Contours, Textures, Homography and Fourier Domain
Objective
The aim of this study is to come up with a Fourier representation of contours and then utilise it to estimate two view relationships like homography and also come up with novel invariants. Ordering in Contours is a very important geometrical information which had been given very less attention till now. We have proposed novel representation for contour sequences in transform domain which helps us exploit the ordering information. This representation was also extended to build affine invariants which could be used in computer vision problems.
A similar transform domain relationship was developed for textures in images. This was used in estimation of homography.
Contributions
Some of the major contributions of this study are ::
- Fourier representation of contours.
- Development of invariants which were demonstrated to be useful in planar shape recognition.
- Algorithms for homography estimation from textures and contours.
- Use of invariants to build a polygonal approximation of contours which was used for homography estimation.
- Successful estimation of geometric relationships like homography and measures like invariants with higher order primitives like contours and conics.
- Alegraic constratints on a moving point configuration were developed.
|
|
|

 in the top image were used to reconstruct the scene geometry and render the views below.")
Related Publications
Paresh Kumar Jain and C.V. Jawahar - Homography Estimation from Planar Contours, Third International Symposium on 3D Data Processing, Visualization and Transmission (3DVPT), North Carolina, Chappel Hill, June 14-16, 2006. [PDF]
M. Pawan Kumar, Saurabh Goyal, Sujit Kuthirummal, C. V. Jawahar and P. J. Narayanan - Discrete Contours in Multiple Views: Approximation and Recognition Journal of Image and Vision Computin, Vol. 22, No. 14, December 2004, pp. 1229--1239. [PDF]
M. Pawan Kumar, Sujit Kuthirummal, C. V. Jawahar and P. J. Narayanan - Planar Homography from Fourier Domain Representation, Proceedings of the International Conference on Signal Processing and Communications(SPCOM), Dec. 2004, Bangalore, India. [PDF]
M. Pawan Kumar, C. V. Jawahar and P. J. Narayanan, Geometric Structure Computation from Conics, Proceedings of the Indian Conference on Vision, Graphics and Image Processing(ICVGIP), Dec. 2004, Calcutta, India, pp. 9-14. [PDF]
M. Pawan Kumar, C. V. Jawahar and P. J. Narayanan, Building Blocks for Autonomous Navigation using Contour Correspondences, Proceedings of the International Conference on Image Processing(ICIP), Oct. 2004, Singapore, pp. 1381-1384. [PDF]
Sujit Kuthirummal, C. V. Jawahar and P. J. Narayanan - Fourier Domain Representation of Planar Curves for Recognition in Multiple Views, Pattern Recognition, Vol. 37, No. 4, April 2004, pp. 739--754. [PDF]
Sujit Kuthirummal, C.V. Jawahar and P.J. Narayanan - Algebraic Constraints on Moving Points in Multiple Views, Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing(ICVGIP), Dec. 2002, Ahmedabad, India, pp. 311--316. [PDF]
M. Pawan Kumar, Saurabh Goyal, C.V. Jawahar, and P.J. Narayanan - Polygonal Approximation of Closed Curves Across Multiple Views, Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing(ICVGIP), Dec. 2002, Ahmedabad, India, pp. 317--322. [PDF]
Sujit Kuthirummal, C.V. Jawahar and P.J. Narayanan - Multiview Constraints for Recognition of Planar Curves in Fourier Domain, Proceedings of the Indian Conference on Computer Vision, Graphics and Image Processing(ICVGIP), Dec. 2002, Ahmedabad, India, pp. 323--328. [PDF]
Sujit Kuthirummal, C. V. Jawahar and P. J. Narayanan, Planar Shape Recognition across Multiple Views, Proceedings of the International Conference on Pattern Recognition(ICPR), Aug. 2002, Quebec City, Canada, pp. 482--488. [PDF]
Associated People
- Sujit Kuthirummal
- Paresh Kumar Jain
- M. Pawan Kumar
- Saurabh Goyal
- Dr. C. V. Jawahar
- Prof. P. J. Narayanan


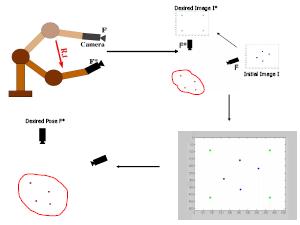
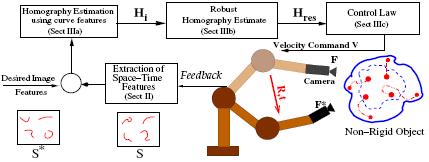 Most robotic vision algorithms are proposed by envisaging robots operating in structured environments where the world is assumed rigid and planar. These algorithms fail to provide optimum behavior when the robot has to be controlled with respect to active non-rigid non-planar targets. We have developed a new framework for visual servoing that accomplishes the robot-positioning task even in such unconventional environments. We introduced a novel space-time representation scheme for modeling the deformations of a non-rigid object and proposed a new vision-based approach that exploited the two-view geometry induced by the space-time features to perform the servoing task.
Most robotic vision algorithms are proposed by envisaging robots operating in structured environments where the world is assumed rigid and planar. These algorithms fail to provide optimum behavior when the robot has to be controlled with respect to active non-rigid non-planar targets. We have developed a new framework for visual servoing that accomplishes the robot-positioning task even in such unconventional environments. We introduced a novel space-time representation scheme for modeling the deformations of a non-rigid object and proposed a new vision-based approach that exploited the two-view geometry induced by the space-time features to perform the servoing task.

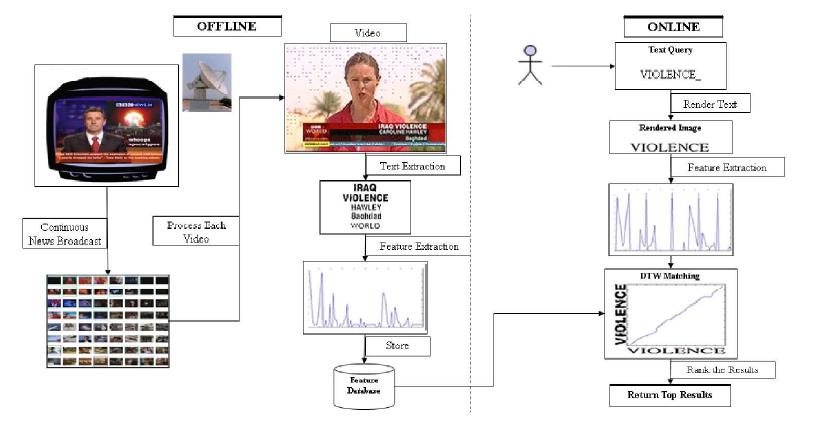
 Matching words in the image space should handle the many variations in font size, font type, style, noise, degradations etc. that are present in document images. The features and the matching technique were carefully designed to handle this variety. Further, morphological word variations, such as prefix and suffixes for a given stem word, are identified using an innovative partial matching scheme. We use Dynamic Time Warping (DTW) based matching algorithm which enables us to efficiently exploit the information supplied by local features, that scans vertical strips of the word images.
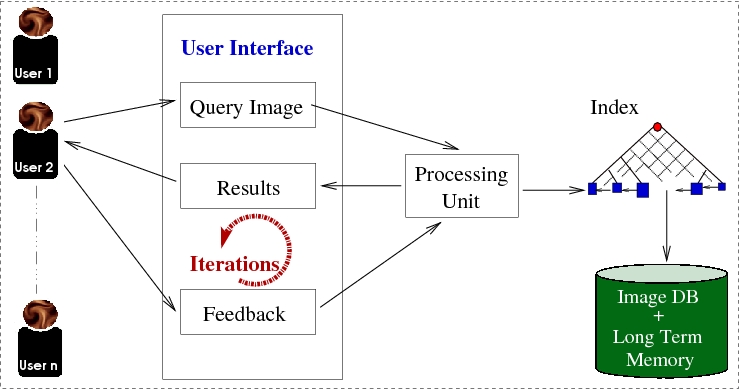
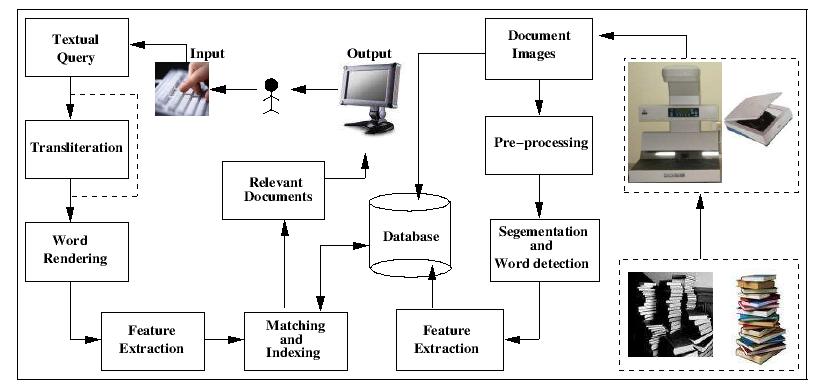
Matching words in the image space should handle the many variations in font size, font type, style, noise, degradations etc. that are present in document images. The features and the matching technique were carefully designed to handle this variety. Further, morphological word variations, such as prefix and suffixes for a given stem word, are identified using an innovative partial matching scheme. We use Dynamic Time Warping (DTW) based matching algorithm which enables us to efficiently exploit the information supplied by local features, that scans vertical strips of the word images.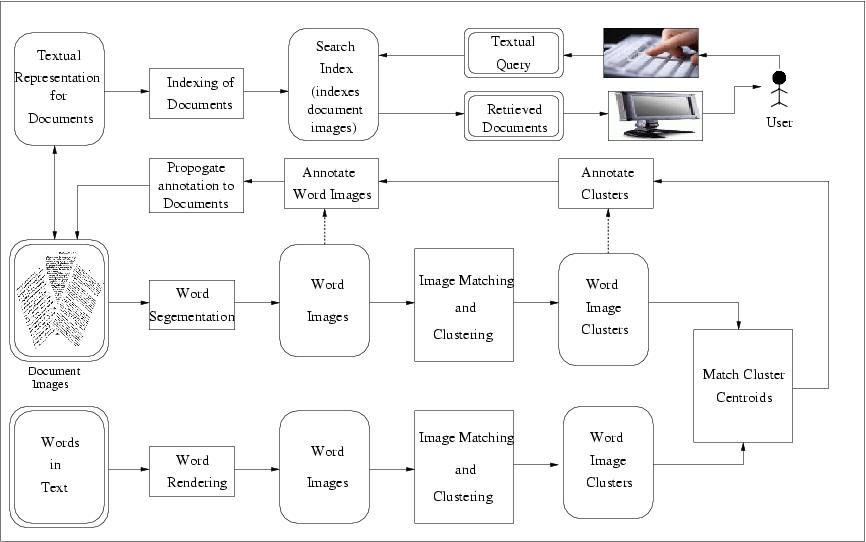 Online matching of a query word against a search index is a computationally intensive process and thus time consuming. This can be avoided by performing annotation of the word images. Annotation assigns a corresponding text word to each word image. This enables further processing, such as indexing and retrieval, to occur in the text domain. Search and retireval in text domain allows us to build search systems which have interactive response times.
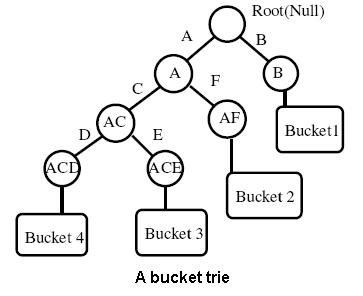
Online matching of a query word against a search index is a computationally intensive process and thus time consuming. This can be avoided by performing annotation of the word images. Annotation assigns a corresponding text word to each word image. This enables further processing, such as indexing and retrieval, to occur in the text domain. Search and retireval in text domain allows us to build search systems which have interactive response times.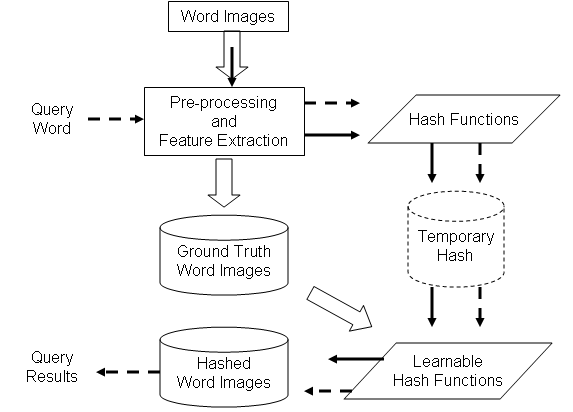 In databases, hashing of data is considered an efficient alternative to indexing (and clustering). In hashing, a single function value is computed for each word image. The words that have same (or similar) hash values are placed in the same bin. Effectively, the words with similar hash values are clustered together. With such a scheme, indexing search and retrieval of documents is linear in time complexity, which is a significant prospect.
In databases, hashing of data is considered an efficient alternative to indexing (and clustering). In hashing, a single function value is computed for each word image. The words that have same (or similar) hash values are placed in the same bin. Effectively, the words with similar hash values are clustered together. With such a scheme, indexing search and retrieval of documents is linear in time complexity, which is a significant prospect.