IIIT-INDIC-HW-WORDS: A Dataset for Indic Handwritten Text Recognition
Santhoshini Gongidi and C. V. Jawahar
[ Teaser Video ] [Paper] [Code]
Overview:
Overview Handwritten text recognition for Indian languages is not yet a well-studied problem. This is primarily due to the unavailability of large annotated datasets in the associated scripts. We introduce a large-scale handwritten dataset for Indic scripts, referred to as the IIIT-INDIC-HW-WORDS dataset. The dataset consists of 872K handwritten instances written by 135 writers in 8 Indic scripts. With the newly introduced dataset and our earlier datasets IIIT-HW-DEV and IIIT-HW-TELUGU in Devanagari and Telugu respectively, the IIIT-INDIC-HW-WORDS dataset contains annotated hand-written word instances in all 10 prominent Indic scripts.
We further establish a high baseline for text recognition in eight Indic scripts. Our recognition scheme follows the contemporary design principles from other recognition literature, and yields competitive results on English. We further (i) study the reasons for changes in HTR performance across scripts (ii) explore the utility of pre-training for Indic HTRs. We hope our efforts will catalyze research and fuel applications related to handwritten document understanding in Indic scripts.
A glimpse into the dataset
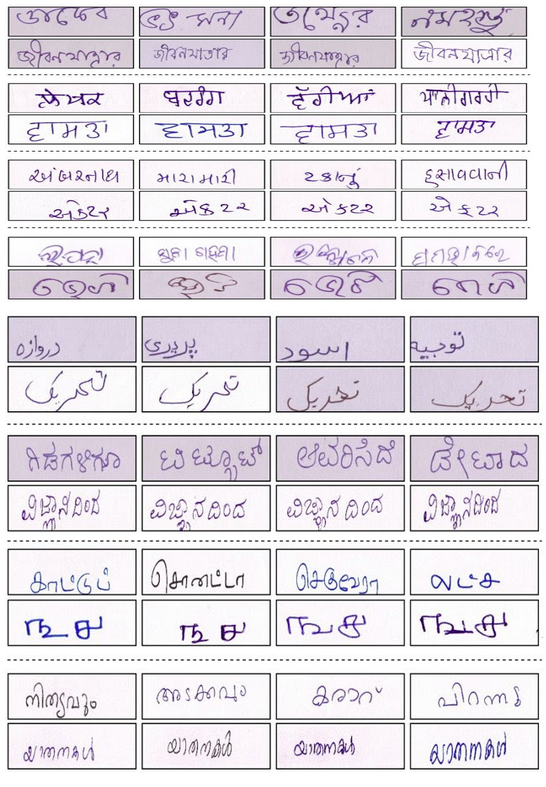
Dataset
The zip file for each language contains image folders, label file and a vocabulary file. Please follow the instructions in the README file for more instructions.
| Language | Download link |
| Bengali | Link |
| Gujarati | Link |
| Gurumukhi | Link |
| Kannada | Link |
| Odiya | Link |
| Malayalam | Link |
| Tamil | Link |
| Urdu | Link |
For Devanagari and Telugu datasets, please follow the Link
Related Publications
Santhoshini Gongidi, C V Jawahar, INDIC-HW-WORDS: A Dataset for IndicHandwritten Text Recognition International Conference on Document Analysis and Recognition (ICDAR) 2021, [ PDF ]
Contact
For any queries about the dataset, please contact the authors below:
Santhoshini Gongidi: