 Praveen Krishnan
Praveen Krishnan
Publications
Conference Publication
Siddhant Bansal, Praveen Krishnan and C.V. Jawahar - Improving Word Recognition using Multiple Hypotheses and Deep Embeddings ,The 25th International Conference of Pattern Recognition (ICPR) (ICPR 2021), Milano [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Improving CNN-RNN Hybrid Networks for Handwriting Recognition, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Towards Spotting and Recognition of Handwritten Words in Indic Scripts, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Localizing and Recognizing Text in Lecture Videos, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Vijay Rowtula, Praveen Krishnan, C.V. Jawahar - POS Tagging and Named Entity Recognition on Handwritten Documents, ICON, 2018[PDF]
Praveen Krishnan, Kartik Dutta and C. V. Jawahar - Word Spotting and Recognition using Deep Embedding, Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, 24-27 April 2018, Vienna, Austria. [PDF]
Kartik Dutta,Praveen Krishnan, Minesh Mathew and C. V. Jawahar - Offline Handwriting Recognition on Devanagari using a new Benchmark Dataset, Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, 24-27 April 2018, Vienna, Austria. [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew, and C. V. Jawahar - Towards Accurate Handwritten Word Recognition for Hindi and Bangla National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), 2017 [PDF]
Praveen Krishnan and C.V Jawahar - Matching Handwritten Document Images, The 14th European Conference on Computer Vision (ECCV) – Amsterdam, The Netherlands, 2016. [PDF]
Praveen Krishnan, Kartik Dutta and C.V Jawahar - Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text, 15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China (ICFHR), 2016. [PDF]
Anshuman Majumdar, Praveen Krishnan and C.V. Jawahar - Visual Aesthetic Analysis for Handwritten Document Images,15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China (ICFHR), 2016. [PDF]
Praveen Krishnan, Naveen Sankaran, Ajeet Kumar Singh and C. V. Jawahar - Towards a Robust OCR System for Indic Scripts Proceedings of the 11th IAPR International Workshop on Document Analysis Systems, 7-10 April 2014, Tours-Loire Valley, France. [PDF]
Praveen Krishnan and C V Jawahar - Bringing Semantics in Word Image Retrieval Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), 25-28 Aug. 2013, Washington DC, USA. [PDF]
Praveen Krishnan, Ravi Sekhar, C V Jawahar - Content Level Access to Digital Library of India Pages Proceedings of the 8th Indian Conference on Vision, Graphics and Image Processing (ICVGIP), 16-19 Dec. 2012, Bombay, India. [PDF]
Journal Publication
Projects
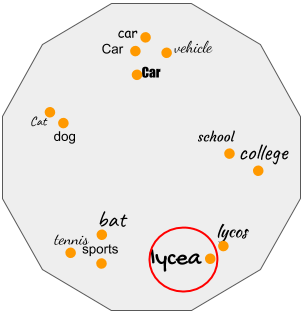 Bringing Semantics in Word Image Representation
Bringing Semantics in Word Image Representation
People Involved : Praveen Krishnan, C. V. Jawahar
In this work, we propose two novel forms of word image semantic representations. The first form learns an inflection invariant representation, thereby focusing on the root of the word, while the second form is built along the lines of textual word embedding techniques such as Word2Vec. We observe that such representations are useful for both traditional word spotting and also enrich the search results by accounting the semantic nature of the task.
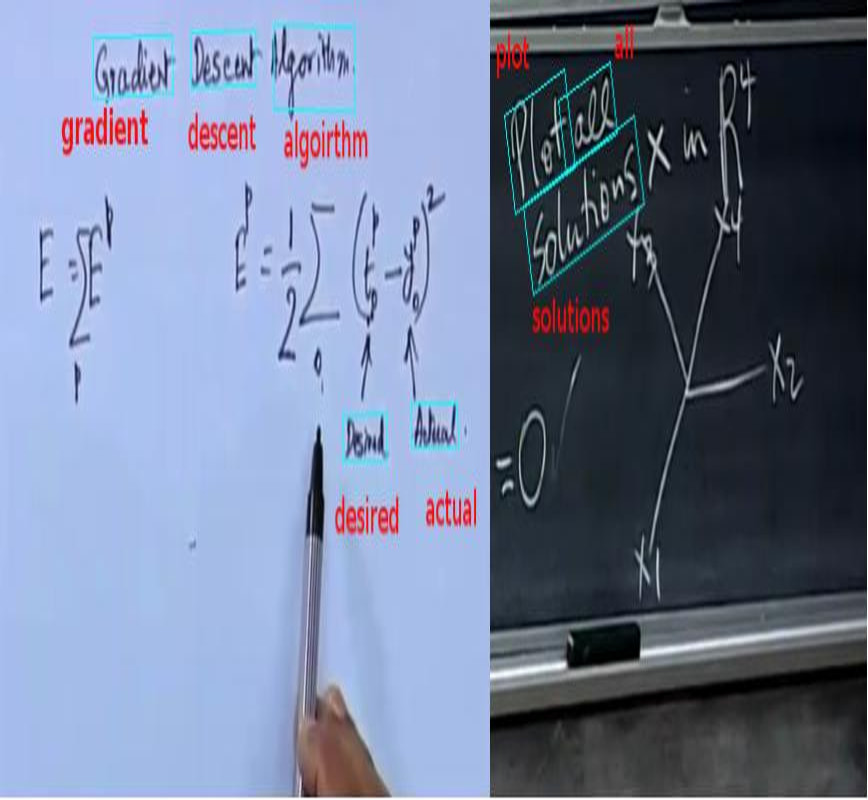 LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
People Involved : Kartik Dutta, Minesh Mathew, Praveen Krishnan and CV Jawahar
Lecture videos are rich with textual information and to be able to understand the text is quite useful for larger video understanding/analysis applications. Though text recognition from images have been an active research area in computer vision, text in lecture videos has mostly been overlooked. In this work, we investigate the efficacy of state-of-the art handwritten and scene text recognition methods on text in lecture videos
 Word level Handwritten datasets for Indic scripts
Word level Handwritten datasets for Indic scripts
People Involved : Kartik Dutta, Praveen Krishnan, Minesh Mathew and CV Jawahar
Handwriting recognition (HWR) in Indic scripts is a challenging problem due to the inherent subtleties in the scripts, cursive nature of the handwriting and similar shape of the characters. Lack of publicly available handwriting datasets in Indic scripts has affected the development of handwritten word recognizers. In order to help resolve this problem, we release 2 handwritten word datasets: IIIT-HW-Dev, a Devanagari dataset and IIIT-HW-Telugu, a Telugu dataset.
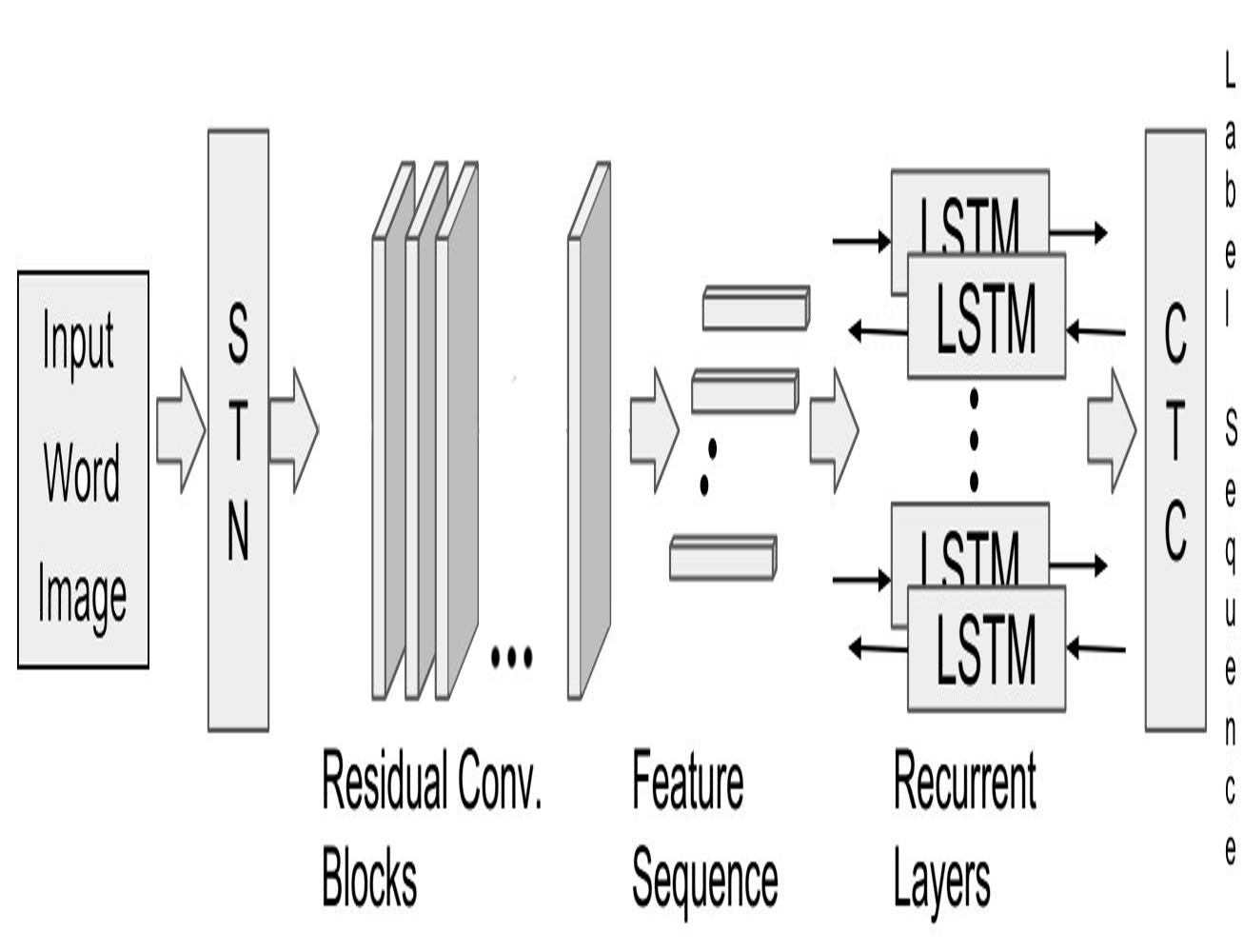
 HWNet - An Efficient Word Image Representation for Handwritten Documents
HWNet - An Efficient Word Image Representation for Handwritten Documents
People Involved : Praveen Krishnan, C. V. Jawahar
We propose a deep convolutional neural network named HWNet v2 (successor to our earlier work [1]) for the task of learning efficient word level representation for handwritten documents which can handle multiple writers and is robust to common forms of degradation and noise. We also show the generic nature of our representation and architecture which allows it to be used as off-the-shelf features for printed documents and building state of the art word spotting systems for various languages.
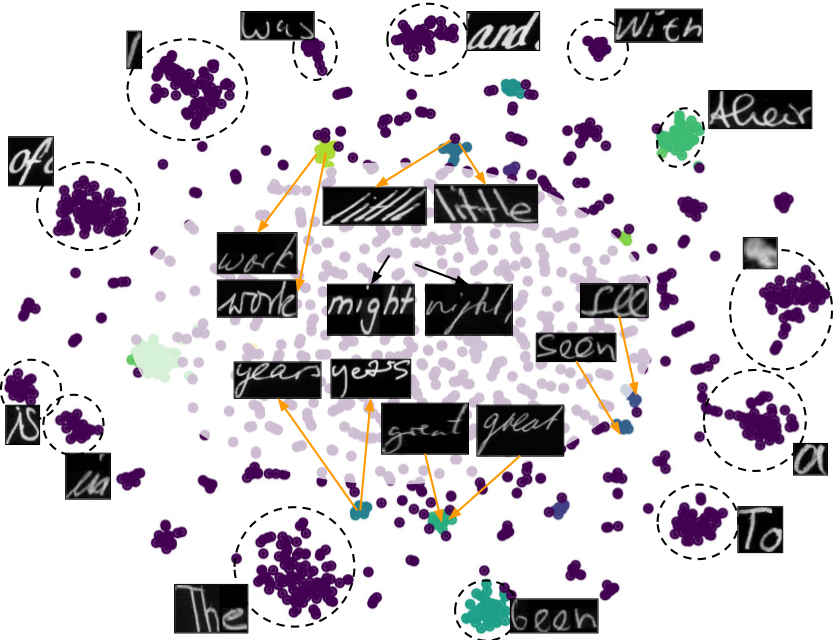
![]() Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text
Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text
People Involved : Praveen Krishnan, Kartik Dutta and C. V. Jawahar
We propose a deep convolutional feature representation that achieves superior performance for word spotting and recognition for handwritten images. We focus on :- (i) enhancing the discriminative ability of the convolutional features using a reduced feature representation that can scale to large datasets, and (ii) enabling query-by-string by learning a common subspace for image and text using the embedded attribute framework. We present our results on popular datasets such as the IAM corpus and historical document collections from the Bentham and George Washington pages.
![]() Matching Handwritten Document Images
Matching Handwritten Document Images
People Involved : Praveen Krishnan and C. V. Jawahar
We address the problem of predicting similarity between a pair of handwritten document images written by different individuals. This has applications related to matching and mining in image collections containing handwritten content. A similarity score is computed by detecting patterns of text re-usages between document images irrespective of the minor variations in word morphology, word ordering, layout and paraphrasing of the content.
 Visual Aesthetic Analysis for Handwritten Document Images
Visual Aesthetic Analysis for Handwritten Document Images
People Involved : Anshuman Majumdar, Praveen Krishnan and C. V. Jawahar
We present an approach for analyzing the visual aesthetic property of a handwritten document page which matches with human perception. We formulate the problem at two independent levels: (i) coarse level which deals with the overall layout, space usages between lines, words and margins, and (ii) fine level, which analyses the construction of each word and deals with the aesthetic properties of writing styles. We present our observations on multiple local and global features which can extract the aesthetic cues present in the handwritten documents.