Combining Data Parallelism and Task Parallelism for Efficient Performance on Hybrid CPU and GPU Systems
Aditya Deshpande (homepage)
In earlier times, computer systems had only a single core or processor. In these computers, the number of transistors on-chip (i.e. on the processor) doubled every two years and all applications enjoyed free speedup. Subsequently, with more and more transistors being packed on-chip, power consumption became an issue, frequency scaling reached its limits and industry leaders eventually adopted the paradigm of multi-core processors. Computing platforms of today have multiple cores and are parallel. CPUs have multiple identical cores. A GPU with dozens to hundreds of simpler cores is present on many systems. In future, other multiple core accelerators may also be used.
With the advent of multiple core processors, the responsibility of extracting high performance from these parallel platforms shifted from computer architects to application developers and parallel algorithmists. Tuned parallel implementations of several mathematical operations, algorithms on graphs or matrices on multi-core CPUs and on many-core accelerators like the GPU and CellBE, and their combinations were developed. Parallel algorithms developed for multi-core CPUs primarily focussed on decomposing the problem into a few independent chunks and using the cache efficiently. As an alternative to CPUs, Graphics Processing Units (GPUs) were the other most cost-effective and massively parallel platforms, that were widely available. Frequently used algorithmic primitives such as sort, scan, sparse matrix vector multiplication, graph traversals, image processing operations etc. among others were efficiently implemented on GPU using CUDA. These parallel algorithms on the GPU decomposed the problem into a sequence of many independent steps operating on different data elements and used shared memory effectively.
But the above operations -- statistical, or on graphs, matrices and list etc. -- constitute only portions of an end-to-end application and in most cases these operations also provide some inherent parallelism (task or data parallelism). The problems which lack such task or data parallelism are still difficult to map to any parallel platform, either CPU or GPU. In this thesis, we consider a few such difficult problems -- like Floyd-Steinberg Dithering (FSD) and String Sorting -- that do not have trivial data parallelism and exhibit strong sequential dependence or irregularity. We show that with appropriate design principles we can find data parallelism or fine-grained parallelism even for these tough problems. Our techniques to break sequentiality and addressing irregularity can be extended to solve other difficult data parallel problems in the future. On the problem of FSD, our data parallel approach achieves a speedup of 10X on high-end GPUs and a speedup of about 3-4X on low-end GPUs, whereas previous work by Zhang et al. dismiss the same algorithm as lacking enough parallelism for GPUs. On string sorting, we achieve a speedup of around 10-19X as compared to state-of-the-art GPU merge sort based methods and our code will be available as part of standard GPU Library (CUDPP).
It is not enough to have a truly fine-grained parallel alogrithm for only a few operations. Any end-to-end application consists of many operations, some of which are difficult to execute on a fine-grained parallel platform like GPU. At the same time, computing platforms consist of CPU and a GPU which have complementary attributes. CPUs are suitable for some heavy processing by only a few threads i.e. they prefer task parallelism. GPUs is more suited for applications where large amount of data parallel operations are performed. Applications can achieve optimal performance by combining data parallelism on GPU with task parallelism on CPU. In this thesis, we examine two methods of combining data parallelism and task parallelism on a hybrid CPU and GPU computer system: (i) pipelining and (ii) work sharing. For pipelining, we study the Burrows Wheeler Compression (BWC) implementation in Bzip2 and show that best performance can be achieved by pipelining its different stages effectively. In contrast, a previous GPU implementation of BWC by Patel et al. performed all the tasks (BWT, MTF and Huffman encoding) on the GPU and it was 2.78X slower than CPU. Our hybrid BWC pipeline performs about 2.9X better than CPU BWC and thus, about 8X faster than Patel et al. For work sharing, we use FSD as an example and split the data parallel step between CPU and GPU. The Handover and Hybrid FSD algorithms, which use work sharing to exploit computation resources on both CPU and GPU, are faster than the CPU alone and GPU alone parallel algorithms.
In conclusion, we develop data parallel algorithms on the GPU for difficult problems of Floyd-Steinberg Dithering, String Sorting and Burrows Wheeler Transform. In earlier literature, simpler problems which provided some degree of data parallelism were adapted to the GPUs. The problems we solve on GPU involve challenging sequential dependency and/or irregularity. We show that in addition to developing fast data parallel algorithms on GPU, application developers should also use the CPU to execute tasks in parallel with GPU. This allows an application to fully utilize all resources of an end-user's system and provides them with maximum performance. With computing platforms poised to be predominantly hetergoneous, the use of our design principles will prove critical in obtaining good application level performance on these platforms. (more...)
| Year of completion: | July 2014 |
| Advisor : | Prof. P. J. Narayanan |
Related Publications
Aditya Deshpande and P. J. Narayanan - Can GPUs Sort Strings Efficiently? Proceedings of the IEEE Conference on High Performance Computing (HiPC), 18-21 Dec. 2013, Bangalore, India. [PDF]
Aditya Deshpande, Ishan Misra and P J Narayanan - Hybrid Implementation of Error Diffusion Dithering Proceedings of 18th International Conference on High Performance Computing (HIPC), 18-21 Dec. 2011, E-ISBN 978-1-4577-1949-3, Print ISBN 978-1-4577-1951-6, pp. 1-10, Bangalore, India. [PDF]
- Aditya Deshpande and P. J. Narayanan - Fast Burrows Wheeler Compression Using CPU and GPU (Under Review, ACM TOPC).
Downloads
![]()
![]()
 Reliefs carvings have certain specific attributes that makes them different from regular sculptures, which can be exploited in different computer vision tasks. Repetitive patterns are one such frequently occurring phenomenon in reliefs. Algorithms for detection of repeating patterns in images often assume that the repetition is regular and highly similar across the instances. Approximate repetitions are also of interest in many domains such as hand carved sculptures, wall decorations, groups of natural objects, etc. Detection of such repetitive structures can help in applications such as image retrieval, image inpainting and 3D reconstruction. In this work, we look at a specific class of approximate repetitions: those in images of hand carved relief structures. We present a robust hierarchical method for detecting such repetitions. Given a single relief panel image, our algorithm finds dense matches of local features across the image at various scales. The matching features are then grouped based on their geometric configuration to find repeating elements. We also propose a method to group the repeating elements to segment the repetitive patterns in an image. In relief images, foreground and background have nearly the same texture, and matching of a single feature would not provide reliable evidence of repetition. Our grouping algorithm integrates evidences of repetition to reliably find repeating patterns. Input image is processed on a scale-space pyramid to effectively detect all possible repetitions at different scales. Our method has been tested on images with large varieties of complex repetitive patterns and the qualitative results show the robustness of our approach.Point-based rendering suffer from the limited resolution of the fixed number of samples representing the model. At some distance, the screen space resolution is high relative to the point samples, which causes under-sampling. A better way of rendering a model is to re-sample the surface during the rendering at the desired resolution in object space, guaranteeing a sampling density sufficient for image resolution. Output sensitive sampling samples objects at a resolution that matches the expected resolution of the output image. This is crucial for hole-free point-based rendering. Many technical issues related to point-based graphics boil down to reconstruction and re-sampling. A point based representation should be as small as possible while conveying the shape well.
Reliefs carvings have certain specific attributes that makes them different from regular sculptures, which can be exploited in different computer vision tasks. Repetitive patterns are one such frequently occurring phenomenon in reliefs. Algorithms for detection of repeating patterns in images often assume that the repetition is regular and highly similar across the instances. Approximate repetitions are also of interest in many domains such as hand carved sculptures, wall decorations, groups of natural objects, etc. Detection of such repetitive structures can help in applications such as image retrieval, image inpainting and 3D reconstruction. In this work, we look at a specific class of approximate repetitions: those in images of hand carved relief structures. We present a robust hierarchical method for detecting such repetitions. Given a single relief panel image, our algorithm finds dense matches of local features across the image at various scales. The matching features are then grouped based on their geometric configuration to find repeating elements. We also propose a method to group the repeating elements to segment the repetitive patterns in an image. In relief images, foreground and background have nearly the same texture, and matching of a single feature would not provide reliable evidence of repetition. Our grouping algorithm integrates evidences of repetition to reliably find repeating patterns. Input image is processed on a scale-space pyramid to effectively detect all possible repetitions at different scales. Our method has been tested on images with large varieties of complex repetitive patterns and the qualitative results show the robustness of our approach.Point-based rendering suffer from the limited resolution of the fixed number of samples representing the model. At some distance, the screen space resolution is high relative to the point samples, which causes under-sampling. A better way of rendering a model is to re-sample the surface during the rendering at the desired resolution in object space, guaranteeing a sampling density sufficient for image resolution. Output sensitive sampling samples objects at a resolution that matches the expected resolution of the output image. This is crucial for hole-free point-based rendering. Many technical issues related to point-based graphics boil down to reconstruction and re-sampling. A point based representation should be as small as possible while conveying the shape well.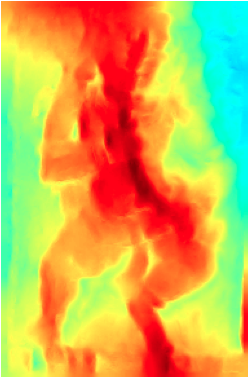
 Reconstructing geometric models of relief carvings are also of great importance in preserving her- itage artifacts, digitally. In case of reliefs, using laser scanners and structured lighting techniques is not always feasible or are very expensive given the uncontrolled environment. Single image shape from shading is an underconstrained problem that tries to solve for the surface normals given the intensity image. Various constraints are used to make the problem tractable. To avoid the uncontrolled lighting, we use a pair of images with and without the flash and compute an image under a known illumination. This image is used as an input to the shape reconstruction algorithms. We present techniques that try to reconstruct the shape from relief images using the prior information learned from examples. We learn the variations in geometric shape corresponding to image appearances under different lighting conditions using sparse representations. Given a new image, we estimate the most appropriate shape that will result in the given appearance under the specified lighting conditions. We integrate the prior with the normals computed from reflectance equation in a MAP framework. We test our approach on relief images and compare them with the state-of-the-art shape from shading algorithms. (
Reconstructing geometric models of relief carvings are also of great importance in preserving her- itage artifacts, digitally. In case of reliefs, using laser scanners and structured lighting techniques is not always feasible or are very expensive given the uncontrolled environment. Single image shape from shading is an underconstrained problem that tries to solve for the surface normals given the intensity image. Various constraints are used to make the problem tractable. To avoid the uncontrolled lighting, we use a pair of images with and without the flash and compute an image under a known illumination. This image is used as an input to the shape reconstruction algorithms. We present techniques that try to reconstruct the shape from relief images using the prior information learned from examples. We learn the variations in geometric shape corresponding to image appearances under different lighting conditions using sparse representations. Given a new image, we estimate the most appropriate shape that will result in the given appearance under the specified lighting conditions. We integrate the prior with the normals computed from reflectance equation in a MAP framework. We test our approach on relief images and compare them with the state-of-the-art shape from shading algorithms. (