Towards Large Scale Image Based Robot Navigation
Supreeth Achar (homepage)
Automatic mapping of environments and autonomous navigation are two of the central problems in mobile robotics. A number of different sensor modalities can be used to solve these problems. Vision sensors are relatively low in cost and have the potential to provide very rich information about the environment. However, active range finding sensors tend to be more widely used because interpretation of images has been a very challenging, computationally intensive task. Recent advances in computer vision algorithms and improvements in hardware capabilities have greatly increased the scope for using vision in robotics, even in unstructured, real world environments. Approaches to applying computer vision to robotics problems fall into two classes, model based approaches and image based approaches. Model based approaches use some sort of metric representation of the environment as a map. This map can be built manually and provided to the robot or it can be built automatically using visual SLAM methods. Building accurate reconstructions becomes increasingly difficult as the size of the environment increases. Image based methods for robot navigation avoid the need for metric modeling. Instead of inferring a 3D model of the environment and using this model to determine where the robot is and what is should do, image based methods work directly over images. Images of the environment captured from various positions in the environment are stored as nodes in a topological graph structure in which edges encode the connectivity between pairs of poses.
Localization is the process of determining the position of a robot from sensor readings. In an image based framework, localization entails finding a previously seen image stored in the topological graph that closely matches the current view. If such an image exists, then it can be inferred that the robot is close to the pose where the stored image was captured. In this thesis, a robot localization method is developed that builds upon bag of words techniques used in content based image retrieval. Dynamic scene elements such as pedestrians and traffic which could corrupt localization results are handled with the help of a motion detection algorithm. Prior information regarding robot pose is used in conjunction with visual word frequency distributions to assign weights to words that give higher importance to features that are more informative regarding the pose of the robot. The method was validated in a localization experiment over a six kilometer path through city roads. 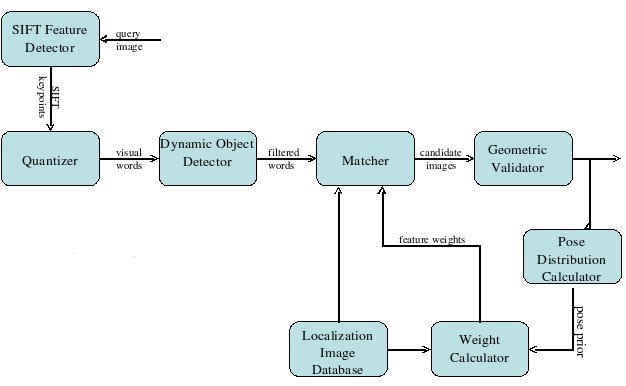
Image based methods are ideally suited to learning the rough structure and connectivity of an environment, especially detection of loop closures. Loop closures can be found using the same image retrieval based techniques that are used for localization. Loop closure detection is a major problem in SLAM because data at the end of a loop has to be associated with that at the beginning and then the entire map built by the robot needs to be updated. Chapter 3 presents a method for inferring a metric map of an environment from an appearance based topological graph representation. Building a topological graph as a preliminary step makes information regarding the connectivity of the environment available to the SLAM algorithm, making the making process significantly easier. The offline SLAM process can be visualized as an optimization over a graph. Each robot pose along the trajectory and feature in the map is represented by a node. Each edge links two nodes connected by a measurement, either a measurement of a feature position with respect to some point on the robot trajectory or an estimate of the motion between two points along the trajectory. Due to noise and modeling errors, these measurements will be inconsistent with each other. The optimization finds the a consistent trajectory and map that maximizes the log-likelihood of the measurements under assumptions of Gaussian sensor and motion model noise.
In natural outdoor environments, the deformable nature of objects can make it difficult to establish correspondences between points in two images of the same scene taken from different views. Most existing closed loop methods for controlling the position of a manipulator or robot using visual servoing require accurate feature correspondences. Chapter 4 presents a visual servoing algorithm that does away with the need for feature correspondence between the current and target views by modeling the distribution of features in an image as a mixture of Gaussians. The L2 norm of the distance between two such Gaussian mixtures can be expressed in the closed form. A control law is derived which which minimizes the distance function between the two Gaussian mixtures, causing the robot to move from its current pose to the target pose. Because the control law is defined in terms of a statistic over the feature distribution and not over the positions of the individual features, the control is robust to errors in measurement.
| Year of completion: | August 2009 |
| Advisor : | C. V. Jawahar |
Related Publications
Supreeth Achar and C. V. Jawahar - Adaptation and Learning for Image Based Navigation IEEE Sixth Indian Conference on Computer Vision, Graphics & Image Processing (ICVGIP 2008), pp. 103-110, 16-19 Dec,2008, Bhubaneswar, India. [PDF]
D. Santosh, Supreeth Achar, C.V. Jawahar - Autonomous Image-based Exploration for Mobile Robot Navigation Proceedings of the IEEE International Conference on Robotics and Automation (ICRA'2008). May 19th-23rd 2008, Pasadena California. [PDF]
A.H. Abdul Hafez, Supreeth Achar, and C. V. Jawahar - Visual Servoing based on Gaussian Mixture Models Proceedings of the IEEE International Conference on Robotics and Automation (ICRA'2008). May 19th-23rd 2008, Pasadena Californi. [PDF]
Downloads
![]()
![]()



