Private Content Based Image Retrieval
Introduction
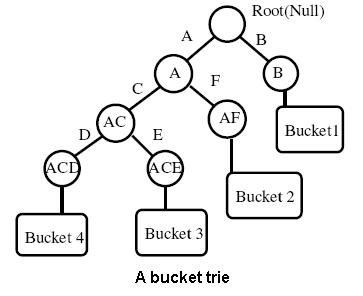
For content level access, very often database needs the query as a sample image. However, the image may contain private information and hence the user does not wish to reveal the image to the database. Private Content Based Image Retrieval (PCBIR) deals with retrieving similar images from an image database without revealing the content of the query image . not even to the database server.
PCBIR Overview
-
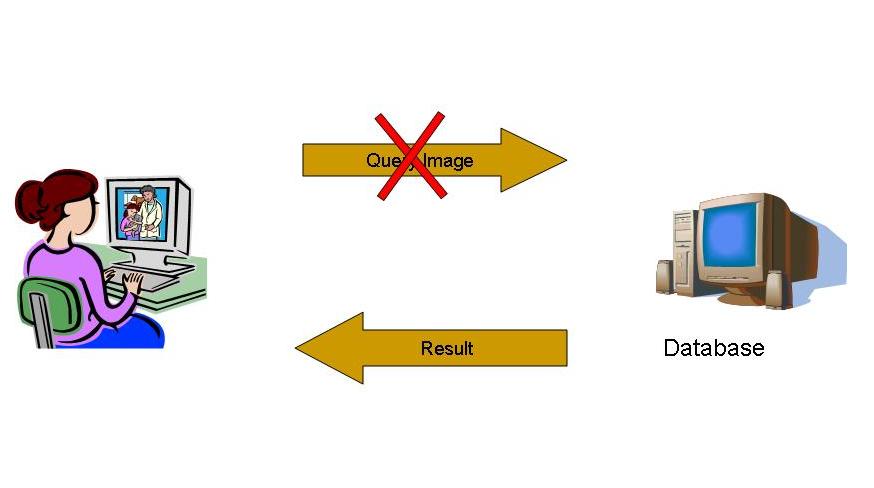
The user extracts the feature vector of the query image,say fquery.
- The user first asks the database to send the information at the root node.
- Using fquery and the information received, the user decides whether to access the left subtree or the right subtree.
- In order to get the data at the node to be accessed, the user frames a query Qi where i indicates the level in which the node occurs.(Please note that the root is at level 0)
- The database returns a reply Ai for the query Qi.
- The user performs a simple function f(Ai) to obtain the information at the node. If the node is a leaf node, user adds the information to the results else goto step 3.
PCBIR on a Binary Search Tree
Preprocessing Step
- Consider a natural number N = p. q where p, q are large prime numbers.
- Construct a set Zn*={x| 1 < x < N, gcd(N,x)=1}
- `y` is called a Quadratic Residue (QR), if x | y = x2 and else `y` is called a Quadratic Non-Residue (QNR).
- Construct a set YN with equal number of QRs and QNRs
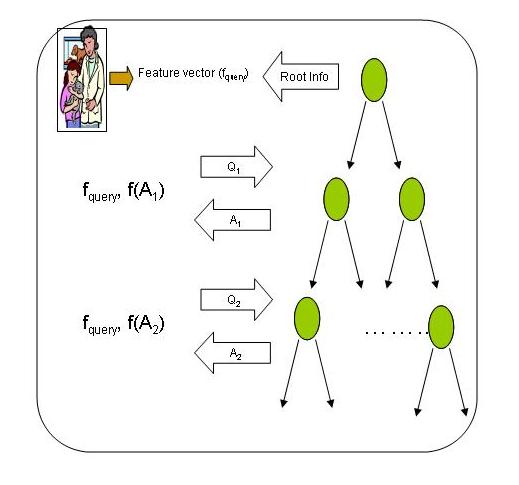
- Suppose the user wants to extract the kth node at ith level in the tree. The ith level shall contain 2i nodes.
- All the nodes are treated as a 2D array of mxn dimensions where m x n = 2i.
- If the user wants to access the kth node, now he has to access the node at (k/n, k mod n) (say this is (x,y)).
- To get the data at node (x,y), the user frames a query Qi of length m, with a QNR at position x and rest of the values being QRs.
- The database computes a reply Ai for the query Qi by forming a matrix, in which if the value at the node is 1, its replaced by square of the value in query else its replaced by the value. Then the matrix is multiplied column wise to obtain the reply Ai of length n.
- The user then checks whether the value at the yth position is a QR or a QNR. If it is a QR the value is 1 else it is 0. This is due to the properties below
- QNR x QNR = QR
- QNR x QR = QNR
- QR x QR = QR
- The above protocol is run for every level. Since the database is oblivious about the node which the user is trying to extract, the query path is hidden securing the privacy of the query image.
The algorithm is based on the Quadratic Residuosity Assumption which states that:
Given a number `y` belongs to YN, it is predictably hard to decide whether `y` is a QR or a QNR..
Extension to other Hierarchical Structures
Hierarchical structures primarily vary in
- Number of nodes at each level.
- Information at a node.
If we can take care of these two, the algorithm can be extended to any hierarchical structure used for indexing. Our algorithm requires a m x n matrix to be formed and a set of nodes at a level can be easily converted in to such a format (irrespective of the number of the nodes). Moreover the data transfer takes place in binary format and any data in the intermediate nodes of an indexing structure can be represented in binary format. So if the user has the data about the indexing structure and the format of the information stored at a node, the algorithm can be simulated for any hierarchical structure.
Experiments and Results
Experiments were conducted on popular indexing schemesto check the feasibility and applicability of the PCBIR algorithms. The experiments were conducted using a GNU C compiler on a 2 GHz Intel Pentium M process with 4 GigaBytes of main memory. Information regarding the indexing structures and the datasets.
- KD-Tree and Corel Database
The Corel dataset consisted of 9907 images, scaled to 256 x 128 resolution. The color feature was used to index the images. The feature vector (i.e color histogram) was 768 in length (256 values each for RGB). A KD tree usually stores the ssplit value and split dimension at non leaf nodes. Each value was represented in 32 bits, thus the total information at each intermediate/non-leaf node was 64 bits. Sample results have been shown below. The image with a black box is the query image and the other images are the top 4 retrieved images. The Corel dataset consisted of 9907 images, scaled to 256 x 128 resolution. The color feature was used to index the images. The feature vector (i.e color histogram) was 768 in length (256 values each for RGB). A KD tree usually stores the ssplit value and split dimension at non leaf nodes. Each value was represented in 32 bits, thus the total information at each intermediate/non-leaf node was 64 bits. Sample results have been shown below. The image with a black box is the query image and the other images are the top 4 retrieved images.


The average retrieval time for a query was 0.596 secs. The time was obtained by amortization over 100 queries.
- Vocabulary Tree and Nister Dataset
SIFT featues in an image were used to obtain a vocabulary of visual words. The vocabulary was of 10,000 visual words. The Nister dataset consisting of 10,200 images was used. The dataset consists of 2540 object photographed from 4 different angles and lighting conditions. The vocabulary tree was constructed using a training set of 2000 images which were picked from the dataset itself. Sample results have been shown below. The image with a black box is the query image and the other images are the top 4 retrieved images.


The average retrieval time for a query was 0.320 secs. The time was obtained by averaging over 50 queries which were amortized.Since the vocabulary tree allows us to change the size of the vocabulary, retrieval times under various vocabulary sizes were recorded in the following graph.
LSH consisted of a set of 90 hash functions each with 450 bins on average. The images in each bin were further subdivided by applying LSH again - Thus gaining an hierarchy of 2 levels. The average retrieval time was 0.221.The algorithm can also be used to achieve partial privacy which is indicated by 'n', also known as the confusion metric. When its value is 1, the retrieval is completely private and 0 indicates that its non-private image retrieval.
Due to the lack of very large standard image datasets, we had to test the scalability of our system using synthetic datasets. The retrieval times for various dataset sizes is provided in the table below.
| Dataset Size |
Average Retrieval Time |
| 2^10 |
0.005832 |
| 2^12 |
0.008856 |
| 2^14 |
0.012004 |
| 2^16 |
0.037602 |
| 2^18 |
0.129509 |
| 2^20 |
0.261255 |
Related Publications
Shashank Jagarlamudi, Kowshik Palivela, Kannan Srinathan, C. V. Jawahar : Private Content Based Image Retrieval. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2008.
Associated People
- Shashank Jagarlamudi
- Kowshik PalivelaK
- Kannan Srinathan
- C.V. Jawahar
Additionals