Multiple View Geometry Applications to Robotic and Visual Servoing
Visesh Chari (homepage)
Computer Vision may be described as the process of scene understanding through analysis of images captured by a camera. Understanding of a scene has several aspects associated with it, and this makes the field of computer vision a very vibrant and active field of research. For example, a section of the computer vision research concentrates on the understanding of the inherent characteristics of an object (identifying clauses like "this is a face", "this is a car" etc.). Yet another branch focuses on answering questions like "find the given face in this image" or "find where cars occur in this image". Another, more primitive of the branches, concerns itself with the estimation of the geometry of the scene. It answers questions like "what is the shape of this face", or "how would this car look from that viewpoint". This branch, and its various derivatives come under the name "Multiple View Geometry". Technically, Multiple View Geometry concerns itself with the geometric interaction of the 3D world with images captured by the camera, and the interpretation and manipulation of this information for various tasks. Multiple View Geometry (MVG) is two decades old in its research, and borrows heavily from a related field called Photogrammetry. Over the course of these years, many algorithms have been proposed for the estimation of geometric quantities like the transformation between cameras viewing a scene, or the 3D structure of a particular object being viewed by multiple cameras etc. The field has matured recently, with focus shifting towards producing globally optimal estimates of geometric quantities like transformations and structure, analysis of cases where the problem of geometric inference or manipulation is NP-Complete, etc. Even before maturity, many of the algorithms in Multiple View Geometry have found applications. The simple mosaicing solutions available in digital cameras these days, owes its origin to one such algorithm. Applications have also been spawned in areas like animation for films, robot motion in automated surgery and industrial environments, security systems that employ hundreds of cameras, etc.
This thesis focuses on the application front of Multiple View Geometry, which has started gaining popularity. To this extent, we leverage some of the concepts of MVG, to develop new frameworks and algorithms for a variety of problems.
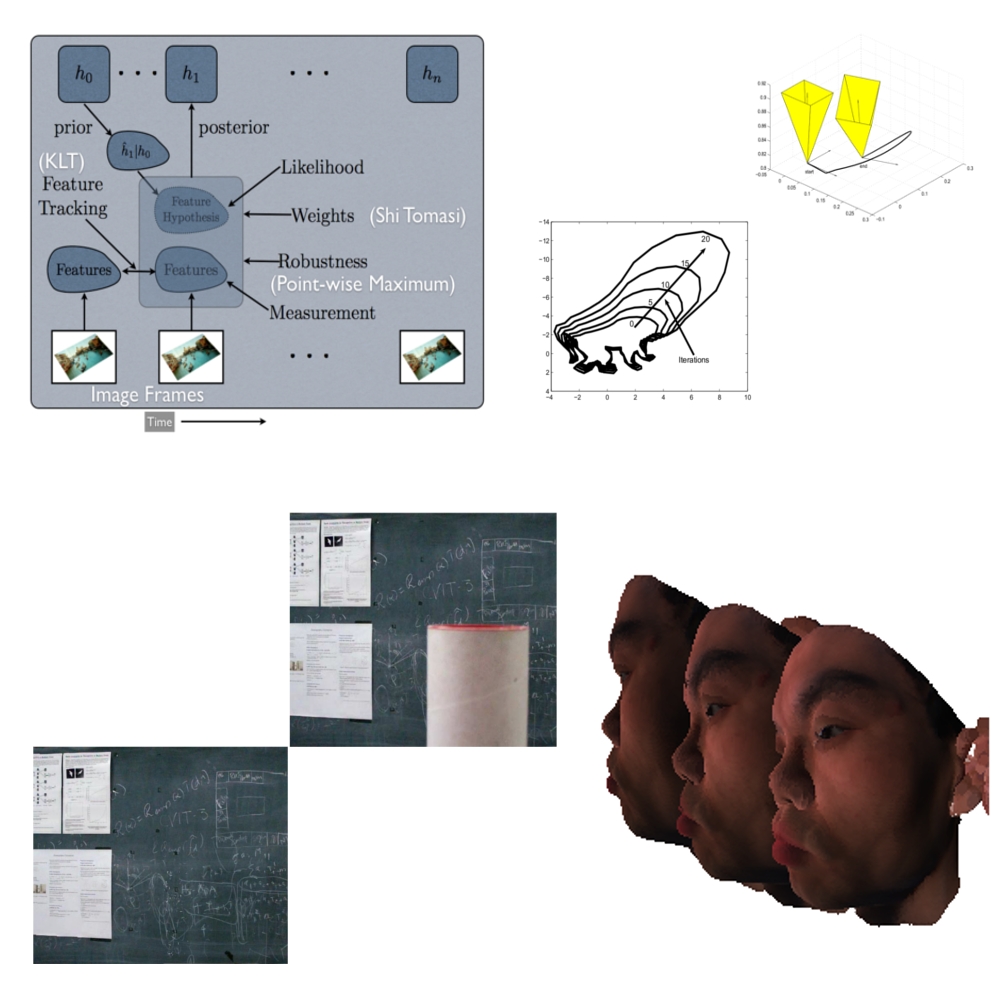
 For this reason, we choose to explore the use of MVG in various robotics and computer vision tasks in this thesis. We first propose a tracking framework that utilizes various cues like textures and edges to perform tracking of 2D and 3D objects in various views of a scene. Tracking refers to the task of estimating the location and orientation of an object with respect to a pre-defined world coordinate system. Traditionally, filters like the Kalman Filter and its variants have been used for tracking purposes. Problems like illumination change and occlusion have affected many of these algorithms that make assumptions like uniform intensity of objects across views, etc. We show that by embedding MVG into tracking algorithms, we can achieve efficient tracking of objects, that is robust to large changes in perspective, illumination and occlusion. A by-product is the estimation of the pose of the camera, which in itself is useful for tasks like localization in a mobile environment.
For this reason, we choose to explore the use of MVG in various robotics and computer vision tasks in this thesis. We first propose a tracking framework that utilizes various cues like textures and edges to perform tracking of 2D and 3D objects in various views of a scene. Tracking refers to the task of estimating the location and orientation of an object with respect to a pre-defined world coordinate system. Traditionally, filters like the Kalman Filter and its variants have been used for tracking purposes. Problems like illumination change and occlusion have affected many of these algorithms that make assumptions like uniform intensity of objects across views, etc. We show that by embedding MVG into tracking algorithms, we can achieve efficient tracking of objects, that is robust to large changes in perspective, illumination and occlusion. A by-product is the estimation of the pose of the camera, which in itself is useful for tasks like localization in a mobile environment.
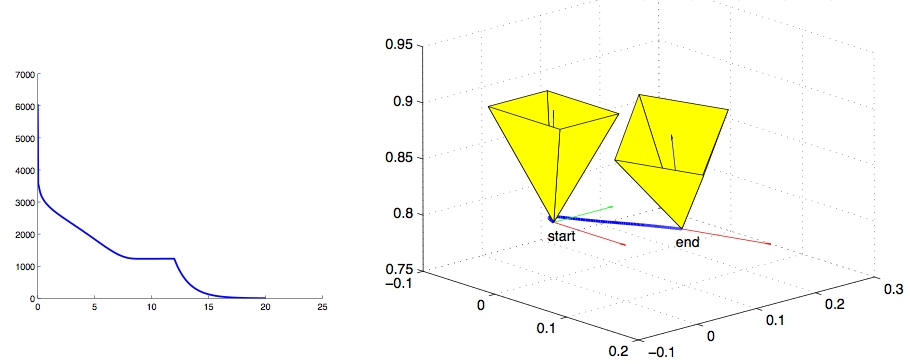 Then we show an application of frequency domain based MVG to the task of robot positioning. Positioning (or Visual Servoing) is a task that enables a robot to assume a desired pose with respect to an object of interest, with the help of a camera. This object might be a heart, as in surgery, or an automobile part, as in industrial settings. We show that by using frequency domain techniques in MVG, we can achieve algorithms that require only rough correspondence between images, unlike earlier algorithms that needed specific point-to-point correspondences. This is further developed into a general framework for servoing that is capable of straight Cartesian paths and path following, which are recent problems in servoing.
Then we show an application of frequency domain based MVG to the task of robot positioning. Positioning (or Visual Servoing) is a task that enables a robot to assume a desired pose with respect to an object of interest, with the help of a camera. This object might be a heart, as in surgery, or an automobile part, as in industrial settings. We show that by using frequency domain techniques in MVG, we can achieve algorithms that require only rough correspondence between images, unlike earlier algorithms that needed specific point-to-point correspondences. This is further developed into a general framework for servoing that is capable of straight Cartesian paths and path following, which are recent problems in servoing.
 Within computer vision, we explore the use of MVG for various image and video editing tasks. Tasks like removing a scene object from a video in a consistent manner would fall in this category (Predicting how the video would look like without the object). In this area, we propose an algorithm for video inpainting, where specific objects from a video are removed and resulting space-time holes are filled in a consistent manner. The algorithm is fully automatic unlike traditional image and video inpainting algorithms, and takes as input two functions; one function defines the object to be removed, and the other defines the background model that is used for hole-filling.
Within computer vision, we explore the use of MVG for various image and video editing tasks. Tasks like removing a scene object from a video in a consistent manner would fall in this category (Predicting how the video would look like without the object). In this area, we propose an algorithm for video inpainting, where specific objects from a video are removed and resulting space-time holes are filled in a consistent manner. The algorithm is fully automatic unlike traditional image and video inpainting algorithms, and takes as input two functions; one function defines the object to be removed, and the other defines the background model that is used for hole-filling.

We then extend this algorithim to obtain Image Extrapolation, which is concerned with prediction of the future of a scene using available content about it. This is different from Inference in the sense that no data is actually available to confirm our predictions and hence several alternatives remain equally viable. In this direction, we propose an inpainting based framework for Image Based Rendering (IBR). Image Based Rendering (IBR) concerns itself with algorithms for an image based representation of the 3D information of a scene. Novel views of the scene can then be rendered with this information. We extend IBR to include cases when 3D information about a particular scene is incomplete, by incorporating information about the type of scene being viewed (for eg. the face of a person). We then devise algorithms to transfer specific semantic characteristics to the current scene from similar scenes available to us.
Related Publications
Visesh Chari, Avinash Sharma, Anoop M Namboodiri and C.V. Jawahar - Frequency Domain Visual Servoing using Planar Contours IEEE Sixth Indian Conference on Computer Vision, Graphics & Image Processing (ICVGIP 2008), pp. 87-94, 16-19 Dec,2008, Bhubaneswar, India. [PDF]
Visesh Chari, C. V. Jawahar, P. J. Narayanan - Video Completion as Noise Removal Proceedings of National Conference on Communications (NCC'08), Feb 1-3, 2008, IIT Mumbai, India. [PDF]
Visesh Chari, Jag Mohan Singh and P. J. Narayanan - Augmented Reality using Over-Segmentation Proceedings of National Conference on Computer Vision Pattern Recognition Image Processing and Graphics (NCVPRIPG'08),Jan 11-13, 2008, DA-IICT, Gandhinagar, India. [PDF]
A.H. Abdul Hafez, Visesh Chari and C.V. Jawahar - Combining Texture and Edge Planar Tracker based on a local Quality Metric Proc. of IEEE International Conference on Robotics and Automation(ICRA'07), Roma, Italy, 2007. [ PDF ]
Downloads