Parallel Computing using CPU and GPU
Introduction
Commodity graphics hardware has become a cost-effective parallel platform to solve many general problems; owing to its low cost to performance ratio (under $0.5 per GFLOP). GPUs are optimized for graphics operations and their programming model is highly restrictive. All algorithms are disguised as graphics rendering passes with the programmable shaders interpreting the data. This was the situation until the latest model of GPUs following the Shader Model 4.0 were released late in 2006. These GPUs follow a unified architecture and can be used in more flexible ways than their predecessors. Starting from the G80 series of GPUs, Nvidia offers an alternate programming model called Compute Unified Device Architecture (CUDA) to the underlying parallel processor. CUDA is highly suited for general purpose programming on the GPUs and provides a model close to the PRAM model. There has been a tremendous amount of growth in both the programmability and efficiency of GPUs over the years, leading to many GPU based solutions for general purpose problems.
Projects involving GPU's and CUDA
1. String Sort on GPUs 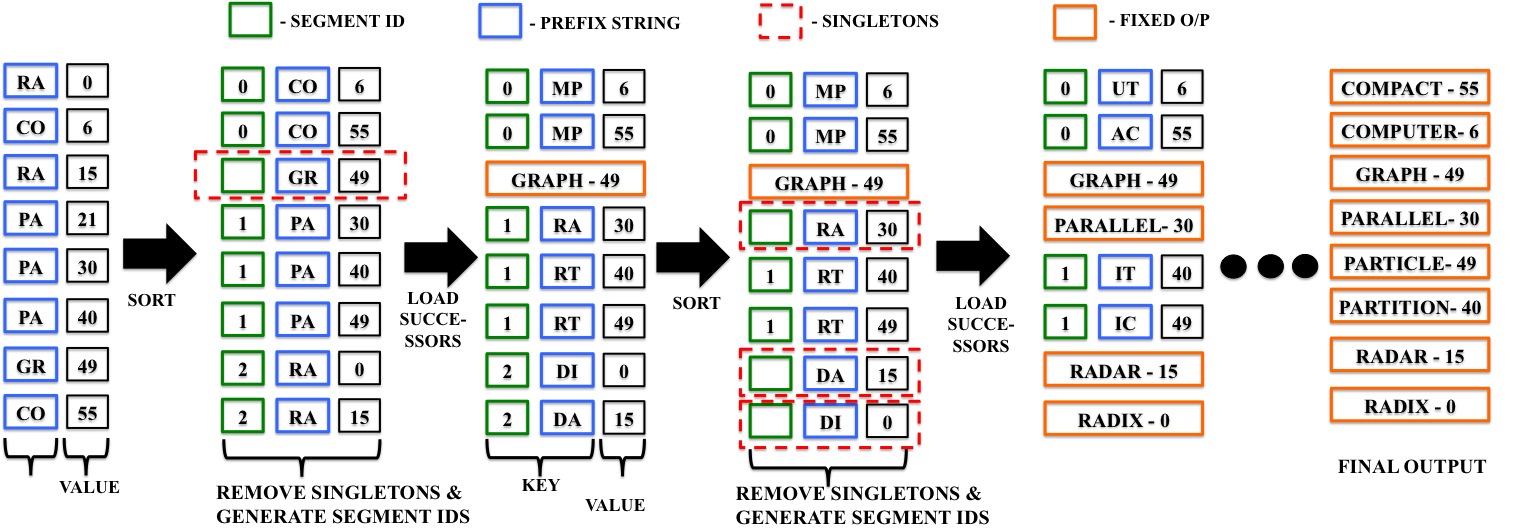
String sorting or variable-length key sorting has lagged in performance on the GPU even as the fixed-length key sorting has improved dramatically. Radix sorting is the fastest on the GPUs. In this work, we present a fast and efficient string sort on the GPU that is built on the available radix sort. Over 70% of the string sort time is spent on standard Thrust primitives for sort, scatter and scan. This provides high performance along with high adaptability to future GPUs. Our string sort algorithm is 10x faster compared to current GPU methods.
2. Mixed-Resolution Patch Matching
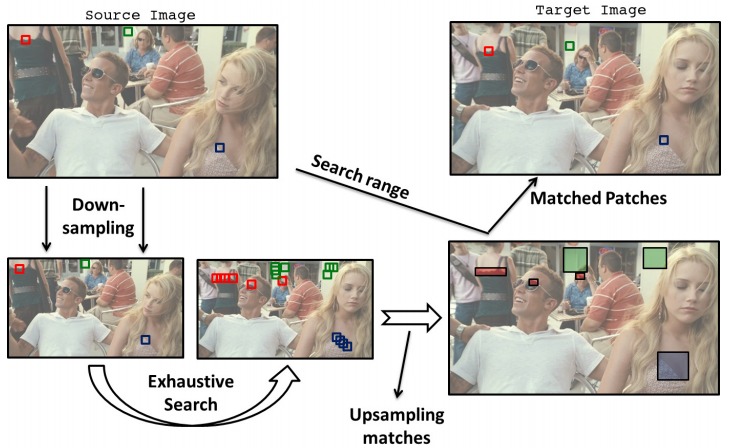 Matching patches of a source image with patches of itself or a target image is a first step for many operations. Finding the optimum nearest-neighbors of each patch using a global search of the image is expensive. Optimality is often sacrificed for speed as a result. In this work, we developed the Mixed-Resolution Patch-Matching (MRPM) algorithm that uses a pyramid representation to perform fast global search. We compare mixed-resolution patches at coarser pyramid levels to alleviate the effects of smoothing. We store more matches at coarser resolutions to ensure wider search ranges and better accuracy at finer levels. Our method achieves near optimality in terms of exhaustive search. Our simple approach enables fast parallel implementations on the GPU, yielding upto 70x speedup compared to other iterative approaches.
Matching patches of a source image with patches of itself or a target image is a first step for many operations. Finding the optimum nearest-neighbors of each patch using a global search of the image is expensive. Optimality is often sacrificed for speed as a result. In this work, we developed the Mixed-Resolution Patch-Matching (MRPM) algorithm that uses a pyramid representation to perform fast global search. We compare mixed-resolution patches at coarser pyramid levels to alleviate the effects of smoothing. We store more matches at coarser resolutions to ensure wider search ranges and better accuracy at finer levels. Our method achieves near optimality in terms of exhaustive search. Our simple approach enables fast parallel implementations on the GPU, yielding upto 70x speedup compared to other iterative approaches.
3. Scalable K-Means Clustering
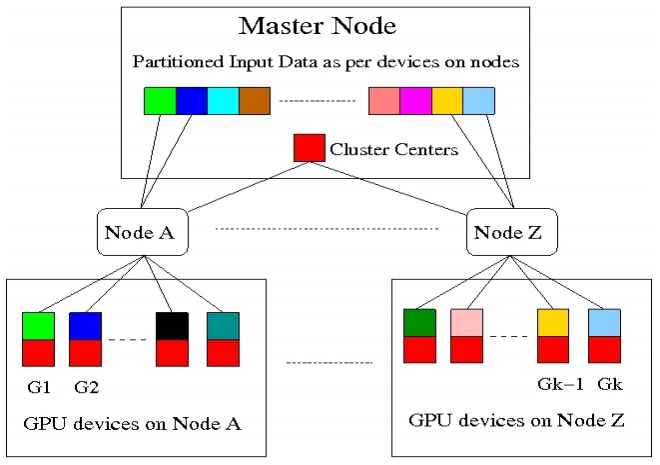 K-Means is a popular clustering algorithm with wide applications in Computer Vision, Data mining, Data Visualization, etc. Clustering large numbers of high-dimensional vectors is very computation intensive. In this work, we present the design and implementation of the K-Means clustering algorithm on the modern GPU. A load balanced multi-node, multi-GPU implementation which can handle up to 6 million, 128-dimensional vectors was also developed. Our implementation scales linearly or near-linearly with different problem parameters. We achieve up to 2 times increase in speed compared to the best GPU implementation for K-Means on a single GPU.
K-Means is a popular clustering algorithm with wide applications in Computer Vision, Data mining, Data Visualization, etc. Clustering large numbers of high-dimensional vectors is very computation intensive. In this work, we present the design and implementation of the K-Means clustering algorithm on the modern GPU. A load balanced multi-node, multi-GPU implementation which can handle up to 6 million, 128-dimensional vectors was also developed. Our implementation scales linearly or near-linearly with different problem parameters. We achieve up to 2 times increase in speed compared to the best GPU implementation for K-Means on a single GPU.
4. Error Diffusion Dithering
 Many image filtering operations provide ample parallelism, but progressive non-linear processing of images is among the hardest to parallelize due to long, sequential, and non-linear data dependency. A typical example of such an operation is error diffusion dithering, exemplified by the Floyd-Steinberg algorithm. In this work, we present its parallelization on multicore CPUs using a block-based approach and on the GPU using a pixel-based approach. We also develop a hybrid approach in which the CPU and the GPU operate in parallel during the computation. Our implementation can dither an 8K x 8K image on an off-the-shelf laptop with Nvidia 8600M GPU in about 400 milliseconds when the sequential implementation on its CPU took about 4 seconds.
Many image filtering operations provide ample parallelism, but progressive non-linear processing of images is among the hardest to parallelize due to long, sequential, and non-linear data dependency. A typical example of such an operation is error diffusion dithering, exemplified by the Floyd-Steinberg algorithm. In this work, we present its parallelization on multicore CPUs using a block-based approach and on the GPU using a pixel-based approach. We also develop a hybrid approach in which the CPU and the GPU operate in parallel during the computation. Our implementation can dither an 8K x 8K image on an off-the-shelf laptop with Nvidia 8600M GPU in about 400 milliseconds when the sequential implementation on its CPU took about 4 seconds.
5. Graph Algorithms on CUDA
 We have developed several basic graph algorithms on the CUDA architecture including BFS, Single Source Shortest Path(SSSP), All-Pairs Shortest Path(APSP), and Minimum Spanning Tree computation for large graphs consisting of millions of vertices and edges. We show results on random, scale free and almost linear graphs. Our approaches are 10-50 times faster than their CPU counterparts, on random graphs with an average degree of 6 per vertex.
We have developed several basic graph algorithms on the CUDA architecture including BFS, Single Source Shortest Path(SSSP), All-Pairs Shortest Path(APSP), and Minimum Spanning Tree computation for large graphs consisting of millions of vertices and edges. We show results on random, scale free and almost linear graphs. Our approaches are 10-50 times faster than their CPU counterparts, on random graphs with an average degree of 6 per vertex.
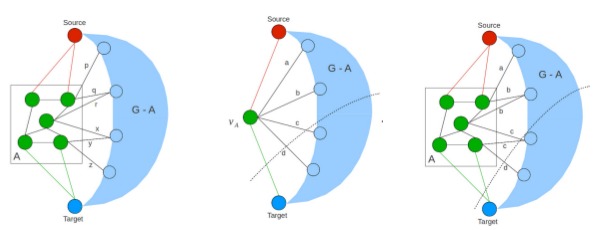
We have also developed efficient parallel implementations for performing Graph-Cuts on grid graphs in CUDA. Our original work, titled CUDA-Cuts is based on the push-relabel operation for computing the max-flow and hence the min-cut of a graph. We have also developed a multi-resolution framework for max-flow computation which depends on shrink-expand steps in order to solve the graph fully at lower resolution levels, and uses these results to initialize higher resolution graphs closer to convergence. This improves the overall convergence time for the operation.
Related Publications
Aditya Deshpande and P. J. Narayanan - Can GPUs Sort Strings Efficiently? Proceedings of the IEEE Conference on High Performance Computing (HiPC), 18-21 Dec. 2013, Bangalore, India. [PDF]
Harshit Surekha and P J Narayanan - Mixed-Resolution Patch-Matching Proceedings of 12th European Conference on Computer Vision, 7-13 Oct. 2012, Vol. ECCV 2012, Part-VI, LNCS 7577, pp. 187-198, Firenze, Italy. [PDF]
Parikshit Sakurikar and P J Narayanan - Fast Graph Cuts using Shrink-Expand Reparameterization Proceedings of IEEE Workshop on Applications of Computer Vision (WACV) 9-11 Jan. 2012, ISSN 1550-5790 E-ISBN 978-1-4673-0232-6, Print ISBN 978-1-4673-0233-3, pp. 65-71, Breckenridge, CO, USA. [PDF]
Aditya Deshpande, Ishan Misra and P J Narayanan - Hybrid Implementation of Error Diffusion Dithering Proceedings of 18th International Conference on High Performance Computing (HIPC), 18-21 Dec. 2011, E-ISBN 978-1-4577-1949-3, Print ISBN 978-1-4577-1951-6, pp. 1-10, Bangalore, India. [PDF]
K. Wasif Mohiuddin and P.J. Narayanan - Scalable Clustering Using Multiple GPUs Proceedings of International Conference on High Performance Computing (HIPC) 18-21 Dec. 2011, E-ISBN 978-1-4577-1949-3, Print ISBN 978-1-4577-1951-6, Bangalore, India. [PDF]
Vibhav Vineet and P. J. Narayanan - CUDA Cuts: Fast Graph Cuts on the GPU Proceedings of CVPR Workshop on Visual Computer Vision on GPUs, 23-28th june, Anchorage, Alaska, USA. IEEE Computer Society 2008 [PDF]
Pawan Harish and P.J. Narayanan - Accelerating Large Graph Algorithms on the GPU using CUDA Proc of IEEE International Conference on High Performance Computing (HiPC 2007) Goa, December, 2007. [PDF]
Associated People
|
|
|