Towards Speech to Sign Language Generation
Parul Kapoor, Rudrabha Mukhopadhyay Sindhu B Hegde , Vinay Namboodiri and C.V. Jawahar
IIT Kanpur IIIT Hyderabad Univ. of Bath
[ Code ] | [ Demo Video ] | [ Dataset ]
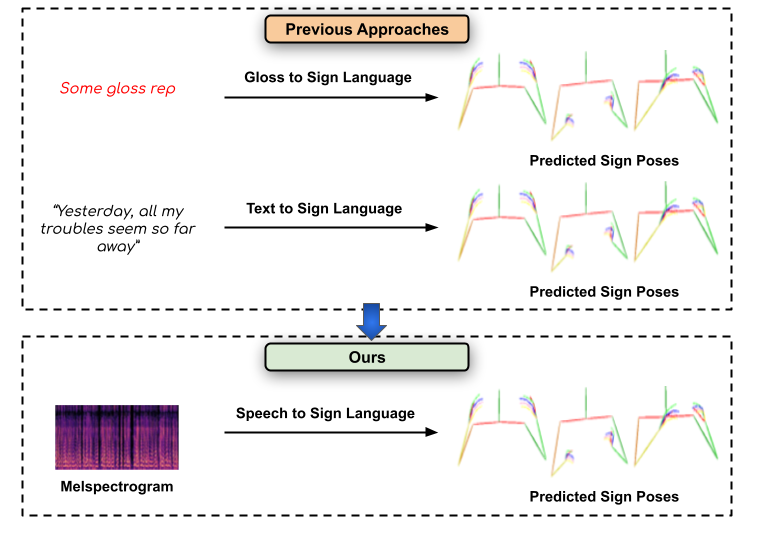
Previous approaches have only attempted to generate sign-language from the text level, we focus on directly converting speech segments into sign-language. Our work opens up several assistive technology applications and can help effectively communicate with people suffering from hearing loss.
Abstract
We aim to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss. Therefore, we eliminate the need of using text as input and design techniques that work for more natural, continuous, freely uttered speech covering an extensive vocabulary. Since the current datasets are inadequate for generating sign language directly from speech, we collect and release the first Indian sign language dataset comprising speech-level annotations, text transcripts, and the corresponding sign-language videos. Next, we propose a multi-tasking transformer network trained to generate signer's poses from speech segments. With speech-to-text as an auxiliary task and an additional cross-modal discriminator, our model learns to generate continuous sign pose sequences in an end-to-end manner. Extensive experiments and comparisons with other baselines demonstrate the effectiveness of our approach. We also conduct additional ablation studies to analyze the effect of different modules of our network. A demo video containing several results is attached to the supplementary material.
Paper

Demo
--- COMING SOON ---
Dataset
--- COMING SOON ---
Contact
- Parul Kapoor -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Rudrabha Mukhopadhyay -
This email address is being protected from spambots. You need JavaScript enabled to view it. - Sindhu Hegde -
This email address is being protected from spambots. You need JavaScript enabled to view it.