IndicSTR12: A Dataset for Indic Scene Text Recognition
, ,
[Paper] [Code] [Synthetic Dataset] [Real Dataset] [Poster]
ICDAR , 2023
Abstract

We present a comprehensive dataset comprising 12 major Indian languages, including Assamese, Bengali, Odia, Marathi, Hindi, Kannada, Urdu, Telugu, Malayalam, Tamil, Gujarati, and Punjabi. The dataset consists of real word images, with a minimum of 1000 images per language, accompanied by their corresponding labels in Unicode. This dataset can serve various purposes such as script identification, scene text detection, and recognition.
We employed a web crawling approach to assemble this dataset, specifically gathering images from Google Images through targeted keyword-based searches. Our methodology ensured coverage of diverse everyday scenarios where Indic language text is commonly encountered. Examples include wall paintings, railway stations, signboards, nameplates of shops, temples, mosques, and gurudwaras, advertisements, banners, political protests, and house plates. Since the images were sourced from a search engine, they originate from various contexts, providing various conditions under which the images were captured.
The curated dataset encompasses images with different characteristics, such as blurriness, non-iconic or iconic text, low resolution, occlusions, curved text, and perspective projections resulting from non-frontal viewpoints. This diversity in image attributes adds to the dataset's realism and utility for various research and application domains
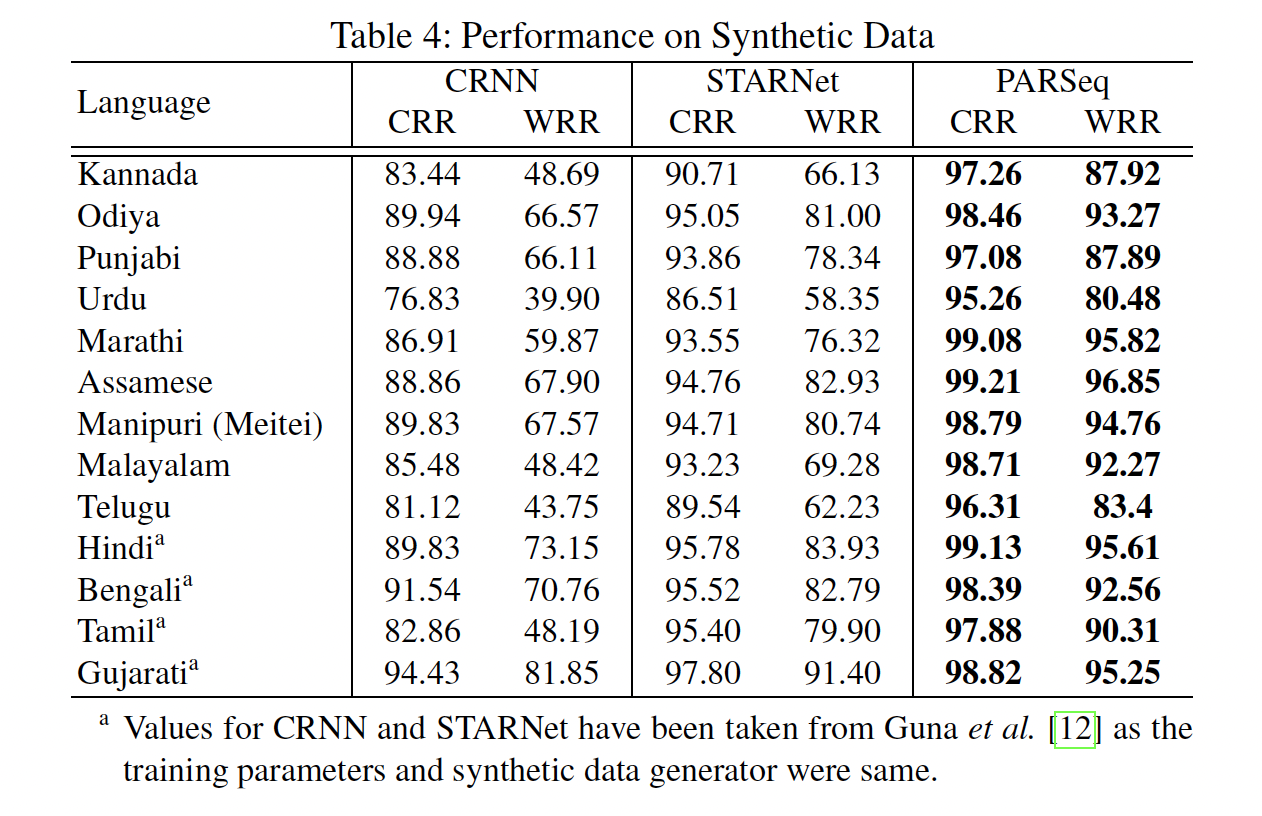
Additionally, we introduce a synthetic dataset specifically designed for 13 Indian languages (including Manipuri - Meitei Script). This dataset aims to advance the field of Scene Text Recognition (STR) by enabling research and development in the area of multi-lingual STR. In essence, this synthetic dataset serves a similar purpose as the well-known SynthText and MJSynth datasets, providing valuable resources for training and evaluating text recognition models.
Benchmarking Approach
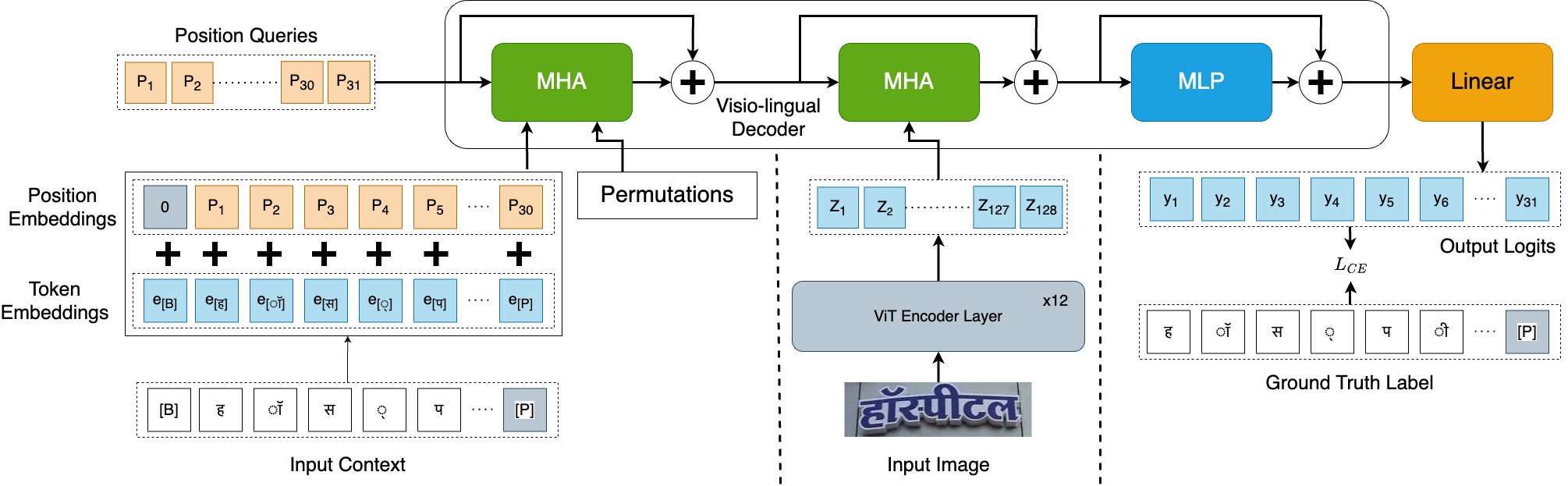
For the IndicSTR12 dataset, three models were selected for benchmarking the performance of Scene Text Recognition (STR) on 12 Indian languages. These models are as follows:
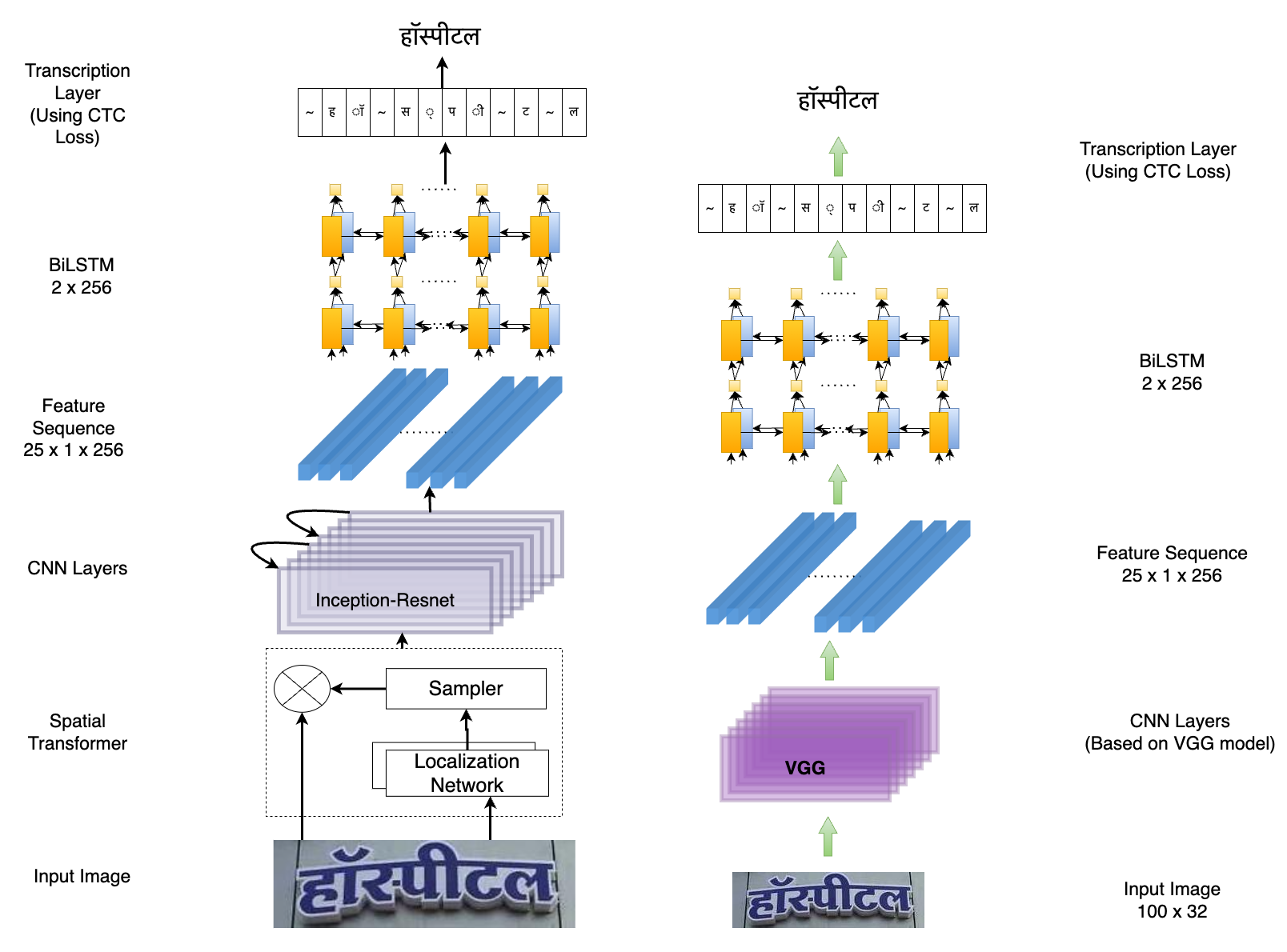
PARSeq: This model is the current state-of-the-art for Latin STR and it achieves high accuracy.
CRNN: Despite having lower accuracy compared to many current models, CRNN is widely adopted by the STR community for practical purposes due to its lightweight nature and fast processing speed.
STARNet: This model excels at extracting robust features from word-images and includes an initial distortion correction step on top of CRNN architecture. It has been chosen for benchmarking to maintain consistency with previous research on Indic STR.
These three models were specifically chosen to evaluate and compare their performance on the IndicSTR12 dataset, enabling researchers to assess the effectiveness of various STR approaches on the Indian languages included in the dataset.
Result
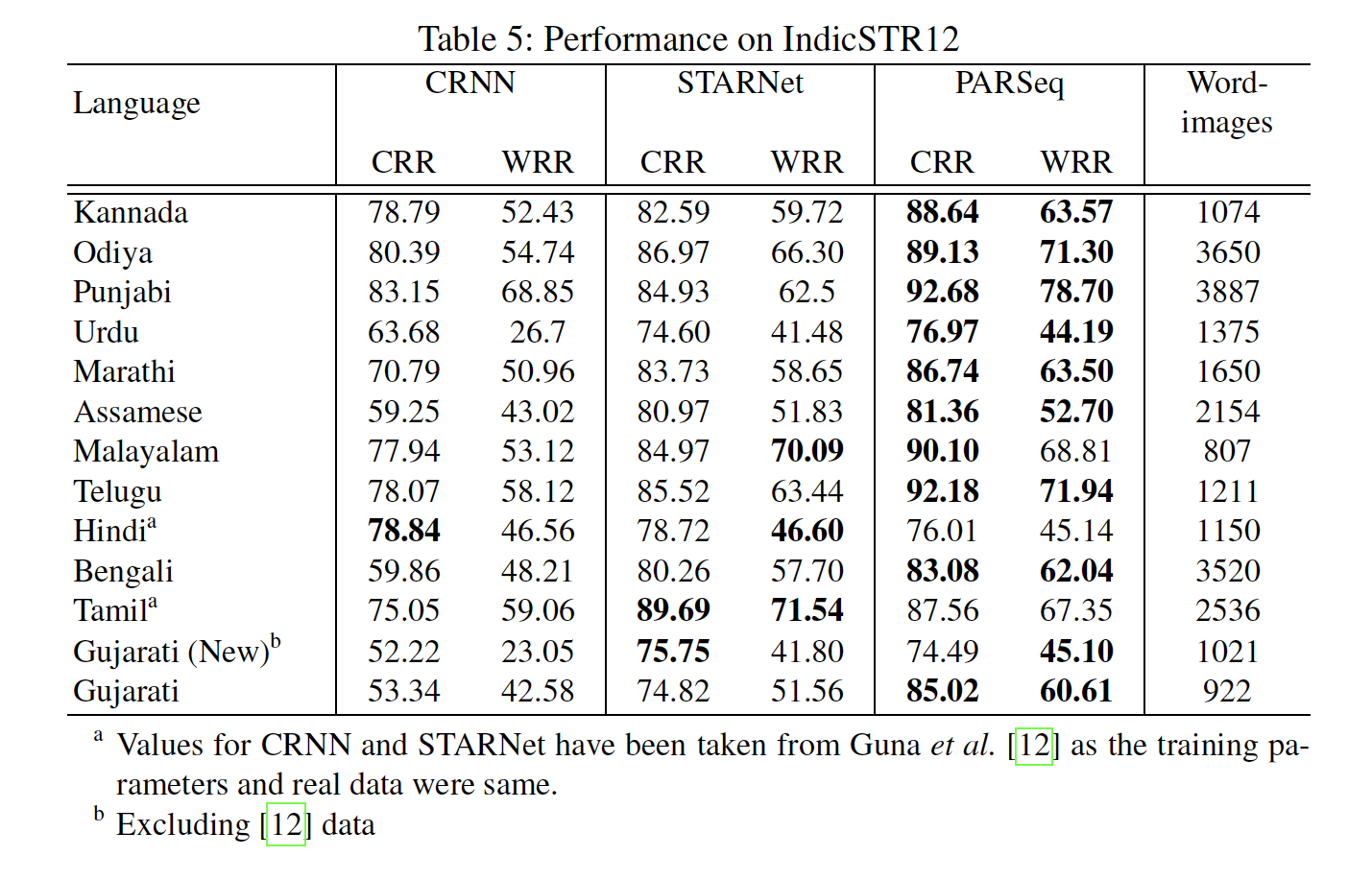
Dataset


Citation
@inproceedings{lunia2023indicstr12,
title={IndicSTR12: A Dataset for Indic Scene Text Recognition},
author={Lunia, Harsh and Mondal, Ajoy and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={233--250},
year={2023},
organization={Springer}
}
Acknowledgements
This work is supported by MeitY, Government of India, through the NLTM-Bhashini project.