Watching the News: Towards VideoQA Models that can Read
, , , ,
[Paper] [Video] [Code] [Dataset]
Abstract
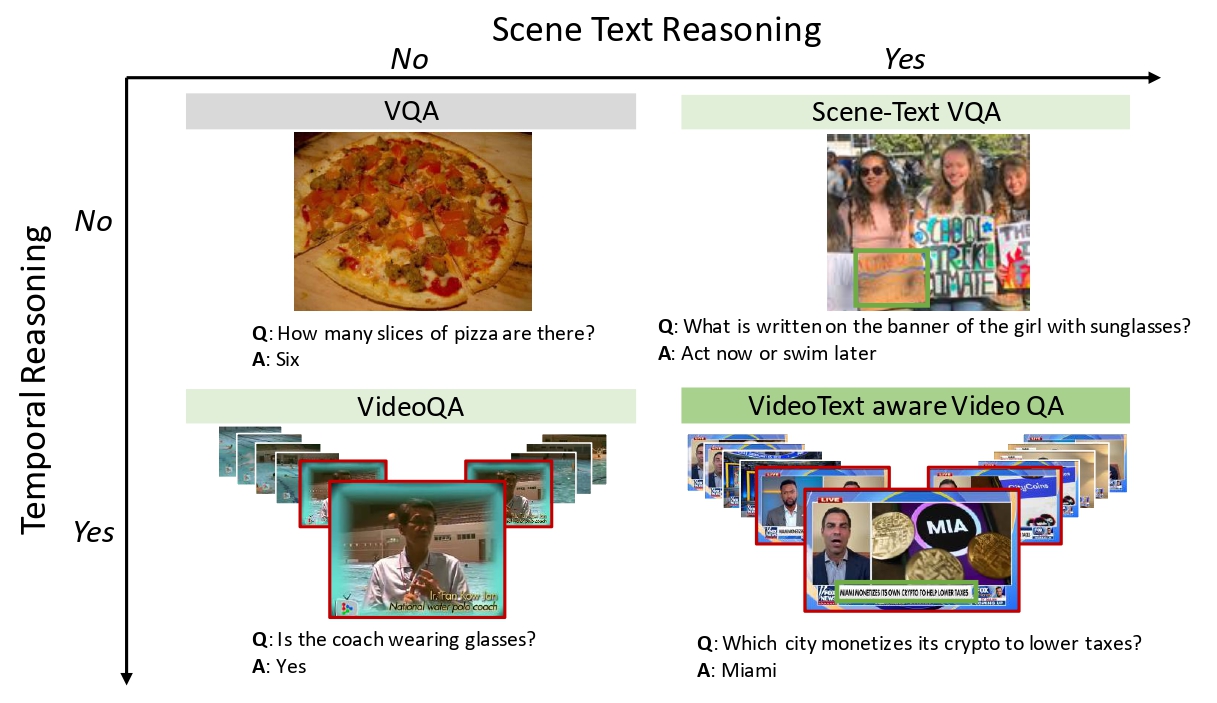
Video Question Answering methods focus on commonsense reasoning and visual cognition of objects or persons and their interactions over time. Current VideoQA approaches ignore the textual information present in the video. Instead, we argue that textual information is complementary to the action and provides essential contextualisationcues to the reasoning process. To this end, we propose a novel VideoQA task that requires reading and understanding the text in the video. To explore this direction, we focus on news videos and require QA systems to comprehend and answer questions about the topics presented by combining visual and textual cues in the video. We introduce the “NewsVideoQA” dataset that comprises more than 8, 600 QA pairs on 3, 000+ news videos obtained from diverse news channels from around the world. We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.