Scalable Primitives for Data Mapping and Movement on the GPU
Suryakant Patidar (homepage)
 GPUs have been used increasingly for a wide range of problems involving heavy computations in graphics, computer vision, scientific processing, etc. One of the key aspects for their wide acceptance is the high performance to cost ratio. In less than a decade, GPUs have grown from non-programmable graphics co-processors to a general-purpose unit with a high level language interface that delivers 1 TFLOPs for $400. GPU's architecture including the core layout, memory, scheduling, etc. is largely hidden. It also changes more frequently than the single core and multi core CPU architecture. This makes it difficult to extract good performance for non-expert users. Suboptimal implementations can pay severe performance penalties on the GPU. This is likely to persist as many-core architectures and massively multithreaded programming models gain popularity in the future.
GPUs have been used increasingly for a wide range of problems involving heavy computations in graphics, computer vision, scientific processing, etc. One of the key aspects for their wide acceptance is the high performance to cost ratio. In less than a decade, GPUs have grown from non-programmable graphics co-processors to a general-purpose unit with a high level language interface that delivers 1 TFLOPs for $400. GPU's architecture including the core layout, memory, scheduling, etc. is largely hidden. It also changes more frequently than the single core and multi core CPU architecture. This makes it difficult to extract good performance for non-expert users. Suboptimal implementations can pay severe performance penalties on the GPU. This is likely to persist as many-core architectures and massively multithreaded programming models gain popularity in the future.
 One way to exploit the GPU's computing power effectively is through high level primitives upon which other computations can be built. All architecture specific optimizations can be incorporated into the primitives by designing and implementing them carefully. Data parallel primitives play the role of building blocks to many other algorithms on the fundamentally SIMD architecture of the GPU. Operations like sorting, searching etc., have been implemented for large data sets.
One way to exploit the GPU's computing power effectively is through high level primitives upon which other computations can be built. All architecture specific optimizations can be incorporated into the primitives by designing and implementing them carefully. Data parallel primitives play the role of building blocks to many other algorithms on the fundamentally SIMD architecture of the GPU. Operations like sorting, searching etc., have been implemented for large data sets.
We present efficient implementations of a few primitives for data mapping and data distribution on the massively multi-threaded architecture of the GPU. The split primitive distributes elements of a list according to their category. Split is an important operation for data mapping and is used to build data structures, distribute work load, performing database join queries etc. Simultaneous operations on a common memory is the main problem for parallel split and other applications on the GPU. He et al. overcame the problem of simultaneous writes by using personal memory space for each parallel thread on the GPU. Limited small shared memory available limits the maximum number of categories they can handle to 64. We use hardware atomic operations for split and propose ordered atomic operations for stable split which maintains the original order for elements belonging to the same category. Due to limited shared memory, such a split can only be performed to maximum of 2048 bins in a single pass. For number of bins higher than that, we propose an Iterative Split approach which can handle billions of bins using multiple passes of stable split operation by using an efficient basic split which splits the data to fixed number of categories. We also present a variant of split that partitions the  indexes of records. This facilitates the use of the GPU as a co-processor for split or sort, with the actual data movement handled separately. We can compute the split indexes for a list of 32 million records in 180 milliseconds for a 32-bit key and in 800 ms for a 96-bit key.
indexes of records. This facilitates the use of the GPU as a co-processor for split or sort, with the actual data movement handled separately. We can compute the split indexes for a list of 32 million records in 180 milliseconds for a 32-bit key and in 800 ms for a 96-bit key.
The gather and scatter primitive performs fast, distributed data movement. Efficient data movement is critical to high performance on the GPUs as suboptimal memory accesses can pay heavy penalties. In spite of high-bandwidth (130 GBps) offered by the current GPUs, naive implementation of the above operations hampers the performance and can only utilize a part of the bandwidth. The {\em instantaneous locality of memory reference} play a critical role in data movement on the current GPU memory architectures. For scatter and gather involving large records, we use collective data movement in which multiple threads cooperate on individual records to improve the instantaneous locality. We use multiple threads to move bytes of a record, maximizing the coalesced memory access. Our implementation of gather and scatter operations efficiently moves multi element records on the GPU. These data movement primitives can be used in conjunction with split for splitting of large records on the GPU.
We extend the split primitive to devide a SplitSort algorithm that can sort 32-bit, 64-bit and 128-bit integers on the GPU. The performance of SplitSort is faster than the best GPU sort available today by Satish et al for 32 bit integers. To our knowledge we are the first to present results on sorting 64-bits and higher integers on the GPU. With split and gather operations we can sort large data records by first sorting their indexes and then moving the original data efficiently. We show sorting of 16 million 128-byte records in 379 milliseconds with 4-byte keys and in 556 ms with 8-byte keys.
Using our fast split primitive, we explore the problem of real time ray casting of large deformable models (over a million triangles) on large displays (a million pixels) on an on-the-shelf GPU. We build a GPU-efficient three dimensional data structure for this purpose and a corresponding algorithm that uses it for fast ray casting. The data structure provides us with blocks of pixels and their corresponding geometry in a list of cells. Thus, each block of pixels can work in parallel on the GPU contributing a region of output to the final image. Our algorithm builds the data structure rapidly using the split operation for each frame (5 milliseconds for 1 million triangles) and can thus support deforming geometry by rebuilding the data structure every frame. Early work on ray tracing by Purcell et al built the data structures once on the CPU and used the GPU for repeated ray tracing using the data structure. Recent work on ray tracing of deformable objects by Lauterbach et al handles light models with upto 200K triangles at 7-10 fps. We achieve real-time rates (25 fps) for ray-casting a million triangle model onto a million pixels on current Nvidia GPUs.
Primitives we proposed are widely used and our results show that their performance scales logarithmically with the number of categories, linearly with the list length, and linearly with the number of cores on the GPU. This makes it useful for applications that deal with large data sets. The ideas presented in the thesis are likely to extend to later models and architectures of the GPU as well as to other multi core architectures. Our implementation for the data primitives viz. split, sort, gather, scatter and their combinations are expected to be widely used by future GPU programmers. A recent algorithm by Vineet et al. computes the minimum spanning tree on large graphs used the split primitive to improve the performance.
| Year of completion: | June 2009 |
| Advisor : | P. J. Narayanan |
Related Publications
Vibhav Vineet, Pawan Harish, Suryakanth Patidar and P. J. Narayanan - Fast Minimum Spanning Tree for Large Graphs on the GPU Proceedings of High-Performance Graphics (HPG 09), 1-3 August, 2009, Louisiana, USA. [PDF]
Shiben Bhattacharjee, Suryakanth Patidar and P. J. Narayanan - Real-time Rendering and Manipulation of Large Terrains IEEE Sixth Indian Conference on Computer Vision, Graphics & Image Processing (ICVGIP 2008), pp. 551-559, 16-19 Dec,2008, Bhubaneswar, India. [PDF]
Suryakanth Patidar and P.J. Narayanan - Ray Casting Deformable Model on the GPU IEEE Sixth Indian Conference on Computer Vision, Graphics & Image Processing (ICVGIP 2008), pp. 481-488, 16-19 Dec,2008, Bhubaneswar, India. [PDF]
Soumyajit Deb, Shiben Bhattacharjee, Suryakant Patidar and P. J. Narayanan - Real-time Streaming and Rendering of Terrains, 5th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Madurai, India, LNCS 4338 pp.276-288, 2006. [PDF]
- Suryakant Patidar, P. J. Narayanan - Scalable Split and Sort Primitives using Ordered Atomic Operations on the GPU, High Performance Graphics (Poster), April 2009. [PDF]
- Kishore K, Rishabh M, Suhail Rehman, P. J. Narayanan, Kannan S, Suryakant Patidar - A Performance Prediction Model for th e CUDA GPGPU Platform. International Conference on High Performance Computing, April 2009. [PDF]
- Suryakant Patidar, Shiben Bhattacharjee, Jag Mohan Singh, P. J. Narayanan - Exploiting the Shader Model 4.0 Architecture, IIIT/TR/2007/145, March 2007. [PDF]
Downloads
![]()
![]()



 Traditional CBIR systems find relevant images by finding nearest neighbors in a high dimensional feature space. This is computationally expensive, and does not scale as the number of images in the database grow. We address this problem by posing the image retrieval problem as a text retrieval task. We do this by transforming the images into
Traditional CBIR systems find relevant images by finding nearest neighbors in a high dimensional feature space. This is computationally expensive, and does not scale as the number of images in the database grow. We address this problem by posing the image retrieval problem as a text retrieval task. We do this by transforming the images into  Contemporary bag of visual words approaches to image retrieval perform one-time offline vector quantization to create the visual vocabulary. However, these methods do not adapt well to dynamic image databases whose nature constantly changes as new data is added. In this thesis, we design, present and examine with experiments a novel method for incremental vector quantization(IVQ) to be used in image and video retrieval systems with dynamic databases.
Contemporary bag of visual words approaches to image retrieval perform one-time offline vector quantization to create the visual vocabulary. However, these methods do not adapt well to dynamic image databases whose nature constantly changes as new data is added. In this thesis, we design, present and examine with experiments a novel method for incremental vector quantization(IVQ) to be used in image and video retrieval systems with dynamic databases.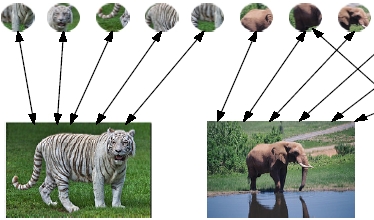 Semantic indexing
Semantic indexing 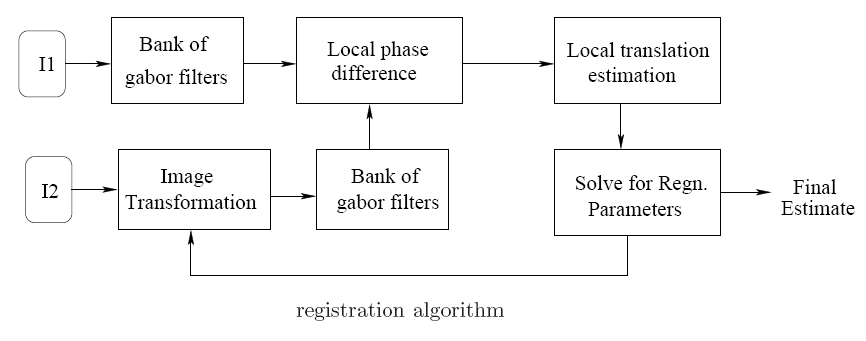
 We explore an alternate solution to the problem of robustness in the registration step of a SR algorithm. We present an accurate registration algorithm that uses the local phase information, which is robust to the above degradations. The registration step is formulated as optimization of the local phase alignment at various spatial frequencies. We derive the theoretical error rate of the estimates in presence of non-ideal band-pass behavior of the filter and show that the error converges to zero over iterations. We also show the invariance of local phase to a class of blur kernels. Experimental results on images taken under varying conditions are demonstrated.
We explore an alternate solution to the problem of robustness in the registration step of a SR algorithm. We present an accurate registration algorithm that uses the local phase information, which is robust to the above degradations. The registration step is formulated as optimization of the local phase alignment at various spatial frequencies. We derive the theoretical error rate of the estimates in presence of non-ideal band-pass behavior of the filter and show that the error converges to zero over iterations. We also show the invariance of local phase to a class of blur kernels. Experimental results on images taken under varying conditions are demonstrated. Recently, Lin and Shum has shown an upper limit on multi-frame SR techniques. For practical purposes this limit is very small. Another class of SR algorithms formulate the high-quality image generation as an inference problem. High-resolution image is inferred from a set of learned training patches. This class of algorithm works well for natural structures but for many man-made structures this technique does not produce accurate results. We propose to capture the images at optimal zoom from the perspective of image super-resolution. The images captured at this zoom has sufficient amount of information so that it can be magnified further by using any SR algorithm which promotes step edges and certain features. This can have a variety of applications in consumer cameras, large-scale automated image mosaicing, robotics and improving the recognition accuracy of many computer vision algorithms. Existing efforts are limited to image a pre-determined object at the right zoom. In the proposed approach, we learn the patch structures at various down-sampling factors. To further enhance the output we impose the local context around the patch in a MRF framework. Several constraints are introduced to minimize the extent of zoom-in.
Recently, Lin and Shum has shown an upper limit on multi-frame SR techniques. For practical purposes this limit is very small. Another class of SR algorithms formulate the high-quality image generation as an inference problem. High-resolution image is inferred from a set of learned training patches. This class of algorithm works well for natural structures but for many man-made structures this technique does not produce accurate results. We propose to capture the images at optimal zoom from the perspective of image super-resolution. The images captured at this zoom has sufficient amount of information so that it can be magnified further by using any SR algorithm which promotes step edges and certain features. This can have a variety of applications in consumer cameras, large-scale automated image mosaicing, robotics and improving the recognition accuracy of many computer vision algorithms. Existing efforts are limited to image a pre-determined object at the right zoom. In the proposed approach, we learn the patch structures at various down-sampling factors. To further enhance the output we impose the local context around the patch in a MRF framework. Several constraints are introduced to minimize the extent of zoom-in.