Mixed-Resolution Patch-Matching
Harshit Sureka (homepage)
The problem of matching small image regions or patches between images is central to many image editing and computer vision tasks. In this thesis, we propose two related solutions to the problem of fast and global patch-matching. First, we present a multi-resolution spatial pyramid based solution, which we call Pyramid Patch-Matching (PPM). It uses a simple coarse-to-fine framework powered by exhaustive search at the coarsest resolution and local directed search at finer resolutions. PPM quickly finds accurate patch correspondences between images or image regions. The search step in our algorithm is flexible to accommodate the use of other nearest-neighbor algorithms within its framework. A proposed increase K technique enables PPM to store more number of matches than required at coarse resolutions which maintains a wide search range. This improves accuracy by up-to 2%. Its effect is most significant when less number of matches are required. The {\em early-termination} technique preempts the distance calculation between patches, if the distance exceeds that of the farthest match currently stored. This speeds up the algorithm by up-to 1.7x. Following the downsampling rule, the {\em reduce patch-size} technique matches smaller patches than required at coarser resolutions of the pyramid. Empowered by these techniques, PPM achieves state-of-the-art accuracy outperforming previous standards of Coherency Sensitive Hashing (CSH) and PatchMatch without compromising on execution-time. PPM finds up-to 4% more of the ground-truth matches and achieves lower error values compared to CSH, the current standard.
Several parameters are provided to tune the search for good matches based upon the application. We perform experiments to study effects of these parameters on matching accuracy and computation time. While consistently achieving lower error values for RGB distance between matched patches, the simplicity of our algorithm also enables fast parallel implementations, providing further advantage over previous randomized, hashing or tree-based iterative approaches. On CPU cores, it achieves a near-linear time speed-up w.r.t. the number of cores and a GPU implementation provides a further speed-up of up to 70x compared to a CPU implementation run on a quad-core machine (250x w.r.t. single core).
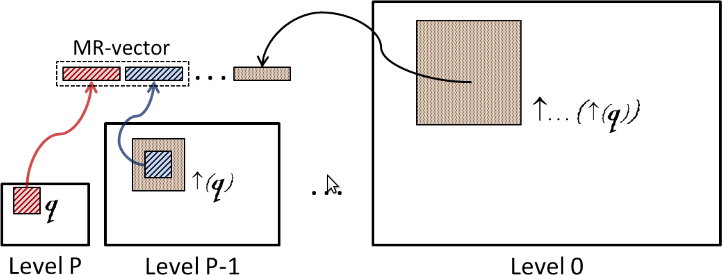
We observe that the matching accuracy of PPM suffers from low confidence matching of patch-vectors at coarse resolutions. To solve this, we propose a novel way to mix information by concatenating corresponding patch-vectors from finer resolution levels with patch-vectors of coarse levels. We call these {\em Mixed-Resolution Vectors} (MR-vectors). Unlike traditional patch-vectors that contain information from a single resolution level, MR-vectors contain more relevant information for matching. We build over our PPM algorithm by substituting MR-vectors in place of traditional patch-vectors. We call this the Mixed-Resolution Patch-Matching (MRPM) algorithm. MRPM further improves the accuracy of matches found by PPM with a marginal increase in time. It captures up-to 4\% more of the ground-truth matches (8% more than CSH) and achieves near-optimal match accuracy. We also show that the MR-approach has computational benefits over an approach which uses an increased search range. We describe the effects of changing the number of resolution levels mixed and show that a balance between accuracy and time is achieved at mixing 2 levels. We perform various experiments to compare MRPM with PPM and other previous approaches, in all of which MRPM consistently performs better. Fast parallel multi-core and GPU implementations of MRPM follow from parallel implementations of PPM. We develop applications of image denoising, image summarization and auto-crop based on our MRPM algorithm. Results with better visual quality are obtained when MR-vectors are used. The computational bottleneck of these algorithms is the search for nearest neighbors of patches. We demonstrate the utility of MRPM as a fast patch-matching engine which empowers these applications. We open up new possibilities of research to explore the scope of MR-vectors which we believe has applications in several other image editing and computer vision tasks.
| Year of completion: | December 2012 |
| Advisor : | P. J. Narayanan |
Related Publications
Harshit Surekha and P J Narayanan - Mixed-Resolution Patch-Matching Proceedings of 12th European Conference on Computer Vision, 7-13 Oct. 2012, Vol. ECCV 2012, Part-VI, LNCS 7577, pp. 187-198, Firenze, Italy. [PDF]
Downloads
![]()
![]()