor: Camera has been used for capturing face images for authentication in the past. However, with biometrics traits such as fingerprints and iris, a specialized sensor is often preferred due to the high quality of data that they provide. Recent advances in image sensors have made digital cameras both inexpensive and technically capable for achieving high quality images. However, many problems such as variations in pose, illumination and scale restrict the use of cameras as sensors for many biometric traits. We are working on the use of models of imaging process to overcome these problems, to capture high quality data for authentication.
Enhancing Weak Biometric based Authentication
Weak biometrics (hand-geometry, face, voice, keystrokes) are the traits which possess low discriminating content and they change over time for each individual. Thus they show low accuracy of the system as compared to the strong biometrics (eg. fingerprints, iris, retina, etc.) However, due to exponentially decreasing costs of the hardware and computations, biometrics has found immense use in civilian applications (Time and Attendance Monitoring, Physical Access to Building, Human-Computer Interface, etc.) other than forensics (e.g. criminal and terrorist identification). Various factors need to be considered while selecting a biometric trait for civilian application; most important of which are related to user psychology and acceptability, affordability, etc. Due to these reasons, weak biometric traits are often better suited for civilian applications than the strong biometric traits. In this project, we address issues such as low and unstable discriminating information, which are present in weak biometrics and variations in user population in civilian applications.
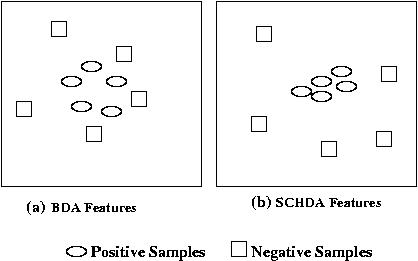 Due to the low discriminating content of the weak biometric traits, they show poor performance during verification. We have developed a novel feature selection technique called Single Class Hierarchical Discriminant Analysis (SCHDA), specifically for authentication purpose in biometric systems. SCHDA builds an optimal user-specific discriminant space for each individual where the samples of the claimed identity are well-separated from the samples of all the other users.
Due to the low discriminating content of the weak biometric traits, they show poor performance during verification. We have developed a novel feature selection technique called Single Class Hierarchical Discriminant Analysis (SCHDA), specifically for authentication purpose in biometric systems. SCHDA builds an optimal user-specific discriminant space for each individual where the samples of the claimed identity are well-separated from the samples of all the other users.
The second problem which leads to low accuracy of authentication is the poor stability or permanence of weak biometric traits due to various reasons (eg. ageing, the person gaining or losing weight, etc.) Civilian applications usually operate in cooperative or monitored mode wherein the users can give feedback to the system on occurrence of any errors. An intelligent adaptive framework is used, which uses feedback to incrementally update the parameters of the feature selection and verification framework for each individual.
The third factor that has been explored to improve the performance of an authentication system for civilian applications is the pattern of participation of each enrolled user. As the new users are enrolled into the system, a degradation is observed in performance due to increasing number of users. An interesting observation is that although the number of users enrolled into the system is very high, the number of users who regularly participate in the authentication process is comparatively low. We model the variation in participating population using Markov models. The prior probability of participation of each individual is computed and incorporated into the feature selection framework, providing more relevance to the parameters of regularly participating users. Both the structured and unstructured modes of variation of participation are explored.
Text Independent Writer Identification from Online Handwriting
Handwriting Individuality is a quantitative measure of writer specific information that can be used to identify authorship of the documents and study of comparison of writing habits, evaluation of the significance of their similarities and differences. It is an discrimitive process like fingerprint identification, firearms identification and DNA analysis. Individuality in handwriting lies in the habits that are developed and become consistant to some degree in the process of writing.
Discriminating elements of handwriting lies in various factors such as i) Arrangement, Connections, Constructions, Design, Dimensions, Slant or Slope, Spacings, CLass and choice of allographs, 2) Language styles such as Abbreviation, Commencements and terminations, diacritics and punctuation, line continuity, line quality or fluency, 3) Physical traits such as pen control, pen hold, pen position, pen pressure and writing movement, 4) Consistancy or natural variations and persistance, and 4) Lateral expansion and word proportions.
The framework that we utilize tries to capture the consistent information at various levels and automatically extract discriminative features from them.
Features of our Approach:
- Text-independent algorithm: Writer can be identified from any text given in underlined script. Comparison of features are not done for the similar charcters.
- Script dependent framework: Applicablity is verified on different scripts like Devanagiri, Arabic,Roman, Chinese and Hebrew.
- Use of Online Information: Online data is used for verification purpose. Offline information is also applicable with similar framework with appropriate change in feature extraction.
- Authentication with small amount of data: Around 12 words in Devanagiri we get accuracy of 87%.
Underlying process of identification:
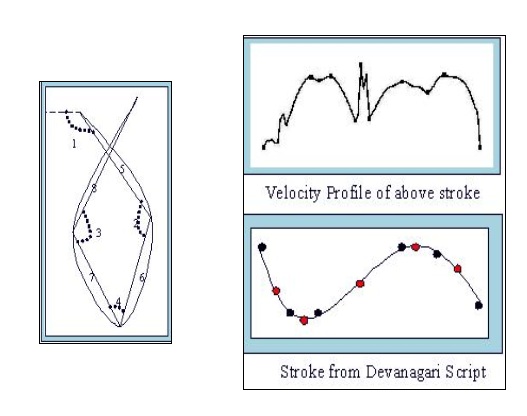
- Primitive Definition:
Primitives are the discrimitive features of handwriting documents. First step is to identify primitive. Primitives can be individuality features like size, shape, distribution of curves in handwritten document. We choose subcharcter level curves as basic primitives
- Extraction and Representation of primitive:
Extraction of primitive is done using velocity profile of the stroke shown in the figure. Minimum velocity points are critical points of primitive. Primitives are extracted using size and shape features as shown in diagram.
- Identification of Consistant Primitives:
Repeating curves are consitent primitives. To extract consistent curves, unsupervised clustering algorithm is used to cluster them into different groups.
- Classification:
Variation in distribution, size and shape of curves in each cluster is used to discriminate writer from other writers.
Related Publications
- Vandana Roy, C. V. Jawahar: Feature Selection for Hand-Geometry based Person Authentication, in Proceedings of International Conference on Advanced Computing and Communication, Coimbatore, India, Dec. 2005.
- Vandana Roy, C. V. Jawahar: Hand-Geometry Based Person Authentication Using Incremental Biased Discriminant Analysis, in Proceedings of National Conference on Communications, New Delhi, Jan. 2006.
- Anoop Namboodiri, Sachin Gupta: Text Independent Writer Identification for online Handwriting, in Proceedings of the International Workshop on Frontiers in Handwriting Recognition (IWFHR'06), La Baule, France, October 2006.
- Vandana Roy, C. V. Jawahar: Modeling Time-Varying Population for Biometrics, To appear in Proceedings of International Conference on Computing: Theory and Applications, Kolkata, India, March 2007.
Associated People
- Vandana Roy
- Sachin Gupta
- C. V. Jawahar
- Anoop Namboodiri