DeepHuMS: Deep Human Action Signature for3D Skeletal Sequences
Abstract:
3D Human Action Indexing and Retrieval is an interesting problem due to the rise of several data-driven applications aimed atanalyzing and/or reutilizing 3D human skeletal data, such as data-driven animation, analysis of sports bio-mechanics, human surveillance etc. Spatio-temporal articulations of humans, noisy/missing data, different speeds of the same action etc. make it challenging and several of the existing state of the art methods use hand-craft features along with optimization based or histogram based comparison in order to perform retrieval. Further, they demonstrate it only for very small datasets and few classes. We make a case for using a learned representation that should recognize the action as well as enforce a discriminative ranking. To that end, we propose, a 3D human action descriptor learned using a deep network. Our learned embedding is generalizable and applicable toreal-world data - addressing the aforementioned challenges and further enables sub-action searching in its embedding space using another network. Our model exploits the inter-class similarity using trajectory cues,and performs far superior in a self-supervised setting. State of the art results on all these fronts is shown on two large scale 3D human action datasets - NTU RGB+D and HDM05.
Method
In this paper, we attempt to solve the problem of indexing and retrieval of 3D skeletal videos. In order to build a 3D human action descriptor, we need to exploit the spatio-temporal features in the skeletal action data. Briefly, we have three key components - (i) the input skeletal location and joint level action trajectories to thenext frame, (ii) an RNN to model this temporal data and (iii) a novel trajectorybased similarity metric (explained below) to project similar content togetherusing a Siamese architecture. We use two setups to train our model - (a) self-supervised, with a ”contrastive loss” to train our Siamesemodel and (b) supervised setup, with a cross entropy on our embedding, in addition to the self-supervision.
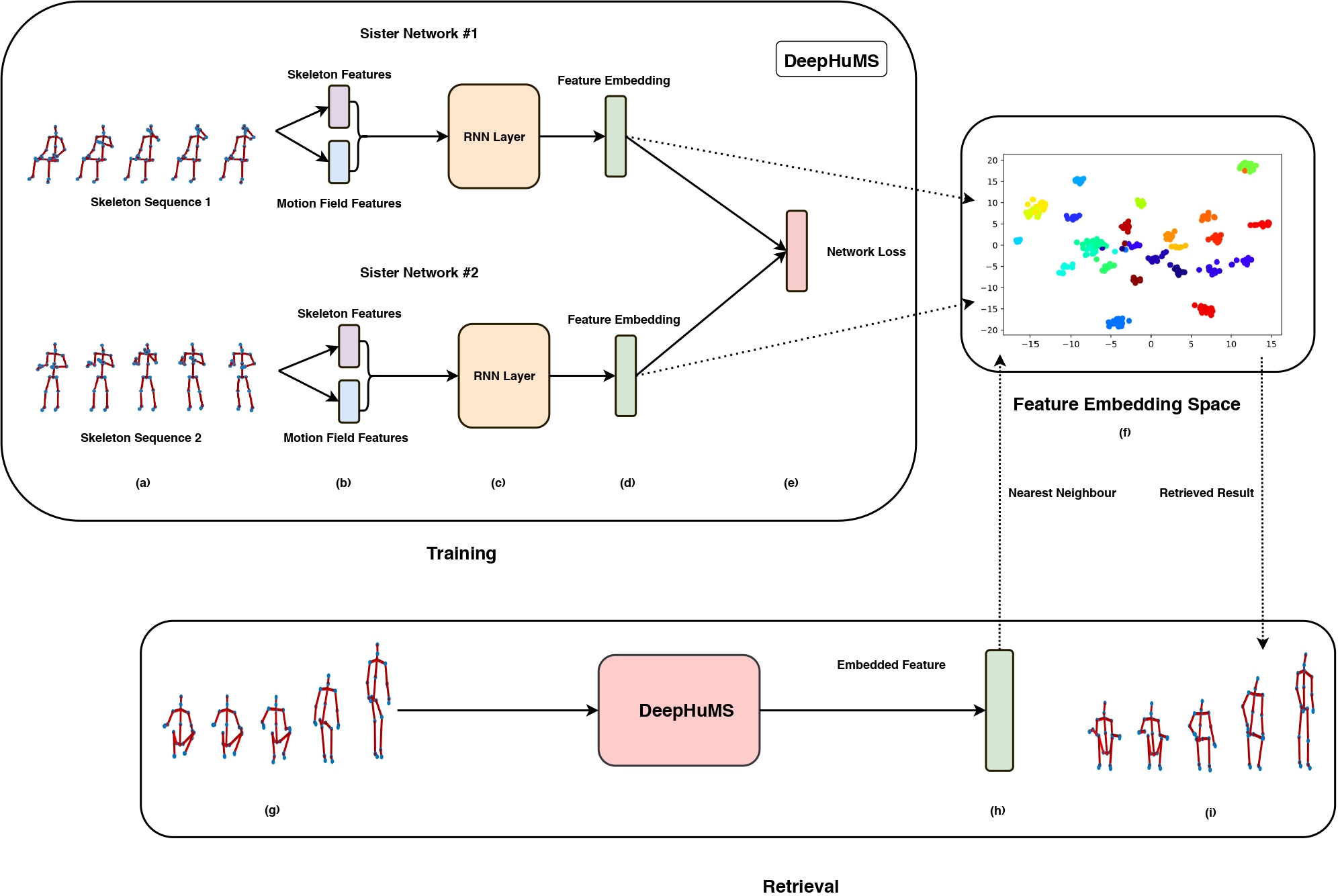
Contributions:
- We propose a novel deep learning model that makes use of trajectory cues,and optionally class labels, in order to build a discriminative and robust 3Dhuman action descriptor for retrieval.
- Further, we perform sub-action search by learning a mapping from sub-sequences to longer sequences in the dataset by means of another network.
- Experiments are performed, both, with and without class label supervision. We demonstrate our model’s ability to exploit the inter-class action similarity better in the unsupervised setting, thus, resulting in a more generalized solution.
- Our model is learned on noisy/missing data as well as actions of different speeds and its robustness in such scenarios indicates its applicability to real world data.
- A comparison of our retrieval performance with the publicly available stat eof the art in 3D action recognition as well as 3D action retrieval on two largescale publicly available datasets is done to demonstrate the state-of-the-art results of the proposed model.